

Picture by Writer
# Introduction
Final month, I discovered myself gazing my financial institution assertion, making an attempt to determine the place my cash was really going. Spreadsheets felt cumbersome. Present apps are like black packing containers, and the worst half is that they demand I add my delicate monetary knowledge to a cloud server. I needed one thing completely different. I needed an AI knowledge analyst that might analyze my spending, spot uncommon transactions, and provides me clear insights — all whereas conserving my knowledge 100% native. So, I constructed one.
What began as a weekend venture became a deep dive into real-world knowledge preprocessing, sensible machine studying, and the ability of native giant language fashions (LLMs). On this article, I’ll stroll you thru how I created an AI-powered monetary evaluation app utilizing Python with “Vibe Coding.” Alongside the best way, you’ll be taught many sensible ideas that apply to any knowledge science venture, whether or not you might be analyzing gross sales logs, sensor knowledge, or buyer suggestions.
By the top, you’ll perceive:
- The best way to construct a strong knowledge preprocessing pipeline that handles messy, real-world CSV information
- How to decide on and implement machine studying fashions when you might have restricted coaching knowledge
- The best way to design interactive visualizations that truly reply consumer questions
- The best way to combine an area LLM for producing natural-language insights with out sacrificing privateness
The whole supply code is out there on GitHub. Be happy to fork it, lengthen it, or use it as a place to begin to your personal AI knowledge analyst.
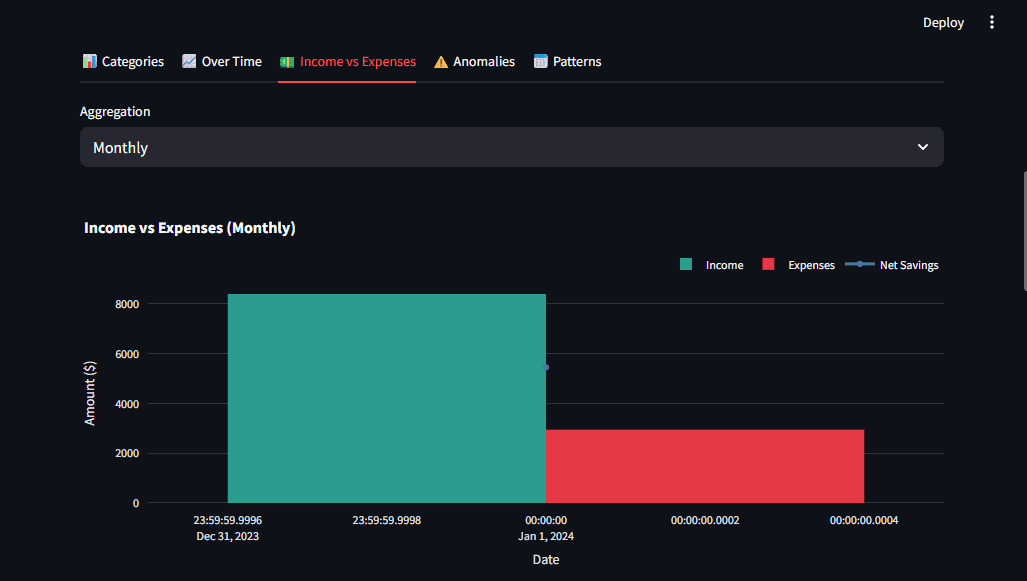
Fig. 1: App dashboard exhibiting spending breakdown and AI insights | Picture by Writer
# The Drawback: Why I Constructed This
Most private finance apps share a basic flaw: your knowledge leaves your management. You add financial institution statements to companies that retailer, course of, and doubtlessly monetize your data. I needed a software that:
- Let me add and analyze knowledge immediately
- Processed the whole lot domestically — no cloud, no knowledge leaks
- Offered AI-powered insights, not simply static charts
This venture turned my car for studying a number of ideas that each knowledge scientist ought to know, like dealing with inconsistent knowledge codecs, choosing algorithms that work with small datasets, and constructing privacy-preserving AI options.
# Venture Structure
Earlier than diving into code, here’s a venture construction exhibiting how the items match collectively:
venture/
├── app.py # Foremost Streamlit app
├── config.py # Settings (classes, Ollama config)
├── preprocessing.py # Auto-detect CSV codecs, normalize knowledge
├── ml_models.py # Transaction classifier + Isolation Forest anomaly detector
├── visualizations.py # Plotly charts (pie, bar, timeline, heatmap)
├── llm_integration.py # Ollama streaming integration
├── necessities.txt # Dependencies
├── README.md # Documentation with "deep dive" classes
└── sample_data/
├── sample_bank_statement.csv
└── sample_bank_format_2.csv
We are going to have a look at constructing every layer step-by-step.
# Step 1: Constructing a Sturdy Information Preprocessing Pipeline
The primary lesson I discovered was that real-world knowledge is messy. Completely different banks export CSVs in utterly completely different codecs. Chase Financial institution makes use of “Transaction Date” and “Quantity.” Financial institution of America makes use of “Date,” “Payee,” and separate “Debit”https://www.kdnuggets.com/”Credit score” columns. Moniepoint and OPay every have their very own types.
A preprocessing pipeline should deal with these variations routinely.
// Auto-Detecting Column Mappings
I constructed a pattern-matching system that identifies columns no matter naming conventions. Utilizing common expressions, we will map unclear column names to plain fields.
import re
COLUMN_PATTERNS = {
"date": [r"date", r"trans.*date", r"posting.*date"],
"description": [r"description", r"memo", r"payee", r"merchant"],
"quantity": [r"^amount$", r"transaction.*amount"],
"debit": [r"debit", r"withdrawal", r"expense"],
"credit score": [r"credit", r"deposit", r"income"],
}
def detect_column_mapping(df):
mapping = {}
for area, patterns in COLUMN_PATTERNS.objects():
for col in df.columns:
for sample in patterns:
if re.search(sample, col.decrease()):
mapping[field] = col
break
return mapping
The important thing perception: design for variations, not particular codecs. This strategy works for any CSV that makes use of widespread monetary phrases.
// Normalizing to a Customary Schema
As soon as columns are detected, we normalize the whole lot right into a constant construction. For instance, banks that break up debits and credit should be mixed right into a single quantity column (adverse for bills, optimistic for earnings):
if "debit" in mapping and "credit score" in mapping:
debit = df[mapping["debit"]].apply(parse_amount).abs() * -1
credit score = df[mapping["credit"]].apply(parse_amount).abs()
normalized["amount"] = credit score + debit
Key takeaway: Normalize your knowledge as quickly as attainable. It simplifies each following operation, like characteristic engineering, machine studying modeling, and visualization.
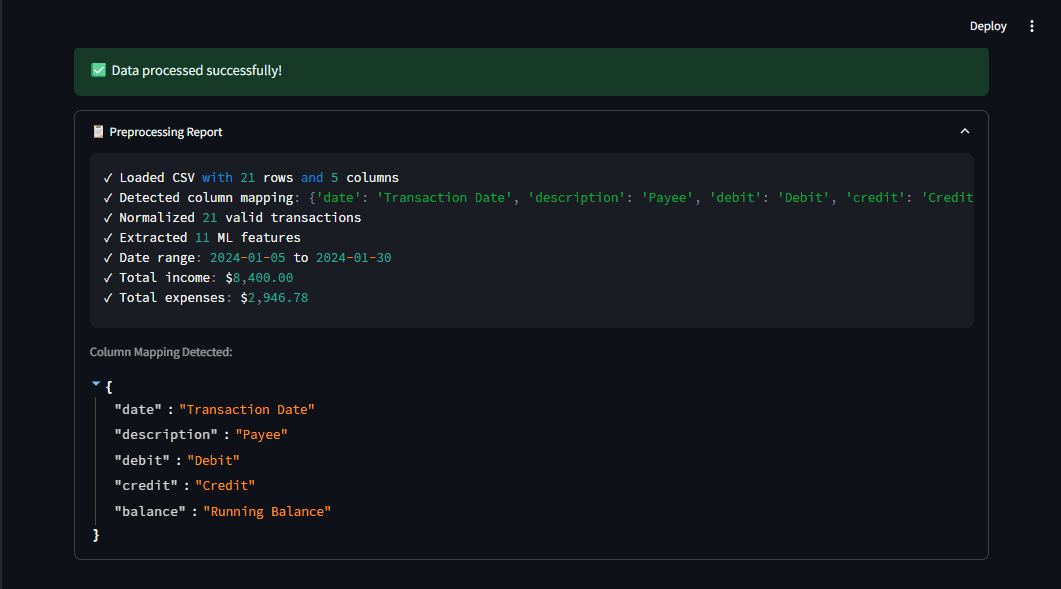
Fig 2: The preprocessing report exhibits what the pipeline detected, giving customers transparency | Picture by Writer
# Step 2: Selecting Machine Studying Fashions for Restricted Information
The second main problem is proscribed coaching knowledge. Customers add their very own statements, and there’s no huge labeled dataset to coach a deep studying mannequin. We want algorithms that work properly with small samples and will be augmented with easy guidelines.
// Transaction Classification: A Hybrid Strategy
As an alternative of pure machine studying, I constructed a hybrid system:
- Rule-based matching for assured circumstances (e.g., key phrases like “WALMART” → groceries)
- Sample-based fallback for ambiguous transactions
SPENDING_CATEGORIES = {
"groceries": ["walmart", "costco", "whole foods", "kroger"],
"eating": ["restaurant", "starbucks", "mcdonald", "doordash"],
"transportation": ["uber", "lyft", "shell", "chevron", "gas"],
# ... extra classes
}
def classify_transaction(description, quantity):
for class, key phrases in SPENDING_CATEGORIES.objects():
if any(kw in description.decrease() for kw in key phrases):
return class
return "earnings" if quantity > 0 else "different"
This strategy works instantly with none coaching knowledge, and it’s simple for customers to grasp and customise.
// Anomaly Detection: Why Isolation Forest?
For detecting uncommon spending, I wanted an algorithm that might:
- Work with small datasets (not like deep studying)
- Make no assumptions about knowledge distribution (not like statistical strategies like Z-score alone)
- Present quick predictions for an interactive UI
Isolation Forest from scikit-learn ticked all of the packing containers. It isolates anomalies by randomly partitioning the information. Anomalies are few and completely different, in order that they require fewer splits to isolate.
from sklearn.ensemble import IsolationForest
detector = IsolationForest(
contamination=0.05, # Count on ~5% anomalies
random_state=42
)
detector.match(options)
predictions = detector.predict(options) # -1 = anomaly
I additionally mixed this with easy Z-score checks to catch apparent outliers. A Z-score describes the place of a uncooked rating when it comes to its distance from the imply, measured in normal deviations:
[
z = frac{x – mu}{sigma}
]
The mixed strategy catches extra anomalies than both technique alone.
Key takeaway: Typically easy, well-chosen algorithms outperform advanced ones, particularly when you might have restricted knowledge.
Fig 3: The anomaly detector flags uncommon transactions, which stand out within the timeline | Picture by Writer
# Step 3: Designing Visualizations That Reply Questions
Visualizations ought to reply questions, not simply present knowledge. I used Plotly for interactive charts as a result of it permits customers to discover the information themselves. Listed here are the design ideas I adopted:
- Constant colour coding: Purple for bills, inexperienced for earnings
- Context by way of comparability: Present earnings vs. bills aspect by aspect
- Progressive disclosure: Present a abstract first, then let customers drill down
For instance, the spending breakdown makes use of a donut chart with a gap within the center for a cleaner look:
import plotly.categorical as px
fig = px.pie(
category_totals,
values="Quantity",
names="Class",
gap=0.4,
color_discrete_map=CATEGORY_COLORS
)
Streamlit makes it simple so as to add these charts with st.plotly_chart() and construct a responsive dashboard.
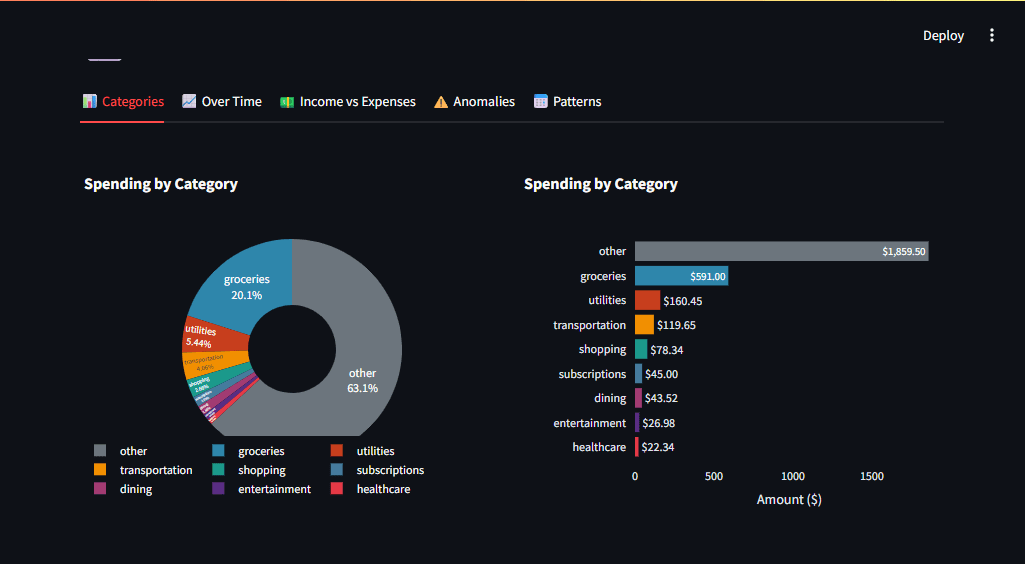
Fig 4: A number of chart varieties give customers completely different views on the identical knowledge | Picture by Writer
# Step 4: Integrating a Native Giant Language Mannequin for Pure Language Insights
The ultimate piece was producing human-readable insights. I selected to combine Ollama, a software for operating LLMs domestically. Why native as a substitute of calling OpenAI or Claude?
- Privateness: Financial institution knowledge by no means leaves the machine
- Price: Limitless queries, zero API charges
- Pace: No community latency (although technology nonetheless takes just a few seconds)
// Streaming for Higher Consumer Expertise
LLMs can take a number of seconds to generate a response. Streamlit exhibits tokens as they arrive, making the wait really feel shorter. Right here is a straightforward implementation utilizing requests with streaming:
import requests
import json
def generate(self, immediate):
response = requests.put up(
f"{self.base_url}/api/generate",
json={"mannequin": "llama3.2", "immediate": immediate, "stream": True},
stream=True
)
for line in response.iter_lines():
if line:
knowledge = json.masses(line)
yield knowledge.get("response", "")
In Streamlit, you possibly can show this with st.write_stream().
st.write_stream(llm.get_overall_insights(df))
// Immediate Engineering for Monetary Information
The important thing to helpful LLM output is a structured immediate that features precise knowledge. For instance:
immediate = f"""Analyze this monetary abstract:
- Complete Revenue: ${earnings:,.2f}
- Complete Bills: ${bills:,.2f}
- Prime Class: {top_category}
- Largest Anomaly: {anomaly_desc}
Present 2-3 actionable suggestions based mostly on this knowledge."""
This offers the mannequin concrete numbers to work with, resulting in extra related insights.
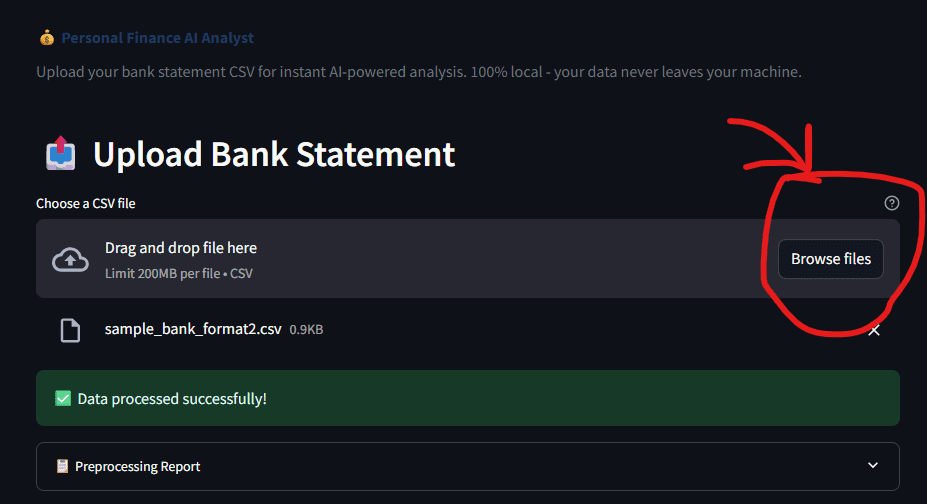
Fig 5: The add interface is straightforward; select a CSV and let the AI do the remainder | Picture by Writer
// Working the Utility
Getting began is simple. You will have Python put in, then run:
pip set up -r necessities.txt
# Elective, for AI insights
ollama pull llama3.2
streamlit run app.py
Add any financial institution CSV (the app auto-detects the format), and inside seconds, you will note a dashboard with categorized transactions, anomalies, and AI-generated insights.
# Conclusion
This venture taught me that constructing one thing useful is only the start. The true studying occurred after I requested why each bit works:
- Why auto-detect columns? As a result of real-world knowledge doesn’t comply with your schema. Constructing a versatile pipeline saves hours of handbook cleanup.
- Why Isolation Forest? As a result of small datasets want algorithms designed for them. You don’t at all times want deep studying.
- Why native LLMs? As a result of privateness and price matter in manufacturing. Working fashions domestically is now sensible and highly effective.
These classes apply far past private finance, whether or not you might be analyzing gross sales knowledge, server logs, or scientific measurements. The identical ideas of strong preprocessing, pragmatic modeling, and privacy-aware AI will serve you in any knowledge venture.
The whole supply code is out there on GitHub. Fork it, lengthen it, and make it your individual. In case you construct one thing cool with it, I’d love to listen to about it.
// References
Shittu Olumide is a software program engineer and technical author captivated with leveraging cutting-edge applied sciences to craft compelling narratives, with a eager eye for element and a knack for simplifying advanced ideas. You may as well discover Shittu on Twitter.

