

Zhipu AI has open sourced the GLM-4.6V collection as a pair of imaginative and prescient language fashions that deal with photos, video and instruments as top notch inputs for brokers, not as afterthoughts bolted on prime of textual content.
Mannequin lineup and context size
The collection has 2 fashions. GLM-4.6V is a 106B parameter basis mannequin for cloud and excessive efficiency cluster workloads. GLM-4.6V-Flash is a 9B parameter variant tuned for native deployment and low latency use.
GLM-4.6V extends the coaching context window to 128K tokens. In observe this helps roughly 150 pages of dense paperwork, 200 slide pages or one hour of video in a single cross as a result of pages are encoded as photos and consumed by the visible encoder.
Native multimodal device use
The principle technical change is native multimodal Perform Calling. Conventional device use in LLM programs routes every thing by way of textual content. Photos or pages are first changed into descriptions, the mannequin calls instruments utilizing textual content arguments after which reads textual responses. This wastes info and will increase latency.
GLM-4.6V introduces native multimodal Perform Calling. Photos, screenshots and doc pages cross instantly as device parameters. Instruments can return search consequence grids, charts, rendered net pages or product photos. The mannequin consumes these visible outputs and fuses them with textual content in the identical reasoning chain. This closes the loop from notion to understanding to execution and is explicitly positioned because the bridge between visible notion and executable motion for multimodal brokers.
To assist this, Zhipu AI extends the Mannequin Context Protocol with URL based mostly multimodal dealing with. Instruments obtain and return URLs that determine particular photos or frames, which avoids file measurement limits and permits exact choice inside multi picture contexts.
Wealthy textual content content material, net search and frontend replication
Zhipu AI analysis crew describes 4 canonical situations:
First, wealthy textual content content material understanding and creation. GLM-4.6V reads blended inputs comparable to papers, studies or slide decks and produces structured picture textual content interleaved outputs. It understands textual content, charts, figures, tables and formulation in the identical doc. Throughout era it will possibly crop related visuals or retrieve exterior photos by way of instruments, then run a visible audit step that filters low high quality photos and composes the ultimate article with inline figures.
Second, visible net search. The mannequin can detect person intent, plan which search instruments to name and mix textual content to picture and picture to textual content search. It then aligns retrieved photos and textual content, selects the related proof and outputs a structured reply, for instance a visible comparability of merchandise or locations.
Third, frontend replication and visible interplay. GLM-4.6V is tuned for design to code workflows. From a UI screenshot, it reconstructs pixel correct HTML, CSS and JavaScript. Builders can then mark a area on the screenshot and situation pure language directions, for instance transfer this button left or change this card background. The mannequin maps these directions again to the code and returns an up to date snippet.
Fourth, multimodal doc understanding at lengthy context. GLM-4.6V can learn multi doc inputs as much as the 128K token context restrict by treating pages as photos. The analysis crew studies a case the place the mannequin processes monetary studies from 4 public firms, extracts core metrics and builds a comparability desk, and a case the place it summarises a full soccer match whereas retaining the flexibility to reply questions on particular targets and timestamps.
Structure, knowledge and reinforcement studying
The GLM-4.6V fashions belong to the GLM-V household and based mostly on the tech report for GLM-4.5V and GLM-4.1V-Considering. The analysis crew highlights three essential technical components.
First, lengthy sequence modeling. GLM-4.6V extends the coaching context window to 128K tokens and runs continuous pre coaching on huge lengthy context picture textual content corpora. It makes use of compression alignment concepts from Glyph in order that visible tokens can carry dense info that’s aligned with language tokens.
Second, world data enhancement. Zhipu AI crew provides a billion scale multimodal notion and world data dataset at pre coaching time. This covers layered encyclopedic ideas and on a regular basis visible entities. The said aim is to enhance each primary notion and cross modal query answering completeness, not solely benchmarks.
Third, agentic knowledge synthesis and prolonged MCP. The analysis crew generates massive artificial traces the place the mannequin calls instruments, processes visible outputs and iterates on plans. They lengthen MCP with URL based mostly multimodal dealing with and an interleaved output mechanism. The era stack follows a Draft, Picture Choice, Closing Polish sequence. The mannequin can autonomously name cropping or search instruments between these levels to position photos on the proper positions within the output.
Instrument invocation is a part of the reinforcement studying goal. GLM-4.6V makes use of RL to align planning, instruction following and format adherence in advanced device chains.
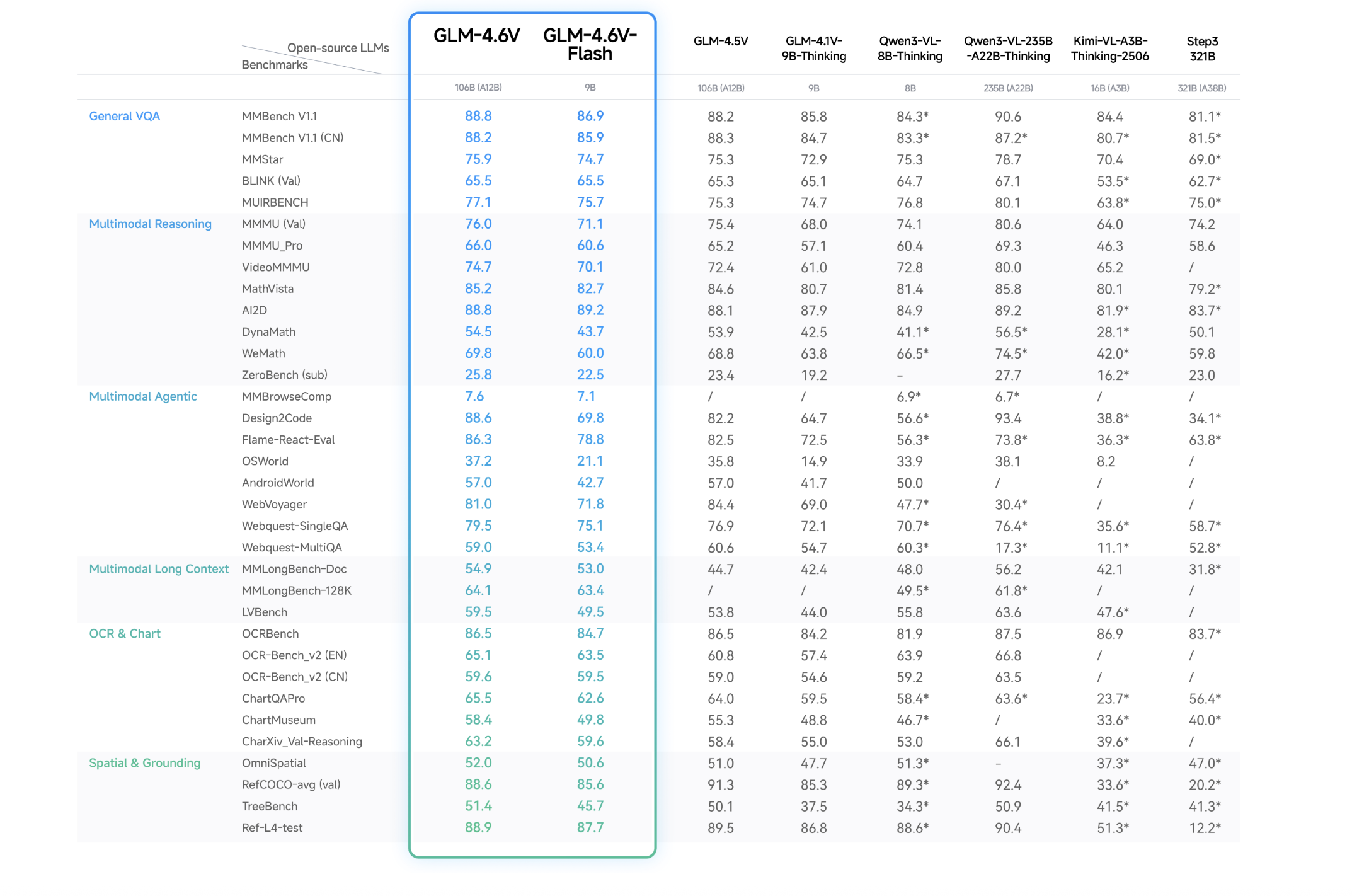
Efficiency
Key Takeaways
- GLM-4.6V is a 106B multimodal basis mannequin with a 128K token coaching context, and GLM-4.6V-Flash is a 9B variant optimized for native and low latency use.
- Each fashions assist native multimodal Perform Calling so instruments can devour and return photos, video frames and doc pages instantly, which hyperlinks visible notion to executable actions for brokers.
- GLM-4.6V is skilled for lengthy context multimodal understanding and interleaved era, so it will possibly learn massive blended doc units and emit structured textual content with inline figures and gear chosen photos in a single cross.
- The collection achieves state-of-the-art efficiency on main multimodal benchmarks at comparable parameter scales and is launched as open supply weights below the MIT license on Hugging Face and ModelScope.
Try the Mannequin Card on HF and Technical particulars. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you may be a part of us on telegram as properly.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

