

Expertise Innovation Institute (TII), Abu Dhabi, has launched Falcon-H1R-7B, a 7B parameter reasoning specialised mannequin that matches or exceeds many 14B to 47B reasoning fashions in math, code and basic benchmarks, whereas staying compact and environment friendly. It builds on Falcon H1 7B Base and is out there on Hugging Face beneath the Falcon-H1R assortment.
Falcon-H1R-7B is attention-grabbing as a result of it combines 3 design selections in 1 system, a hybrid Transformer together with Mamba2 spine, a really lengthy context that reaches 256k tokens in normal vLLM deployments, and a coaching recipe that mixes supervised lengthy type reasoning with reinforcement studying utilizing GRPO.
Hybrid Transformer plus Mamba2 structure with lengthy context
Falcon-H1R-7B is a causal decoder solely mannequin with a hybrid structure that mixes Transformer layers and Mamba2 state house parts. The Transformer blocks present normal consideration based mostly reasoning, whereas the Mamba2 blocks give linear time sequence modeling and higher reminiscence scaling as context size grows. This design targets the three axes of reasoning effectivity that the staff describes, velocity, token effectivity and accuracy.
The mannequin runs with a default --max-model-len of 262144 when served by means of vLLM, which corresponds to a sensible 256k token context window. This permits very lengthy chain of thought traces, multi step device use logs and huge multi doc prompts in a single cross. The hybrid spine helps management reminiscence use at these sequence lengths and improves throughput in contrast with a pure Transformer 7B baseline on the identical {hardware}.
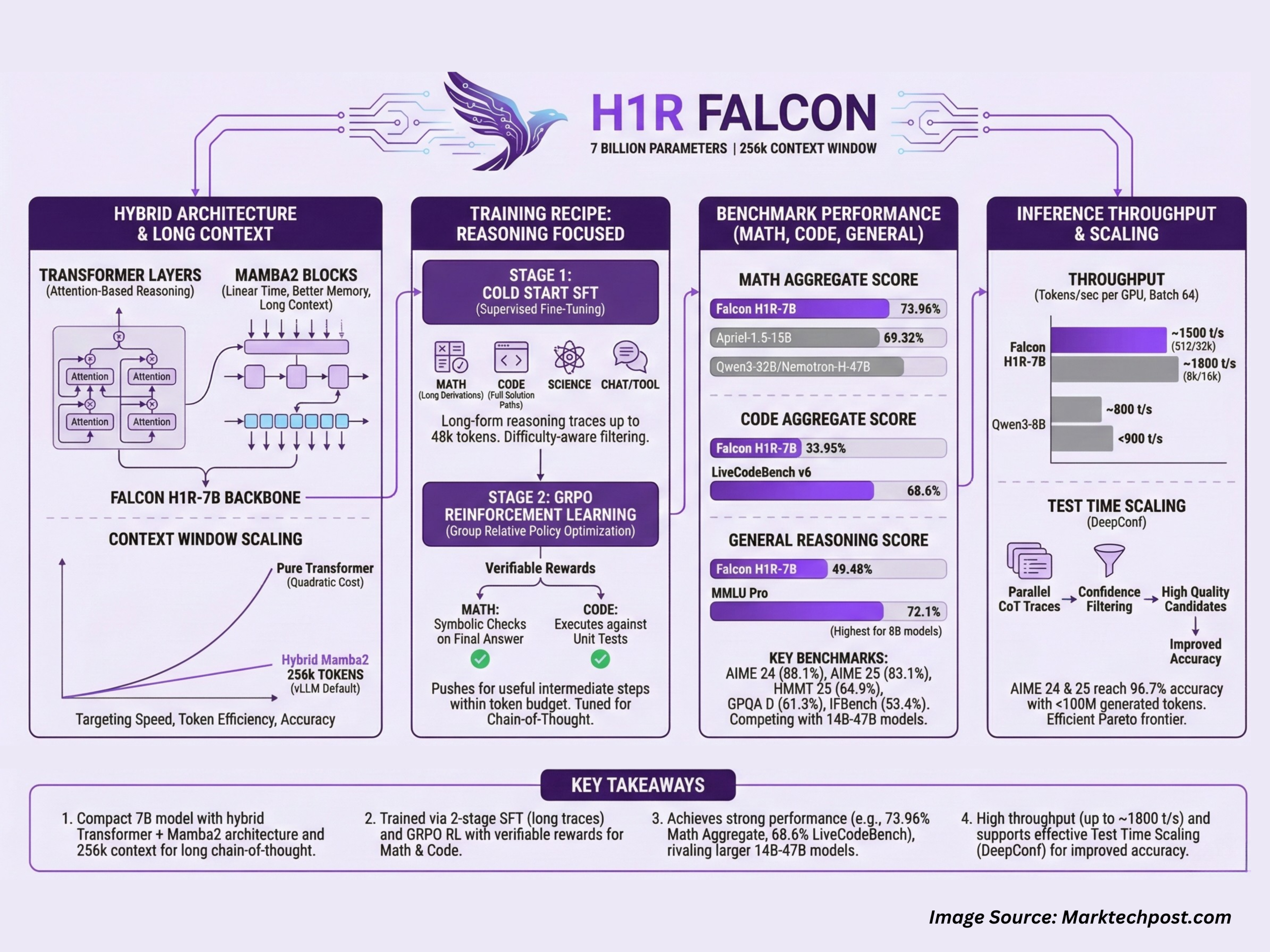
Coaching recipe for reasoning duties
Falcon H1R 7B makes use of a 2 stage coaching pipeline:
Within the first stage, the staff runs chilly begin supervised high quality tuning on high of Falcon-H1-7B Base. The SFT (supervised high quality tuning) knowledge mixes step-by-step lengthy type reasoning traces in 3 primary domains, arithmetic, coding and science, plus non reasoning domains reminiscent of chat, device calling and security. Problem conscious filtering upweights more durable issues and downweights trivial ones. Targets can attain as much as 48k tokens, so the mannequin sees lengthy derivations and full answer paths throughout coaching.
Within the second stage, the SFT checkpoint is refined with GRPO, which is a bunch relative coverage optimization methodology for reinforcement studying. Rewards are given when the generated reasoning chain is verifiably appropriate. For math issues, the system makes use of symbolic checks on the ultimate reply. For code, it executes the generated program in opposition to unit checks. This RL stage pushes the mannequin to maintain helpful intermediate steps whereas staying inside a token funds.
The result’s a 7B mannequin that’s tuned particularly for chain of thought reasoning, quite than basic chat.
Benchmarks in math, coding and basic reasoning
The Falcon-H1R-7B benchmark scores are grouped throughout math, code and agentic duties, and basic reasoning duties.
Within the math group, Falcon-H1R-7B reaches an combination rating of 73.96%, forward of Apriel-1.5-15B at 69.32% and bigger fashions like Qwen3-32B and Nemotron-H-47B. On particular person benchmarks:
- AIME 24, 88.1%, larger than Apriel-1.5-15B at 86.2%
- AIME 25, 83.1%, larger than Apriel-1.5-15B at 80%
- HMMT 25, 64.9%, above all listed baselines
- AMO Bench, 36.3%, in contrast with 23.3% for DeepSeek-R1-0528 Qwen3-8B
For code and agentic workloads, the mannequin reaches 33.95% as a bunch rating. On LiveCodeBench v6, Falcon-H1R-7B scores 68.6%, which is larger than Qwen3-32B and different baselines. It additionally scores 28.3% on the SciCode sub downside benchmark and 4.9% on Terminal Bench Exhausting, the place it ranks second behind Apriel 1.5-15B however forward of a number of 8B and 32B programs.

On basic reasoning, Falcon-H1R-7B achieves 49.48% as a bunch rating. It data 61.3% on GPQA D, near different 8B fashions, 72.1% on MMLU Professional, which is larger than all different 8B fashions within the above desk, 11.1% on HLE and 53.4% on IFBench, the place it’s second solely to Apriel 1.5 15B.
The important thing takeaway is {that a} 7B mannequin can sit in the identical efficiency band as many 14B to 47B reasoning fashions, if the structure and coaching pipeline are tuned for reasoning duties.
Inference throughput and check time scaling
The staff additionally benchmarked Falcon-H1R-7B on throughput and check time scaling beneath reasonable batch settings.
For a 512 token enter and 32k token output, Falcon-H1R-7B reaches about 1,000 tokens per second per GPU at batch dimension 32 and about 1,500 tokens per second per GPU at batch dimension 64, practically double the throughput of Qwen3-8B in the identical configuration. For an 8k enter and 16k output, Falcon-H1R-7B reaches round 1,800 tokens per second per GPU, whereas Qwen3-8B stays under 900. The hybrid Transformer together with Mamba structure is a key issue on this scaling habits, as a result of it reduces the quadratic value of consideration for lengthy sequences.
Falcon-H1R-7B can also be designed for check time scaling utilizing Deep Assume with confidence, often called DeepConf. The thought is to run many chains of thought in parallel, then use the mannequin’s personal subsequent token confidence scores to filter noisy traces and maintain solely prime quality candidates.
On AIME 24 and AIME 25, Falcon-H1R-7B reaches 96.7% accuracy with fewer than 100 million generated tokens, which places it on a positive Pareto frontier of accuracy versus token value in contrast with different 8B, 14B and 32B reasoning fashions. On the parser verifiable subset of AMO Bench, it reaches 35.9% accuracy with 217 million tokens, once more forward of the comparability fashions at related or bigger scale.
Key Takeaways
- Falcon-H1R-7B is a 7B parameter reasoning mannequin that makes use of a hybrid Transformer together with Mamba2 structure and helps a 256k token context for lengthy chain of thought prompts.
- The mannequin is skilled in 2 levels, supervised high quality tuning on lengthy reasoning traces in math, code and science as much as 48k tokens, adopted by GRPO based mostly reinforcement studying with verifiable rewards for math and code.
- Falcon-H1R-7B achieves robust math efficiency, together with about 88.1% on AIME 24, 83.1% on AIME 25 and a 73.96% combination math rating, which is aggressive with or higher than bigger 14B to 47B fashions.
- On coding and agentic duties, Falcon-H1R-7B obtains 33.95% as a bunch rating and 68.6% on LiveCodeBench v6, and it’s also aggressive on basic reasoning benchmarks reminiscent of MMLU Professional and GPQA D.
- The hybrid design improves throughput, reaching round 1,000 to 1,800 tokens per second per GPU within the reported settings, and the mannequin helps check time scaling by means of Deep Assume with confidence to enhance accuracy utilizing a number of reasoning samples beneath a managed token funds.
Take a look at the Technical particulars and MODEL WEIGHTS right here. Additionally, be at liberty to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be part of us on telegram as nicely.
Take a look at our newest launch of ai2025.dev, a 2025-focused analytics platform that turns mannequin launches, benchmarks, and ecosystem exercise right into a structured dataset you’ll be able to filter, evaluate, and export
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

