

Synthetic intelligence (AI) observability refers back to the potential to know, monitor, and consider AI methods by monitoring their distinctive metrics—comparable to token utilization, response high quality, latency, and mannequin drift. In contrast to conventional software program, massive language fashions (LLMs) and different generative AI purposes are probabilistic in nature. They don’t comply with mounted, clear execution paths, which makes their decision-making tough to hint and cause about. This “black field” habits creates challenges for belief, particularly in high-stakes or production-critical environments.
AI methods are now not experimental demos—they’re manufacturing software program. And like several manufacturing system, they want observability. Conventional software program engineering has lengthy relied on logging, metrics, and distributed tracing to know system habits at scale. As LLM-powered purposes transfer into actual person workflows, the identical self-discipline is turning into important. To function these methods reliably, groups want visibility into what occurs at every step of the AI pipeline, from inputs and mannequin responses to downstream actions and failures.

Allow us to now perceive the completely different layers of AI observability with the assistance of an instance.
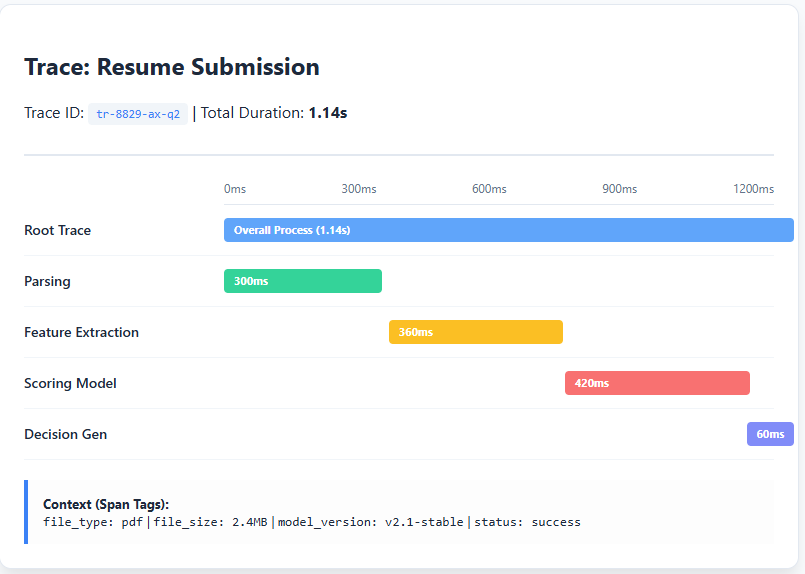
Consider an AI resume screening system as a sequence of steps relatively than a single black field. A recruiter uploads a resume, the system processes it by a number of parts, and eventually returns a shortlist rating or advice. Every step takes time, has a value related to it, and can even fail individually. Simply trying on the closing advice won’t reveal the complete image, because the finer particulars is perhaps missed.
That is why traces and spans are essential.
Traces
A hint represents the entire lifecycle of a single resume submission—from the second the file is uploaded to the second the ultimate rating is returned. You’ll be able to consider it as one steady timeline that captures all the things that occurs for that request. Each hint has a novel Hint ID, which ties all associated operations collectively.
Spans
Every main operation contained in the pipeline is captured as a span. These spans are nested throughout the hint and characterize particular items of labor.
Right here’s what these spans seem like on this system:
Add Span
The resume is uploaded by the recruiter. This span information the timestamp, file dimension, format, and primary metadata. That is the place the hint begins.
Parsing Span
The doc is transformed into structured textual content. This span captures parsing time and errors. If resumes fail to parse accurately or formatting breaks, the difficulty exhibits up right here.
Characteristic Extraction Span
The parsed textual content is analyzed to extract abilities, expertise, and key phrases. This span tracks latency and intermediate outputs. Poor extraction high quality turns into seen at this stage.
Scoring Span
The extracted options are handed right into a scoring mannequin. This span logs mannequin latency, confidence scores, and any fallback logic. That is usually essentially the most compute-intensive step.
Resolution Span
The system generates a closing advice (shortlist, reject, or assessment). This span information the output resolution and response time.
Why Span-Degree Observability Issues
With out span-level tracing, all you recognize is that the ultimate advice was improper—you haven’t any visibility into whether or not the resume did not parse accurately, key abilities had been missed throughout extraction, or the scoring mannequin behaved unexpectedly. Span-level observability makes every of those failure modes express and debuggable.
It additionally reveals the place money and time are literally being spent, comparable to whether or not parsing latency is growing or scoring is dominating compute prices. Over time, as resume codecs evolve, new abilities emerge, and job necessities change, AI methods can quietly degrade. Monitoring spans independently permits groups to detect this drift early and repair particular parts with out retraining or redesigning the complete system.
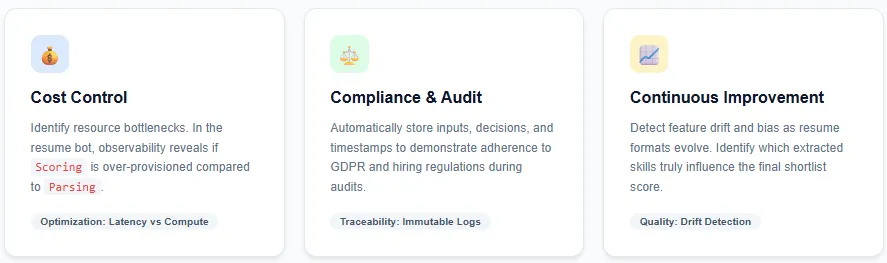
AI observability offers three core advantages: value management, compliance, and steady mannequin enchancment. By gaining visibility into how AI parts work together with the broader system, groups can rapidly spot wasted sources—for instance, within the resume screening bot, observability would possibly reveal that doc parsing is light-weight whereas candidate scoring consumes a lot of the compute, permitting groups to optimize or scale sources accordingly.
Observability instruments additionally simplify compliance by mechanically gathering and storing telemetry comparable to inputs, choices, and timestamps; within the resume bot, this makes it simpler to audit how candidate knowledge was processed and display adherence to knowledge safety and hiring rules.
Lastly, the wealthy telemetry captured at every step helps mannequin builders keep integrity over time by detecting drift as resume codecs and abilities evolve, figuring out which options really affect choices, and surfacing potential bias or equity points earlier than they grow to be systemic issues.
Langfuse is a well-liked open-source LLMOps and observability instrument that has grown quickly since its launch in June 2023. It’s model- and framework-agnostic, helps self-hosting, and integrates simply with instruments like OpenTelemetry, LangChain, and the OpenAI SDK.
At a excessive degree, Langfuse provides groups end-to-end visibility into their AI methods. It presents tracing of LLM calls, instruments to judge mannequin outputs utilizing human or AI suggestions, centralized immediate administration, and dashboards for efficiency and value monitoring. As a result of it really works throughout completely different fashions and frameworks, it may be added to current AI workflows with minimal friction.
Arize is an ML and LLM observability platform that helps groups monitor, consider, and analyze fashions in manufacturing. It helps each conventional ML fashions and LLM-based methods, and integrates effectively with instruments like LangChain, LlamaIndex, and OpenAI-based brokers, making it appropriate for contemporary AI pipelines.
Phoenix, Arize’s open-source providing (licensed underneath ELv2), focuses on LLM observability. It contains built-in hallucination detection, detailed tracing utilizing OpenTelemetry requirements, and instruments to examine and debug mannequin habits. Phoenix is designed for groups that need clear, self-hosted observability for LLM purposes with out counting on managed companies.
TruLens is an observability instrument that focuses totally on the qualitative analysis of LLM responses. As a substitute of emphasizing infrastructure-level metrics, TruLens attaches suggestions features to every LLM name and evaluates the generated response after it’s produced. These suggestions features behave like fashions themselves, scoring or assessing points comparable to relevance, coherence, or alignment with expectations.
TruLens is Python-only and is accessible as free and open-source software program underneath the MIT License, making it straightforward to undertake for groups that need light-weight, response-level analysis and not using a full LLMOps platform.

I’m a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I’ve a eager curiosity in Information Science, particularly Neural Networks and their utility in varied areas.

