

Agentic AI techniques sit on high of enormous language fashions and hook up with instruments, reminiscence, and exterior environments. They already help scientific discovery, software program improvement, and medical analysis, but they nonetheless battle with unreliable instrument use, weak lengthy horizon planning, and poor generalization. The most recent analysis paper ‘Adaptation of Agentic AI‘ from Stanford, Harvard, UC Berkeley, Caltech proposes a unified view of how these techniques ought to adapt and maps current strategies right into a compact, mathematically outlined framework.
How this analysis paper fashions an agentic AI system?
The analysis survey fashions an agentic AI system as a basis mannequin agent together with 3 key parts. A planning module decomposes targets into sequences of actions, utilizing static procedures similar to Chain-of-Thought and Tree-of-Thought, or dynamic procedures similar to ReAct and Reflexion that react to suggestions. A instrument use module connects the agent to net serps, APIs, code execution environments, Mannequin Context Protocols, and browser automation. A reminiscence module shops quick time period context and long run data, accessed by means of retrieval augmented technology. Adaptation adjustments prompts or parameters for these parts utilizing supervised positive tuning, choice based mostly strategies similar to Direct Desire Optimization, reinforcement studying strategies similar to Proximal Coverage Optimization and Group Relative Coverage Optimization, and parameter environment friendly methods similar to low rank adaptation.
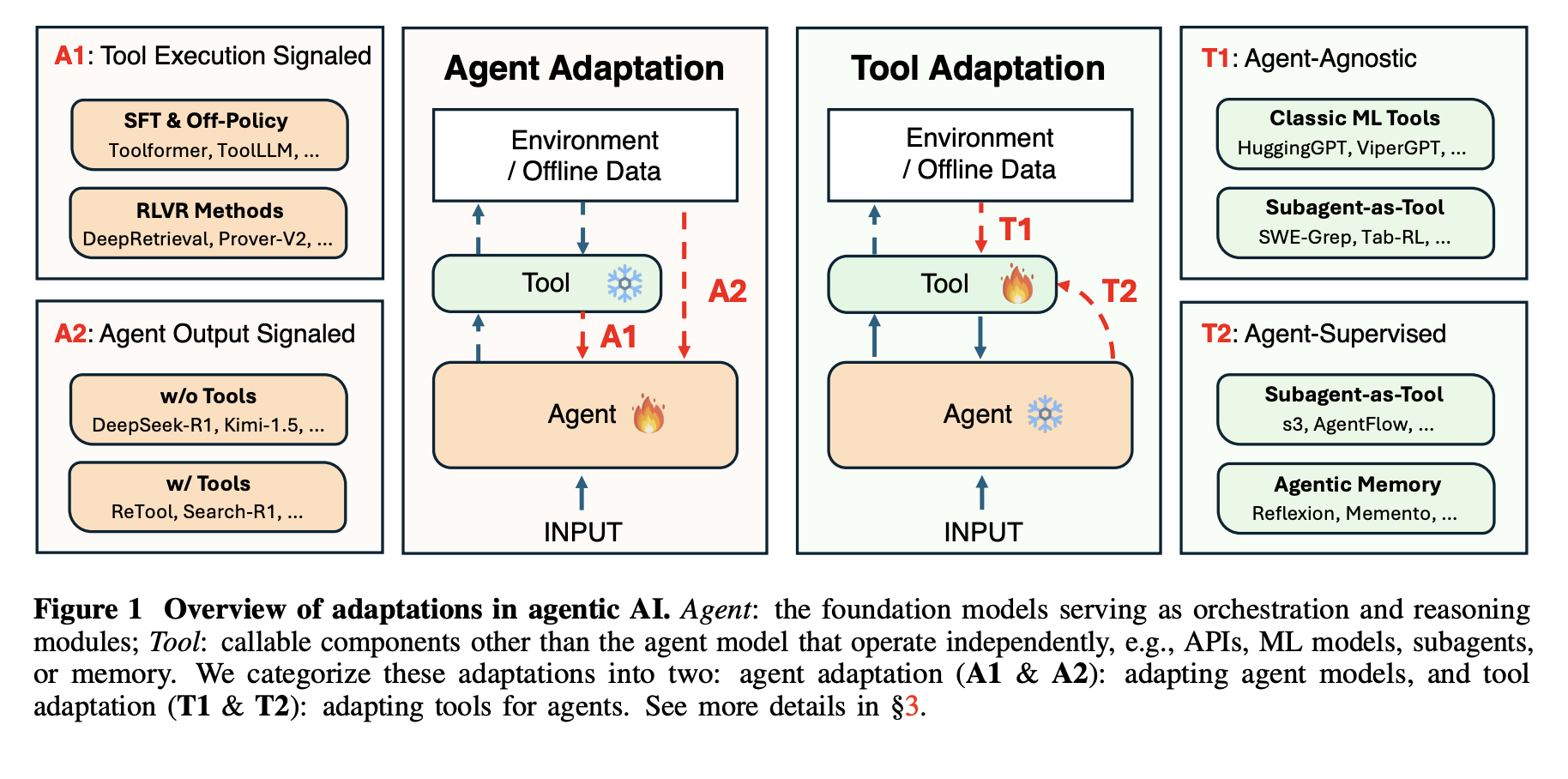
4 adaptation paradigms
The framework defines 4 adaptation paradigms by combining 2 binary decisions. The primary dimension is the goal, agent adaptation versus instrument adaptation. The second dimension is the supervision sign, instrument execution versus agent output. This yields A1 and A2 for adapting the agent, and T1 and T2 for adapting instruments.
A1, Instrument Execution Signaled Agent Adaptation, optimizes the agent utilizing suggestions derived from instrument execution. A2, Agent Output Signaled Agent Adaptation, optimizes the agent utilizing a sign outlined solely on its last outputs. T1, Agent-Agnostic Instrument Adaptation, optimizes instruments with out referring to a selected agent. T2, Agent-Supervised Instrument Adaptation, optimizes instruments beneath supervision from a set agent.
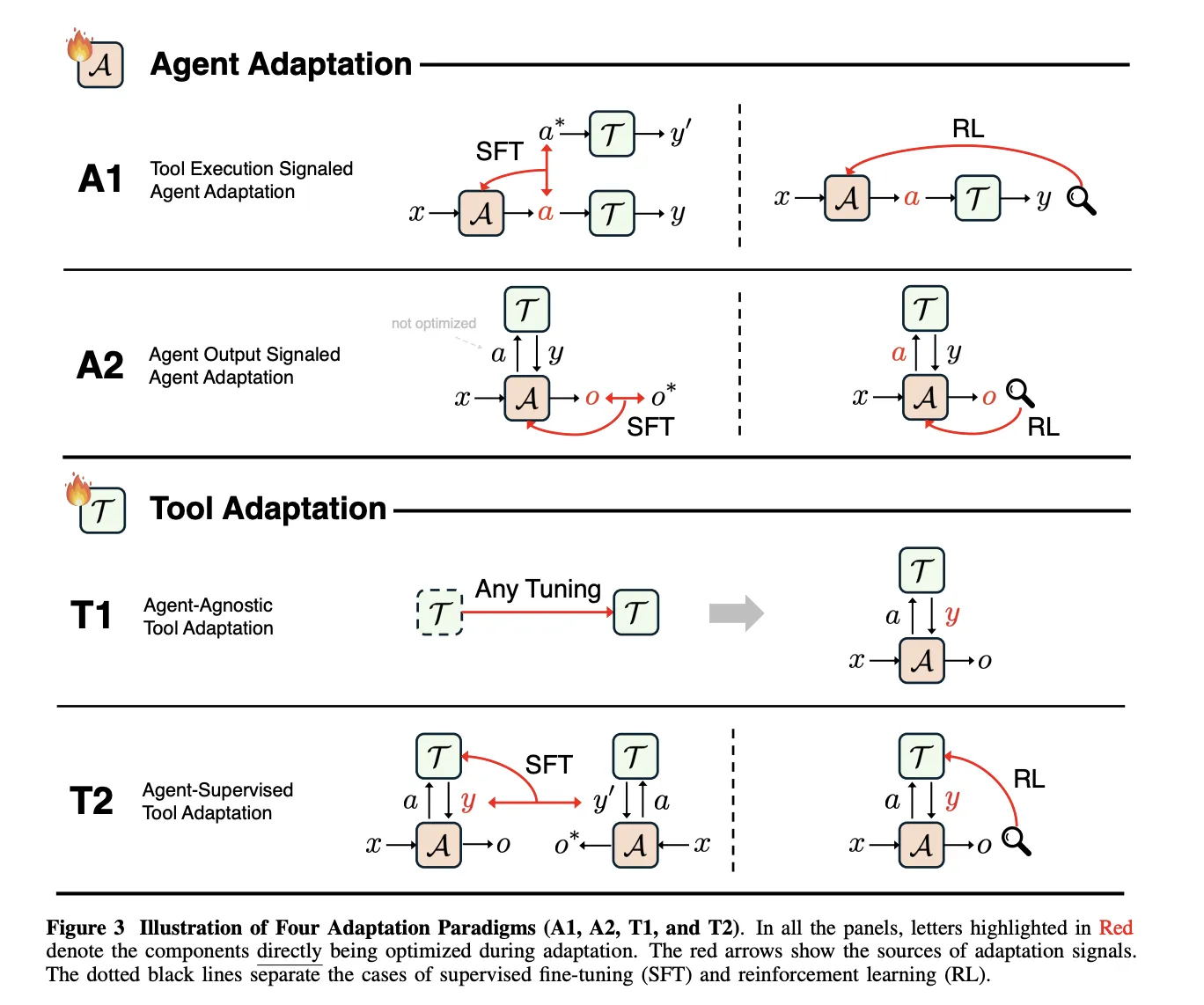
A1, studying from verifiable instrument suggestions
In A1, the agent receives an enter x, produces a structured instrument name a, the instruments return a end result y, and the training goal O_tool measures instrument success, for instance execution correctness or retrieval high quality. The paper covers each supervised imitation of profitable instrument trajectories and reinforcement studying that makes use of verifiable instrument outcomes as reward.
Toolformer, ToolAlpaca, and Gorilla illustrate supervised A1 strategies, since every makes use of execution outcomes of actual instruments to assemble or filter coaching traces earlier than imitation. All of them maintain the supervision sign outlined on the instrument conduct stage, not on the last reply stage.
DeepRetrieval is a central A1 reinforcement studying instance. It frames question reformulation as a Markov determination course of the place the state is the person question, the motion is a rewritten question, and the reward combines retrieval metrics similar to Recall and nDCG, a format time period, and, for textual content to SQL, SQL execution accuracy. The coverage is educated with KL regularized Proximal Coverage Optimization and the identical goal covers literature search, corpus query answering, and textual content to SQL.
A2, studying from last agent outputs
A2 covers circumstances the place the optimization goal O_agent relies upon solely on the ultimate output o produced by the agent, even when the agent makes use of instruments internally. The survey exhibits that supervising solely o just isn’t sufficient to show instruments, as a result of the agent can ignore instruments and nonetheless enhance probability. Efficient A2 techniques subsequently mix supervision on instrument calls with supervision on last solutions, or assign sparse rewards similar to precise match accuracy to o and propagate them again by means of the total trajectory.
T1, agent agnostic instrument coaching
T1 freezes the principle agent and optimizes instruments in order that they’re broadly reusable. The target O_tool relies upon solely on instrument outputs and is measured by metrics similar to retrieval accuracy, rating high quality, simulation constancy, or downstream job success. A1 educated search insurance policies, similar to DeepRetrieval, can later be reused as T1 instruments inside new agentic techniques with out modifying the principle agent.
T2, instruments optimized beneath a frozen agent
T2 assumes a strong however mounted agent A, which is widespread when the agent is a closed supply basis mannequin. The instrument executes calls and returns outcomes that the agent then makes use of to supply o. The optimization goal once more lives on O_agent, however the trainable parameters belong to the instrument. The paper describes high quality weighted coaching, goal based mostly coaching, and reinforcement studying variants that every one derive studying indicators for the instrument from the ultimate agent outputs.
The survey treats long run reminiscence as a particular case of T2. Reminiscence is an exterior retailer written and skim by means of discovered features, and the agent stays frozen. Latest T2 techniques embrace s3, which trains a 7 billion parameter searcher that maximizes a Acquire Past RAG reward outlined by a frozen generator, and AgentFlow, which trains a planner to orchestrate principally frozen Qwen2.5 based mostly modules utilizing Stream GRPO.
Key Takeaways
- The analysis defines a exact 4 paradigm framework for adapting agentic AI by crossing 2 dimensions, whether or not adaptation targets the agent or instruments, and whether or not the supervision sign comes from instrument execution or from last agent outputs.
- A1 strategies similar to Toolformer, ToolAlpaca, Gorilla, and DeepRetrieval adapt the agent immediately from verifiable instrument suggestions, together with retrieval metrics, SQL execution accuracy, and code execution outcomes, typically optimized with KL regularized Proximal Coverage Optimization.
- A2 strategies optimize the agent from indicators on last outputs, for instance reply accuracy, and the paper exhibits that techniques should nonetheless supervise instrument calls or propagate sparse rewards by means of full trajectories, in any other case the agent can ignore instruments whereas nonetheless enhancing probability.
- T1 and T2 shift studying to instruments and reminiscence, T1 trains typically helpful retrievers, searchers, and simulators and not using a particular agent in thoughts, whereas T2 adapts instruments beneath a frozen agent, as in s3 and AgentFlow the place a set generator supervises a discovered searcher and planner.
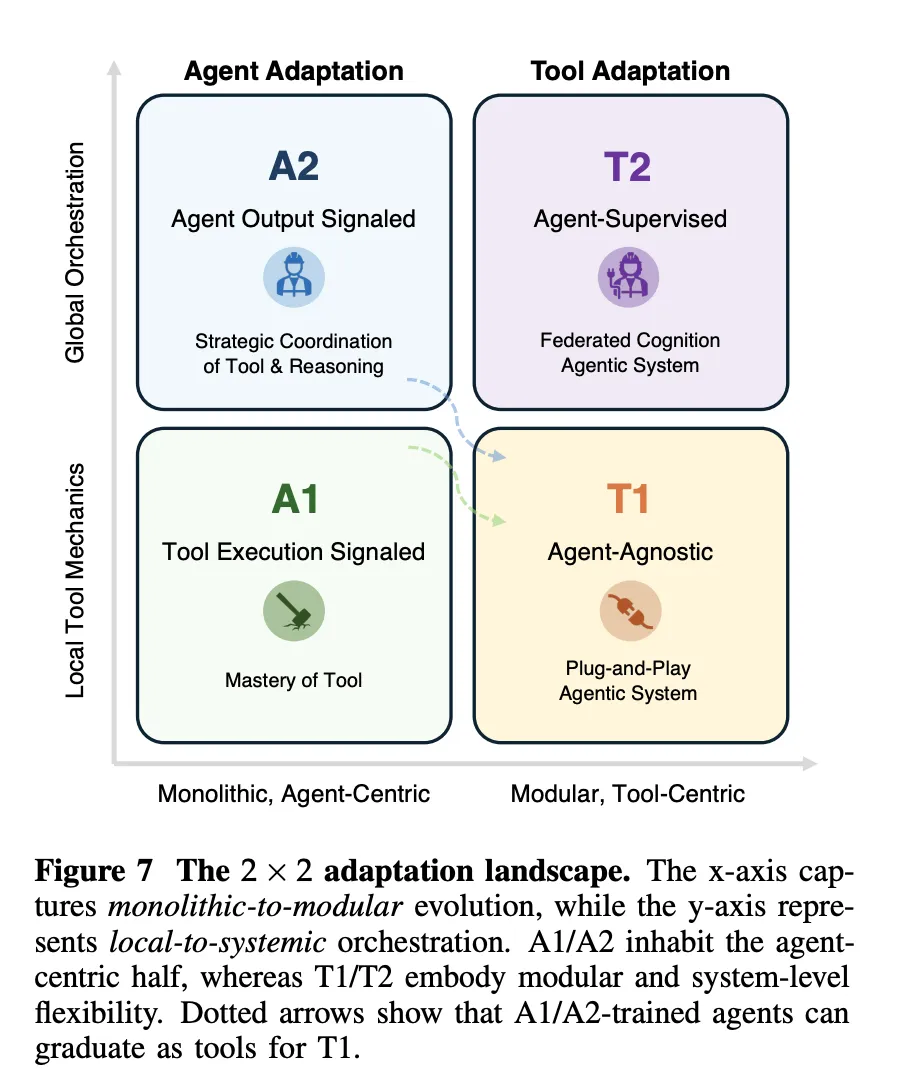
- The analysis group introduce an adaptation panorama that relates monolithic versus modular and native versus systemic management, and so they argue that sensible techniques will mix uncommon A1 or A2 updates on a robust base mannequin with frequent T1 and T2 adaptation of retrievers, search insurance policies, simulators, and reminiscence for robustness and scalability.
Try the Paper and GitHub Repo. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as effectively.

Michal Sutter is a knowledge science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at reworking advanced datasets into actionable insights.

