
Within the fast-evolving discipline of pure language processing, the capabilities of enormous language fashions have grown exponentially. Researchers and organizations worldwide are regularly pushing the boundaries of those fashions to enhance their efficiency in numerous pure language understanding and technology duties. One crucial facet of advancing these fashions is the standard of the coaching knowledge they depend on. On this article, we delve right into a analysis paper that tackles the problem of enhancing open-source language fashions utilizing mixed-quality knowledge. This analysis explores the proposed methodology, know-how, and implications for pure language processing.
Blended-quality knowledge, together with expert-generated and sub-optimal knowledge, poses a big problem in coaching language fashions. Skilled knowledge generated by state-of-the-art fashions like GPT-4 is often top quality and serves as a gold commonplace for coaching. However, sub-optimal knowledge originating from older fashions like GPT-3.5 could exhibit decrease high quality and current challenges throughout coaching. This analysis underneath dialogue acknowledges this mixed-quality knowledge state of affairs and goals to enhance the instruction-following talents of open-source language fashions.
Earlier than delving into the proposed methodology, let’s briefly contact upon present strategies and instruments utilized in language mannequin coaching. One frequent strategy to enhancing these fashions is Supervised Wonderful-Tuning (SFT). In SFT, fashions are skilled on instruction-following duties utilizing high-quality expert-generated knowledge, which guides producing right responses. Moreover, Reinforcement Studying Wonderful-Tuning (RLFT) strategies have gained reputation. RLFT includes accumulating choice suggestions from people and coaching fashions to maximise rewards based mostly on these preferences.
Tsinghua College proposed an progressive methodology of their analysis paper – OpenChat. OpenChat is an progressive framework that enhances open-source language fashions utilizing mixed-quality knowledge. At its core lies the Conditioned Reinforcement Studying Wonderful-Tuning (C-RLFT), a novel coaching methodology that simplifies the coaching course of and reduces the reliance on reward fashions.
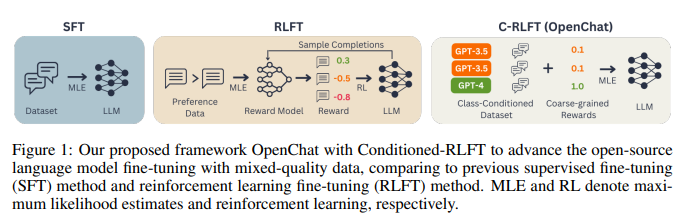
C-RLFT enriches the enter info for language fashions by distinguishing between completely different knowledge sources based mostly on their high quality. This distinction is achieved by means of the implementation of a class-conditioned coverage. The coverage helps the mannequin differentiate between expert-generated knowledge (of top quality) and sub-optimal knowledge (decrease high quality). By doing so, C-RLFT supplies specific alerts to the mannequin, enabling it to enhance its instruction-following talents.
The efficiency of OpenChat, particularly the open chat-13 b mannequin, has been evaluated throughout numerous benchmarks. One of many notable benchmarks used is AlpacaEval, the place the mannequin’s instruction-following talents are put to the take a look at. Openchat-13b displays outstanding outcomes, outperforming different 13-billion parameter open-source fashions like LLaMA-2. It achieves larger win charges and superior efficiency in instruction-following duties, demonstrating the effectiveness of the C-RLFT methodology.
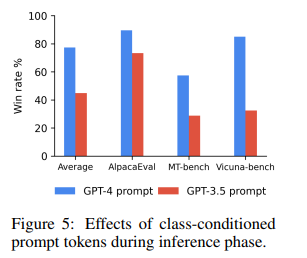
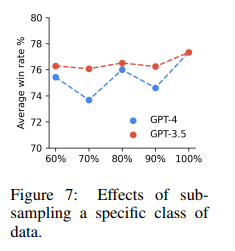
The importance of information high quality is a vital facet highlighted by the analysis workforce. Regardless of its restricted amount, professional knowledge performs an important function in enhancing the efficiency of language fashions. The flexibility to distinguish between professional and sub-optimal knowledge, coupled with the C-RLFT methodology, results in substantial enhancements in mannequin efficiency. This discovering underscores the significance of curating high-quality coaching knowledge to make sure the success of language mannequin coaching.
Implications and Future Analysis
The OpenChat framework and the C-RLFT methodology maintain promise for the way forward for pure language processing. This strategy opens up new avenues for analysis and growth by simplifying the coaching course of and decreasing reliance on complicated reward fashions. It additionally addresses the problem of mixed-quality knowledge, making it extra accessible to leverage numerous coaching datasets successfully.
In conclusion, OpenChat presents an progressive resolution to boost open-source language fashions with mixed-quality knowledge. By introducing the C-RLFT methodology, this strategy achieves superior instruction-following talents, as evidenced by its efficiency in benchmarks. As pure language processing continues to evolve, progressive methods like OpenChat pave the best way for extra environment friendly and efficient language mannequin coaching.
Try the Paper. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t neglect to affix our 30k+ ML SubReddit, 40k+ Fb Group, Discord Channel, and E mail Publication, the place we share the newest AI analysis information, cool AI initiatives, and extra.
In case you like our work, you’ll love our e-newsletter..
Madhur Garg is a consulting intern at MarktechPost. He’s presently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Know-how (IIT), Patna. He shares a robust ardour for Machine Studying and enjoys exploring the newest developments in applied sciences and their sensible purposes. With a eager curiosity in synthetic intelligence and its numerous purposes, Madhur is decided to contribute to the sphere of Information Science and leverage its potential impression in numerous industries.

