

Within the present panorama of pc imaginative and prescient, the usual working process entails a modular ‘Lego-brick’ method: a pre-trained imaginative and prescient encoder for function extraction paired with a separate decoder for job prediction. Whereas efficient, this architectural separation complicates scaling and bottlenecks the interplay between language and imaginative and prescient.
The Expertise Innovation Institute (TII) analysis workforce is difficult this paradigm with Falcon Notion, a 600M-parameter unified dense Transformer. By processing picture patches and textual content tokens in a shared parameter house from the very first layer, TII analysis workforce has developed an early-fusion stack that handles notion and job modeling with excessive effectivity.
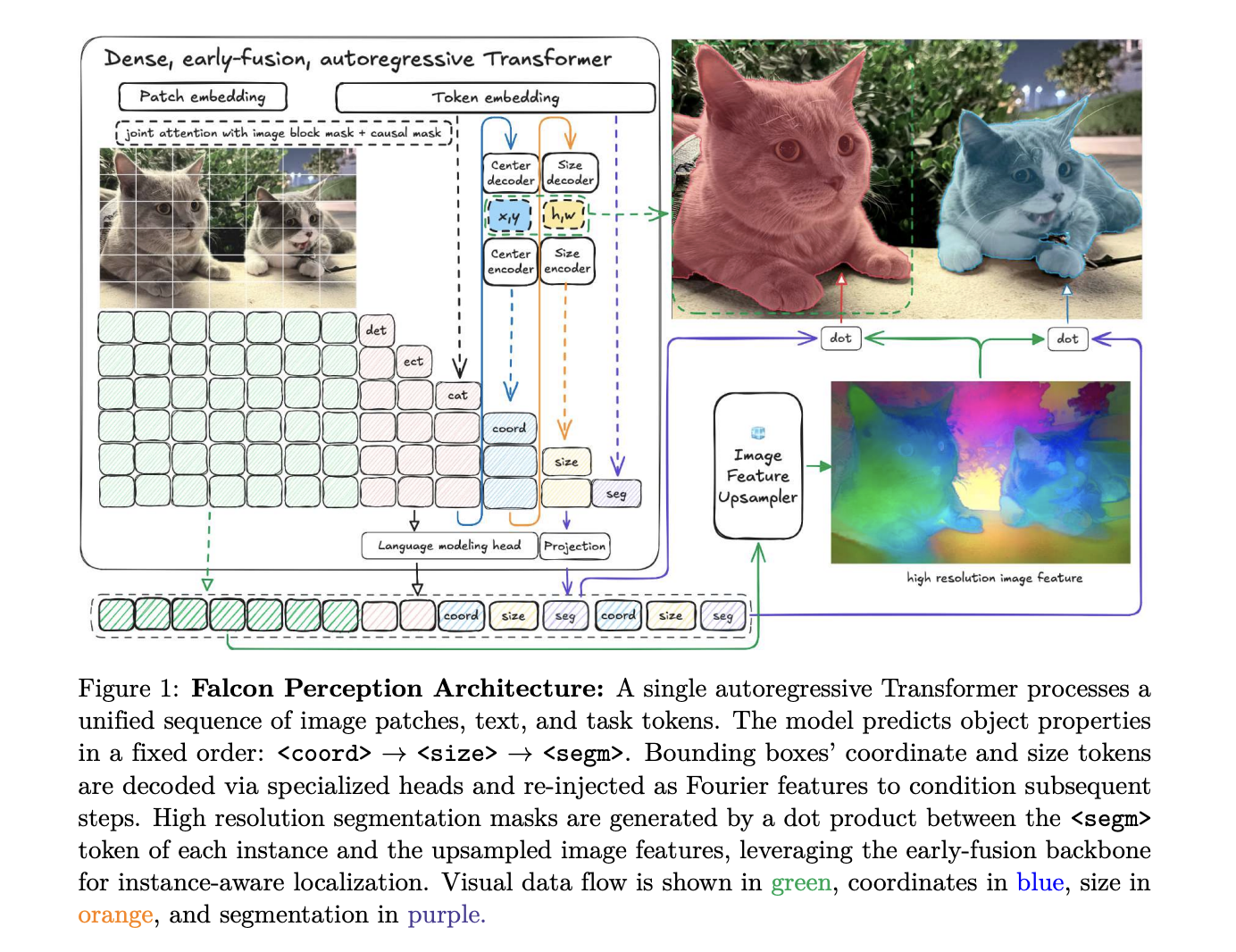
The Structure: A Single Stack for Each Modality
The core design of Falcon Notion is constructed on the speculation {that a} single Transformer can concurrently be taught visible representations and carry out task-specific era.
Hybrid Consideration and GGROPE
In contrast to normal language fashions that use strict causal masking, Falcon Notion employs a hybrid consideration technique. Picture tokens attend to one another bidirectionally to construct a world visible context, whereas textual content and job tokens attend to all previous tokens (causal masking) to allow autoregressive prediction.
To take care of 2D spatial relationships in a flattened sequence, the analysis workforce makes use of 3D Rotary Positional Embeddings. This decomposes the pinnacle dimension right into a sequential element and a spatial element utilizing Golden Gate ROPE (GGROPE). GGROPE permits consideration heads to take care of relative positions alongside arbitrary angles, making the mannequin sturdy to rotation and facet ratio variations.
Minimalist Sequence Logic
The fundamental architectural sequence follows a Chain-of-Notion format:
[Image] [Text] <coord> <measurement> <seg> ... <eos>.
This ensures that the mannequin resolves spatial ambiguity (place and measurement) as a conditioning sign earlier than producing the ultimate segmentation masks.
Engineering for Scale: Muon, FlexAttention, and Raster Ordering
TII analysis workforce launched a number of optimizations to stabilize coaching and maximize GPU utilization for these heterogeneous sequences.
- Muon Optimization: The analysis workforce report that using the Muon optimizer for specialised heads (coordinates, measurement, and segmentation) led to decrease coaching losses and improved efficiency on benchmarks in comparison with normal AdamW.
- FlexAttention and Sequence Packing: To course of photos at native resolutions with out losing compute on padding, the mannequin makes use of a scatter-and-pack technique. Legitimate patches are packed into fixed-length blocks, and FlexAttention is used to limit self-attention inside every picture pattern’s boundaries.
- Raster Ordering: When a number of objects are current, Falcon Notion predicts them in raster order (top-to-bottom, left-to-right). This was discovered to converge sooner and produce decrease coordinate loss than random or size-based ordering.
The Coaching Recipe: Distillation to 685GT
The mannequin makes use of multi-teacher distillation for initialization, distilling information from DINOv3 (ViT-H) for native options and SigLIP2 (So400m) for language-aligned options. Following initialization, the mannequin undergoes a three-stage notion coaching pipeline totaling roughly 685 Gigatokens (GT):
- In-Context Itemizing (450 GT): Studying to ‘listing’ the scene stock to construct world context.
- Process Alignment (225 GT): Transitioning to independent-query duties utilizing Question Masking to make sure the mannequin grounds every question solely on the picture.
- Lengthy-Context Finetuning (10 GT): Brief adaptation for excessive density, growing the masks restrict to 600 per expression.
Throughout these phases, the task-specific serialization is used:
<picture>expr1<current><coord><measurement><seg> <eoq>expr2<absent> <eoq> <eos>.
The <current> and <absent> tokens drive the mannequin to decide to a binary determination on an object’s existence earlier than localization.
PBench: Profiling Capabilities Past Saturated Baselines
To measure progress, TII analysis workforce launched PBench, a benchmark that organizes samples into 5 ranges of semantic complexity to disentangle mannequin failure modes.
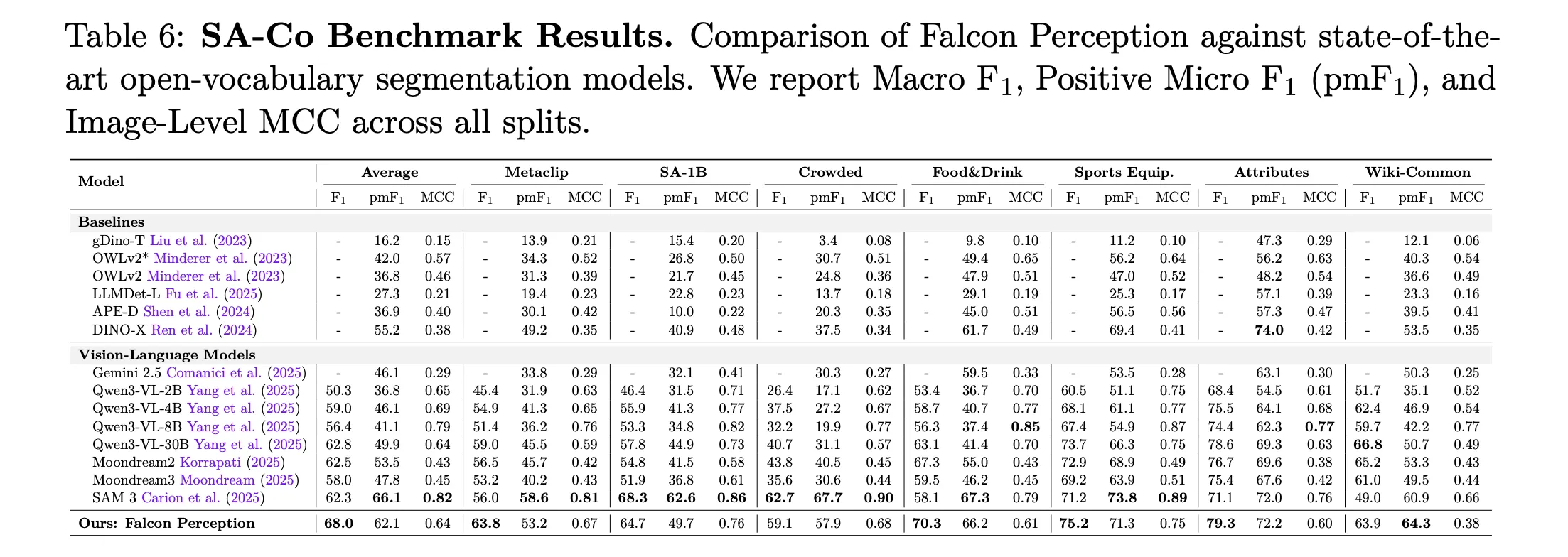
Major Outcomes: Falcon Notion vs. SAM 3 (Macro-F1)
| Benchmark Cut up | SAM 3 | Falcon Notion (600M) |
| L0: Easy Objects | 64.3 | 65.1 |
| L1: Attributes | 54.4 | 63.6 |
| L2: OCR-Guided | 24.6 | 38.0 |
| L3: Spatial Understanding | 31.6 | 53.5 |
| L4: Relations | 33.3 | 49.1 |
| Dense Cut up | 58.4 | 72.6 |
Falcon Notion considerably outperforms SAM 3 on complicated semantic duties, notably displaying a +21.9 level achieve on spatial understanding (Stage 3).
FalconOCR: The 300M Doc specialist
TII workforce additionally prolonged this early-fusion recipe to FalconOCR, a compact 300M-parameter mannequin initialized from scratch to prioritize fine-grained glyph recognition. FalconOCR is aggressive with a number of bigger proprietary and modular OCR techniques:
- olmOCR: Achieves 80.3% accuracy, matching or exceeding Gemini 3 Professional (80.2%) and GPT 5.2 (69.8%).
- OmniDocBench: Reaches an total rating of 88.64, forward of GPT 5.2 (86.56) and Mistral OCR 3 (85.20), although it trails the highest modular pipeline PaddleOCR VL 1.5 (94.37).
Key Takeaways
- Unified Early-Fusion Structure: Falcon Notion replaces modular encoder-decoder pipelines with a single dense Transformer that processes picture patches and textual content tokens in a shared parameter house from the primary layer. It makes use of a hybrid consideration masks—bidirectional for visible tokens and causal for job tokens—to behave concurrently as a imaginative and prescient encoder and an autoregressive decoder.
- Chain-of-Notion Sequence: The mannequin serializes occasion segmentation right into a structured sequence , which forces it to resolve spatial place and measurement as a conditioning sign earlier than producing the pixel-level masks.
- Specialised Heads and GGROPE: To handle dense spatial information, the mannequin makes use of Fourier Characteristic encoders for high-dimensional coordinate mapping and Golden Gate ROPE (GGROPE) to allow isotropic 2D spatial consideration. The Muon optimizer is employed for these specialised heads to steadiness studying charges towards the pre-trained spine.
- Semantic Efficiency Good points: On the brand new PBench benchmark, which disentangles semantic capabilities (Ranges 0-4), the 600M mannequin demonstrates important positive factors over SAM 3 in complicated classes, together with a +13.4 level lead in OCR-guided queries and a +21.9 level lead in spatial understanding.
- Excessive-Effectivity OCR Extension: The structure scales all the way down to Falcon OCR, a 300M-parameter mannequin that achieves 80.3% on olmOCR and 88.64 on OmniDocBench. It matches or exceeds the accuracy of a lot bigger techniques like Gemini 3 Professional and GPT 5.2 whereas sustaining excessive throughput for large-scale doc processing.
Try the Paper, Mannequin Weight, Repo and Technical particulars. Additionally, be at liberty to observe us on Twitter and don’t overlook to hitch our 120k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you may be part of us on telegram as properly.

