
Picture by Freepik
Language fashions have revolutionized the sphere of pure language processing. Whereas massive fashions like GPT-3 have grabbed headlines, small language fashions are additionally advantageous and accessible for numerous functions. On this article, we are going to discover the significance and use instances of small language fashions with all of the implementation steps intimately.
Small language fashions are compact variations of their bigger counterparts. They provide a number of benefits. Among the benefits are as follows:
- Effectivity: In comparison with massive fashions, small fashions require much less computational energy, making them appropriate for environments with constrained assets.
- Velocity: They will do the computation quicker, corresponding to producing the texts primarily based on given enter extra shortly, making them splendid for real-time functions the place you’ll be able to have excessive every day visitors.
- Customization: You may fine-tune small fashions primarily based in your necessities for domain-specific duties.
- Privateness: Smaller fashions can be utilized with out exterior servers, which ensures information privateness and integrity.
Picture by Creator
A number of use instances for small language fashions embrace chatbots, content material technology, sentiment evaluation, question-answering, and lots of extra.
Earlier than we begin deep diving into the working of small language fashions, it’s worthwhile to arrange your atmosphere, which entails putting in the required libraries and dependencies. Choosing the proper frameworks and libraries to construct a language mannequin in your native CPU turns into essential. Widespread selections embrace Python-based libraries like TensorFlow and PyTorch. These frameworks present many pre-built instruments and assets for machine studying and deep learning-based functions.
Putting in Required Libraries
On this step, we are going to set up the “llama-cpp-python” and ctransformers library to introduce you to small language fashions. You need to open your terminal and run the next instructions to put in it. Whereas working the next instructions, guarantee you might have Python and pip put in in your system.
pip set up llama-cpp-python
pip set up ctransformers -q
Output:
Now that our surroundings is prepared, we will get a pre-trained small language mannequin for native use. For a small language mannequin, we will contemplate easier architectures like LSTM or GRU, that are computationally much less intensive than extra advanced fashions like transformers. You too can use pre-trained phrase embeddings to boost your mannequin’s efficiency whereas lowering the coaching time. However for fast working, we are going to obtain a pre-trained mannequin from the online.
Downloading a Pre-trained Mannequin
You’ll find pretrained small language fashions on platforms like Hugging Face (https://huggingface.co/fashions). Here’s a fast tour of the web site, the place you’ll be able to simply observe the sequences of fashions offered, which you’ll be able to obtain simply by logging into the applying as these are open-source.
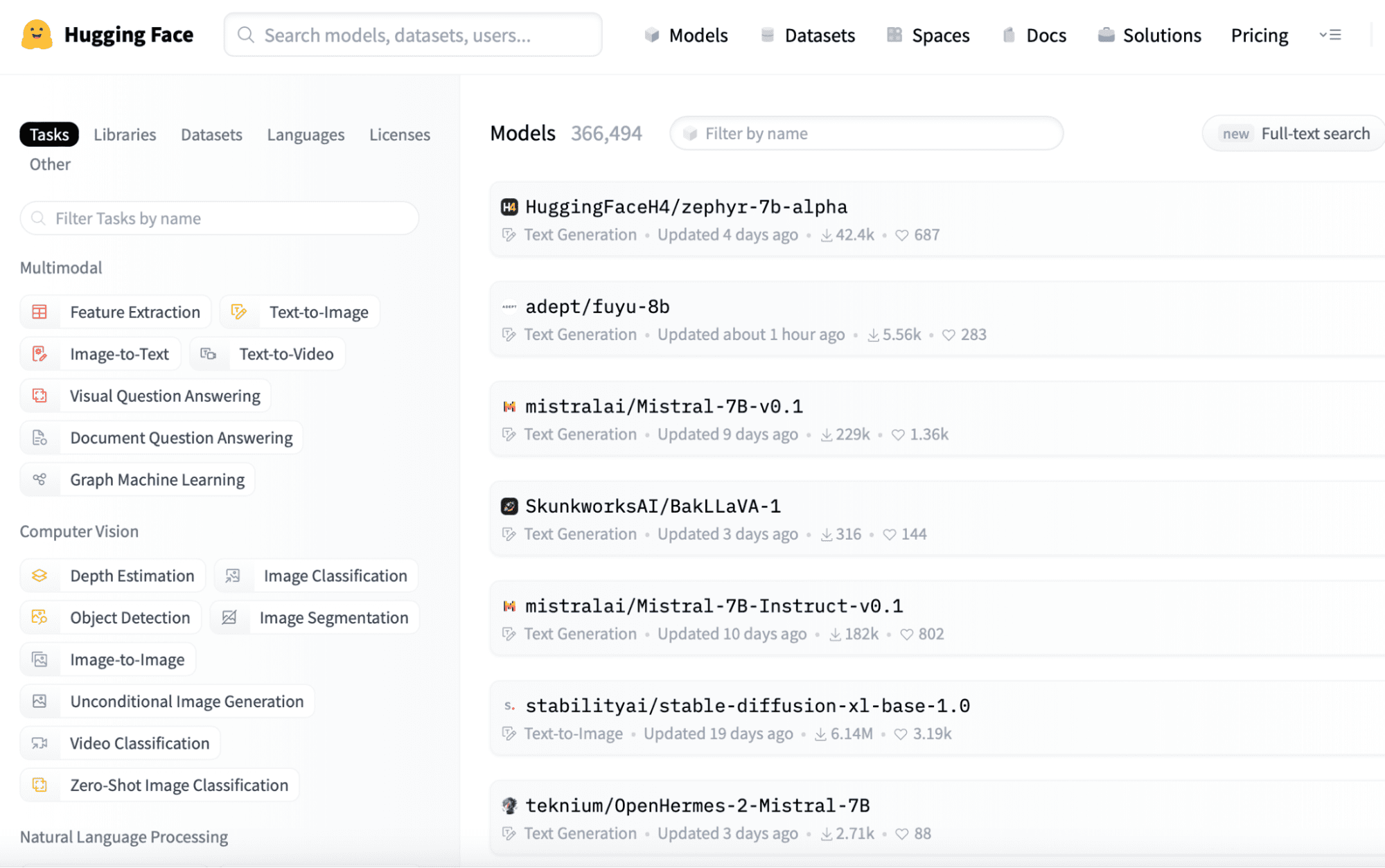
You may simply obtain the mannequin you want from this hyperlink and reserve it to your native listing for additional use.
from ctransformers import AutoModelForCausalLM
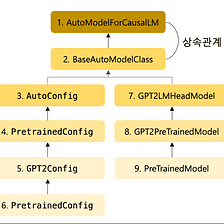
Within the above step, we now have finalized the pre-trained mannequin from Hugging Face. Now, we will use that mannequin by loading it into our surroundings. We import the AutoModelForCausalLM class from the ctransformers library within the code under. This class can be utilized for loading and dealing with fashions for causal language modeling.
Picture from Medium
# Load the pretrained mannequin
llm = AutoModelForCausalLM.from_pretrained('TheBloke/Llama-2-7B-Chat-GGML', model_file="llama-2-7b-chat.ggmlv3.q4_K_S.bin" )
Output:
Small language fashions will be fine-tuned primarily based in your particular wants. If it’s a must to use these fashions in real-life functions, the primary factor to recollect is effectivity and scalability. So, to make the small language fashions environment friendly in comparison with massive language fashions, you’ll be able to regulate the context dimension and batching(partition information into smaller batches for quicker computation), which additionally leads to overcoming the scalability drawback.
Modifying Context Measurement
The context dimension determines how a lot textual content the mannequin considers. Primarily based in your want, you’ll be able to select the worth of context dimension. On this instance, we are going to set the worth of this hyperparameter as 128 tokens.
mannequin.set_context_size(128)
Batching for Effectivity
By introducing the batching approach, it’s potential to course of a number of information segments concurrently, which might deal with the queries parallely and assist scale the applying for a big set of customers. However whereas deciding the batch dimension, it’s essential to fastidiously test your system’s capabilities. In any other case, your system may cause points as a consequence of heavy load.
As much as this step, we’re carried out with making the mannequin, tuning that mannequin, and saving it. Now, we will shortly take a look at it primarily based on our use and test whether or not it supplies the identical output we count on. So, let’s give some enter queries and generate the textual content primarily based on our loaded and configured mannequin.
for phrase in llm('Clarify one thing about Kdnuggets', stream = True):
print(phrase, finish='')
Output:
To get the suitable outcomes for a lot of the enter queries out of your small language mannequin, the next issues will be thought-about.
- Effective-Tuning: In case your software calls for excessive efficiency, i.e., the output of the queries to be resolved in considerably much less time, then it’s a must to fine-tune your mannequin in your particular dataset, the corpus on which you might be coaching your mannequin.
- Caching: Through the use of the caching approach, you’ll be able to retailer generally used information primarily based on the consumer in RAM in order that when the consumer calls for that information once more, it might simply be offered as a substitute of fetching once more from the disk, which requires comparatively extra time, as a consequence of which it might generate outcomes to hurry up future requests.
- Frequent Points: If you happen to encounter issues whereas creating, loading, and configuring the mannequin, you’ll be able to consult with the documentation and consumer group for troubleshooting suggestions.
On this article, we mentioned how one can create and deploy a small language mannequin in your native CPU by following the seven easy steps outlined on this article. This cost-effective strategy opens the door to varied language processing or pc imaginative and prescient functions and serves as a stepping stone for extra superior initiatives. However whereas engaged on initiatives, it’s a must to bear in mind the next issues to beat any points:
- Commonly save checkpoints throughout coaching to make sure you can proceed coaching or get well your mannequin in case of interruptions.
- Optimize your code and information pipelines for environment friendly reminiscence utilization, particularly when engaged on an area CPU.
- Think about using GPU acceleration or cloud-based assets if it’s worthwhile to scale up your mannequin sooner or later.
In conclusion, small language fashions supply a flexible and environment friendly answer for numerous language processing duties. With the right setup and optimization, you’ll be able to leverage their energy successfully.
Aryan Garg is a B.Tech. Electrical Engineering scholar, at present within the last yr of his undergrad. His curiosity lies within the area of Internet Improvement and Machine Studying. He have pursued this curiosity and am desperate to work extra in these instructions.

