
The Allen Institute for AI (AI2) has launched OLMoASR, a collection of open automated speech recognition (ASR) fashions that rival closed-source techniques resembling OpenAI’s Whisper. Past simply releasing mannequin weights, AI2 has printed coaching knowledge identifiers, filtering steps, coaching recipes, and benchmark scripts—an unusually clear transfer within the ASR area. This makes OLMoASR one of the crucial trending and extensible platforms for speech recognition analysis.
Why Open Automated Speech Recognition ASR?
Most speech recognition fashions out there as we speak—whether or not from OpenAI, Google, or Microsoft—are solely accessible by way of APIs. Whereas these companies present excessive efficiency, they function as black containers: the coaching datasets are opaque, the filtering strategies are undocumented, and the analysis protocols aren’t at all times aligned with analysis requirements.
This lack of transparency poses challenges for reproducibility and scientific progress. Researchers can not confirm claims, take a look at variations, or adapt fashions to new domains with out re-building massive datasets themselves. OLMoASR addresses this drawback by opening all the pipeline. The discharge is not only about enabling sensible transcription—it’s about pushing ASR towards a extra open, scientific basis.
Mannequin Structure and Scaling
OLMoASR makes use of a transformer encoder–decoder structure, the dominant paradigm in fashionable ASR.
- The encoder ingests audio waveforms and produces hidden representations.
- The decoder generates textual content tokens conditioned on the encoder’s outputs.
This design is just like Whisper, however OLMoASR makes the implementation totally open.
The household of fashions covers six sizes, all skilled on English:
- tiny.en – 39M parameters, designed for light-weight inference
- base.en – 74M parameters
- small.en – 244M parameters
- medium.en – 769M parameters
- massive.en-v1 – 1.5B parameters, skilled on 440K hours
- massive.en-v2 – 1.5B parameters, skilled on 680K hours
This vary permits builders to commerce off between inference value and accuracy. Smaller fashions are fitted to embedded gadgets or real-time transcription, whereas the bigger fashions maximize accuracy for analysis or batch workloads.
Information: From Internet Scraping to Curated Mixes
One of many core contributions of OLMoASR is the open launch of coaching datasets, not simply the fashions.
OLMoASR-Pool (~3M hours)
This large assortment incorporates weakly supervised speech paired with transcripts scraped from the net. It consists of round 3 million hours of audio and 17 million textual content transcripts. Like Whisper’s unique dataset, it’s noisy, containing misaligned captions, duplicates, and transcription errors.
OLMoASR-Combine (~1M hours)
To handle high quality points, AI2 utilized rigorous filtering:
- Alignment heuristics to make sure audio and transcripts match
- Fuzzy deduplication to take away repeated or low-diversity examples
- Cleansing guidelines to get rid of duplicate traces and mismatched textual content
The result’s a high-quality, 1M-hour dataset that reinforces zero-shot generalization—important for real-world duties the place knowledge might differ from coaching distributions.
This two-tiered knowledge technique mirrors practices in large-scale language mannequin pretraining: use huge noisy corpora for scale, then refine with filtered subsets to enhance high quality.
Efficiency Benchmarks
AI2 benchmarked OLMoASR towards Whisper throughout each short-form and long-form speech duties, utilizing datasets like LibriSpeech, TED-LIUM3, Switchboard, AMI, and VoxPopuli.
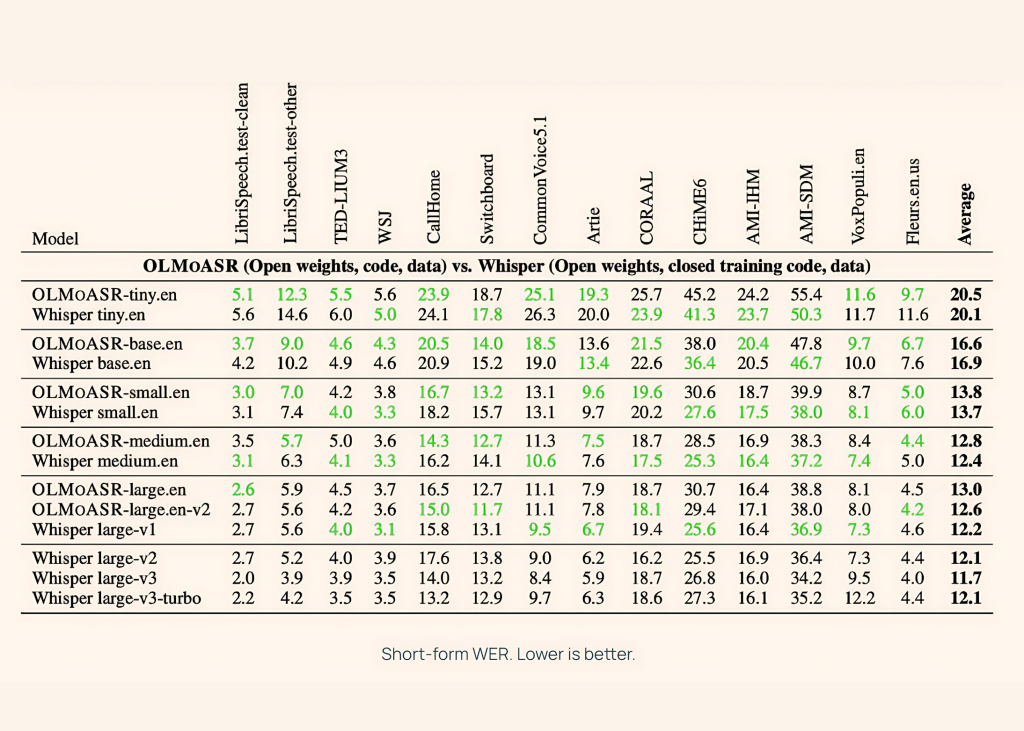
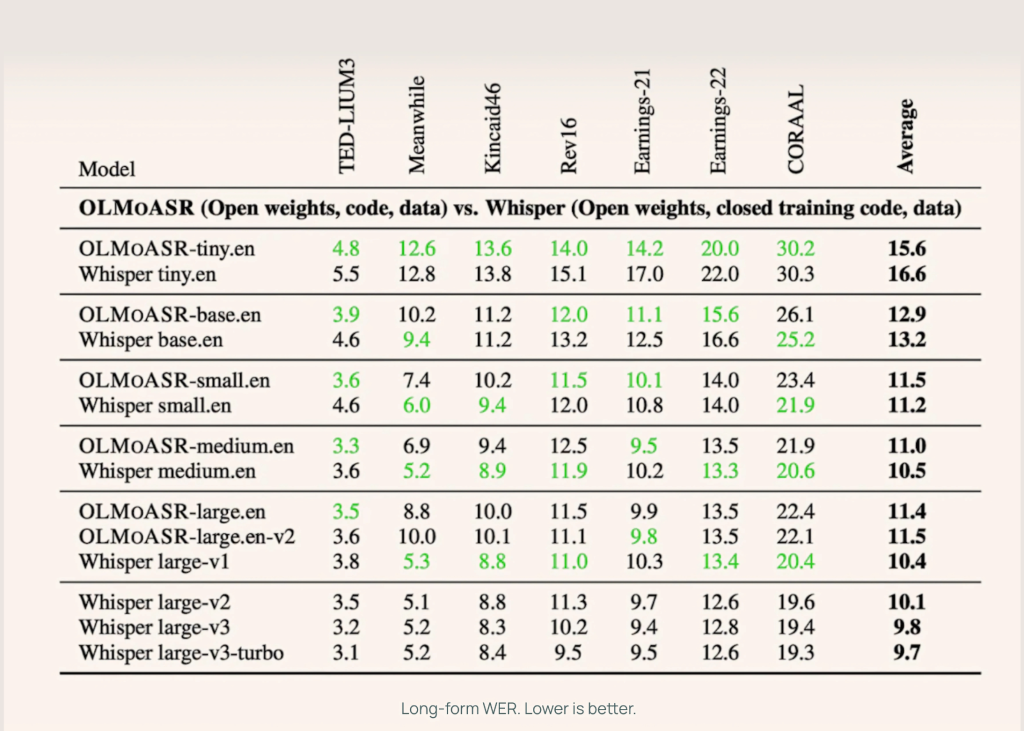
Medium Mannequin (769M)
- 12.8% WER (phrase error fee) on short-form speech
- 11.0% WER on long-form speech
This almost matches Whisper-medium.en, which achieves 12.4% and 10.5% respectively.
Giant Fashions (1.5B)
- massive.en-v1 (440K hours): 13.0% WER short-form vs Whisper large-v1 at 12.2%
- massive.en-v2 (680K hours): 12.6% WER, closing the hole to lower than 0.5%
Smaller Fashions
Even the tiny and base variations carry out competitively:
- tiny.en: ~20.5% WER short-form, ~15.6% WER long-form
- base.en: ~16.6% WER short-form, ~12.9% WER long-form
This provides builders flexibility to decide on fashions based mostly on compute and latency necessities.
Learn how to use?
Transcribing audio takes only a few traces of code:
import olmoasr
mannequin = olmoasr.load_model("medium", inference=True)
end result = mannequin.transcribe("audio.mp3")
print(end result)
The output consists of each the transcription and time-aligned segments, making it helpful for captioning, assembly transcription, or downstream NLP pipelines.
High-quality-Tuning and Area Adaptation
Since AI2 supplies full coaching code and recipes, OLMoASR may be fine-tuned for specialised domains:
- Medical speech recognition – adapting fashions on datasets like MIMIC-III or proprietary hospital recordings
- Authorized transcription – coaching on courtroom audio or authorized proceedings
- Low-resource accents – fine-tuning on dialects not effectively lined in OLMoASR-Combine
This adaptability is important: ASR efficiency usually drops when fashions are utilized in specialised domains with domain-specific jargon. Open pipelines make area adaptation easy.
Purposes
OLMoASR opens up thrilling alternatives throughout educational analysis and real-world AI improvement:
- Instructional Analysis: Researchers can discover the intricate relationships between mannequin structure, dataset high quality, and filtering strategies to know their results on speech recognition efficiency.
- Human-Pc Interplay: Builders acquire the liberty to embed speech recognition capabilities instantly into conversational AI techniques, real-time assembly transcription platforms, and accessibility functions—all with out dependency on proprietary APIs or exterior companies.
- Multimodal AI Growth: When mixed with massive language fashions, OLMoASR allows the creation of superior multimodal assistants that may seamlessly course of spoken enter and generate clever, contextually-aware responses.
- Analysis Benchmarking: The open availability of each coaching knowledge and analysis metrics positions OLMoASR as a standardized reference level, permitting researchers to check new approaches towards a constant, reproducible baseline in future ASR research.
Conclusion
The discharge of OLMoASR brings high-quality speech recognition may be developed and launched in a approach that prioritizes transparency and reproducibility. Whereas the fashions are presently restricted to English and nonetheless demand important compute for coaching, they supply a strong basis for adaptation and extension. This launch units a transparent reference level for future work in open ASR and makes it simpler for researchers and builders to review, benchmark, and apply speech recognition fashions in several domains.
Take a look at the MODEL on Hugging Face, GitHub Web page and TECHNICAL DETAILS. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our Publication.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

