

Picture by Writer
# Introduction
For many years, synthetic intelligence (AI) meant textual content. You typed a query, obtained a textual content response. At the same time as language fashions grew extra succesful, the interface stayed the identical: a textual content field ready on your rigorously crafted immediate.
That is altering. At present’s most succesful AI methods do not simply learn. They see photos, hear speech, course of video, and perceive structured information. This is not incremental progress; it is a elementary shift in how we work together with and construct AI functions.
Welcome to multimodal AI.
The true affect is not simply that fashions can course of extra information sorts. It is that complete workflows are collapsing. Duties that after required a number of conversion steps — picture to textual content description, speech to transcript, diagram to rationalization — now occur straight. AI understands info in its native type, eliminating the interpretation layer that is outlined human-computer interplay for many years.
# Defining Multimodal Synthetic Intelligence: From Single-Sense to Multi-Sense Intelligence
Multimodal AI refers to methods that may course of and generate a number of kinds of information (modalities) concurrently. This contains not simply textual content, however photos, audio, video, and more and more, 3D spatial information, structured databases, and domain-specific codecs like molecular buildings or musical notation.
The breakthrough wasn’t simply making fashions greater. It was studying to symbolize several types of information in a shared “understanding area” the place they’ll work together. A picture and its caption aren’t separate issues that occur to be associated; they’re totally different expressions of the identical underlying idea, mapped into a standard illustration.
This creates capabilities that single-modality methods cannot obtain. A text-only AI can describe a photograph if you happen to clarify it in phrases. A multimodal AI can see the photograph and perceive context you by no means talked about: the lighting, the feelings on faces, the spatial relationships between objects. It does not simply course of a number of inputs; it synthesizes understanding throughout them.
The excellence between “really multimodal” fashions and “multi-modal methods” issues. Some fashions course of all the things collectively in a single unified structure. GPT-4 Imaginative and prescient (GPT-4V) sees and understands concurrently. Others join specialised fashions: a imaginative and prescient mannequin analyzes a picture, then passes outcomes to a language mannequin for reasoning. Each approaches work. The previous gives tighter integration, whereas the latter gives extra flexibility and specialization.
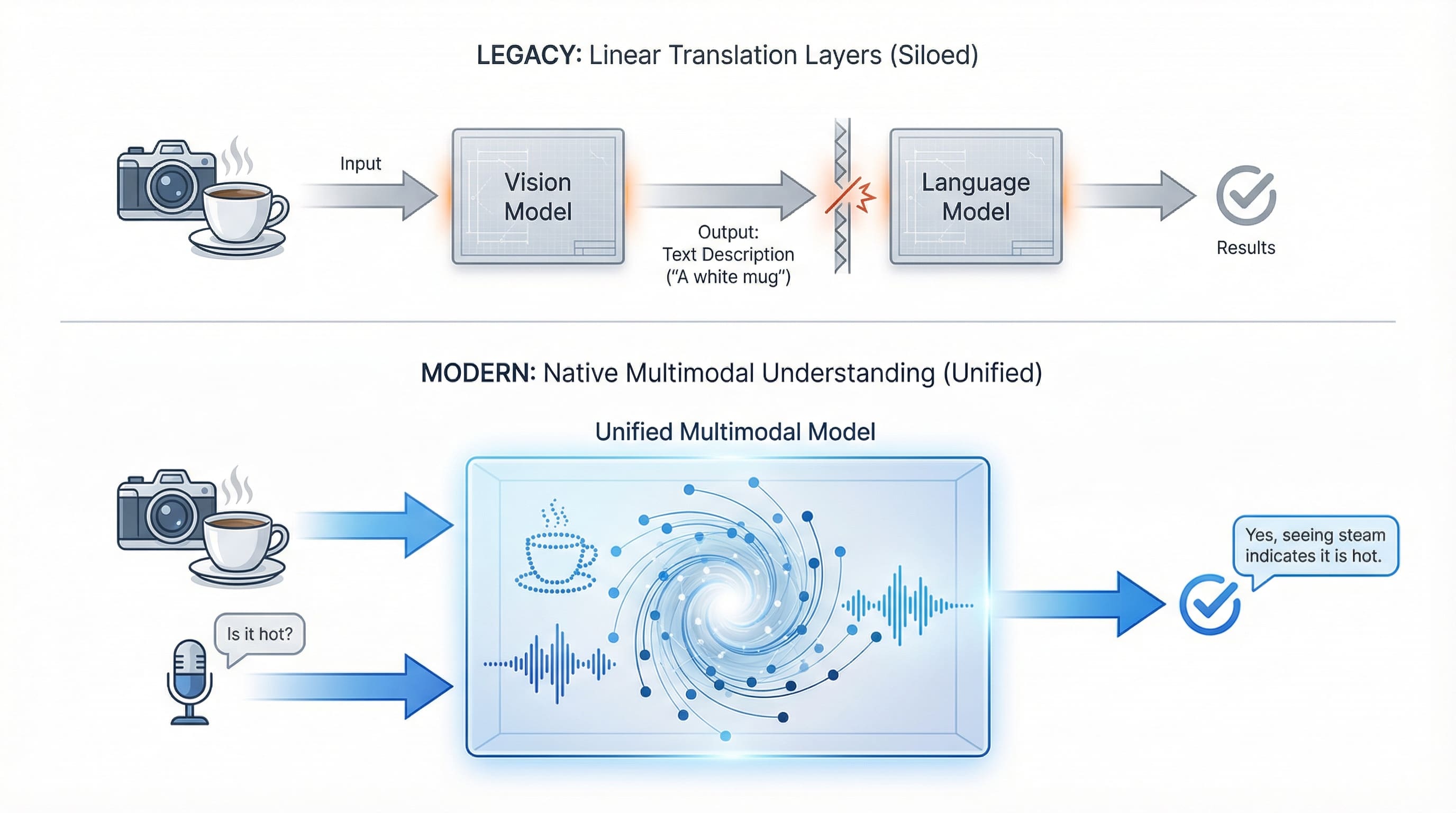
Legacy methods require translation between specialised fashions, whereas trendy multimodal AI processes imaginative and prescient and voice concurrently in a unified structure. | Picture by Writer
# Understanding the Basis Trio: Imaginative and prescient, Voice, and Textual content Fashions
Three modalities have matured sufficient for widespread manufacturing use, every bringing distinct capabilities and distinct engineering constraints to AI methods.
// Advancing Visible Understanding
Imaginative and prescient AI has advanced from primary picture classification to real visible understanding. GPT-4V and Claude can analyze charts, debug code from screenshots, and perceive complicated visible context. Gemini integrates imaginative and prescient natively throughout its complete interface. The open-source options — LLaVA, Qwen-VL, and CogVLM — now rival business choices in lots of duties whereas working on shopper {hardware}.
Here is the place the workflow shift turns into apparent: as a substitute of describing what you see in a screenshot or manually transcribing chart information, you simply present it. The AI sees it straight. What used to take 5 minutes of cautious description now takes 5 seconds of add.
The engineering actuality, nevertheless, imposes constraints. You usually cannot stream uncooked 60fps video to a big language mannequin (LLM). It is too sluggish and costly. Manufacturing methods use body sampling, extracting keyframes (maybe one each two seconds) or deploying light-weight “change detection” fashions to solely ship frames when the visible scene shifts.
What makes imaginative and prescient succesful is not simply recognizing objects. It is spatial reasoning: understanding that the cup is on the desk, not floating. It is studying implicit info: recognizing {that a} cluttered desk suggests stress, or {that a} graph’s development contradicts the accompanying textual content. Imaginative and prescient AI excels at doc evaluation, visible debugging, picture era, and any job the place “present, do not inform” applies.
// Evolving Voice and Audio Interplay
Voice AI extends past easy transcription. Whisper modified the sector by making high-quality speech recognition free and native. It handles accents, background noise, and multilingual audio with exceptional reliability. However voice AI now contains text-to-speech (TTS) through ElevenLabs, Bark, or Coqui, together with emotion detection and speaker identification.
Voice collapses one other conversion bottleneck: you converse naturally as a substitute of typing out what you meant to say. The AI hears your tone, catches your hesitation, and responds to what you meant, not simply the phrases you managed to sort.
The frontier problem is not transcription high quality; it is latency and turn-taking. In real-time dialog, ready three seconds for a response feels unnatural. Engineers remedy this with voice exercise detection (VAD), algorithms that detect the exact millisecond a consumer stops talking to set off the mannequin instantly, plus “barge-in” help that lets customers interrupt the AI mid-response.
The excellence between transcription and understanding issues. Whisper converts speech to textual content with spectacular accuracy. Nevertheless, newer voice fashions grasp tone, detect sarcasm, determine hesitation, and perceive context that textual content alone misses. A buyer saying “high-quality” with frustration differs from “high-quality” with satisfaction. Voice AI captures that distinction.
// Synthesizing with Textual content Integration
Textual content integration serves because the glue binding all the things collectively. Language fashions present reasoning, synthesis, and era capabilities that different modalities lack. A imaginative and prescient mannequin can determine objects in a picture; an LLM explains their significance. An audio mannequin can transcribe speech; an LLM extracts insights from the dialog.
The potential comes from mixture. Present an AI a medical scan whereas describing signs, and it synthesizes understanding throughout modalities. This goes past parallel processing; it is real multi-sense reasoning the place every modality informs interpretation of the others.
# Exploring Rising Frontiers Past the Fundamentals
Whereas imaginative and prescient, voice, and textual content dominate present functions, the multimodal panorama is increasing quickly.
3D and spatial understanding strikes AI past flat photos into bodily area. Fashions that grasp depth, three-dimensional relationships, and spatial reasoning allow robotics, augmented actuality (AR), digital actuality (VR) functions, and structure instruments. These methods perceive {that a} chair considered from totally different angles is similar object.
Structured information as a modality represents a delicate however vital evolution. Slightly than changing spreadsheets to textual content for LLMs, newer methods perceive tables, databases, and graphs natively. They acknowledge {that a} column represents a class, that relationships between tables carry which means, and that time-series information has temporal patterns. This lets AI question databases straight, analyze monetary statements with out prompting, and motive about structured info with out lossy conversion to textual content.
When AI understands native codecs, totally new capabilities seem. A monetary analyst can level at a spreadsheet and ask “why did income drop in Q3?” The AI reads the desk construction, spots the anomaly, and explains it. An architect can feed in 3D fashions and get spatial suggestions with out changing all the things to 2D diagrams first.
Area-specific modalities goal specialised fields. AlphaFold‘s potential to grasp protein buildings opened drug discovery to AI. Fashions that comprehend musical notation allow composition instruments. Methods that course of sensor information and time-series info carry AI to the web of issues (IoT) and industrial monitoring.
# Implementing Actual-World Purposes
Multimodal AI has moved from analysis papers to manufacturing methods fixing actual issues.
- Content material evaluation: Video platforms use imaginative and prescient to detect scenes, audio to transcribe dialogue, and textual content fashions to summarize content material. Medical imaging methods mix visible evaluation of scans with affected person historical past and symptom descriptions to help prognosis.
- Accessibility instruments: Actual-time signal language translation combines imaginative and prescient (seeing gestures) with language fashions (producing textual content or speech). Picture description providers assist visually impaired customers perceive visible content material.
- Inventive workflows: Designers sketch interfaces that AI converts to code whereas explaining design selections verbally. Content material creators describe ideas in speech whereas AI generates matching visuals.
- Developer instruments: Debugging assistants see your display, learn error messages, and clarify options verbally. Code evaluation instruments analyze each code construction and related diagrams or documentation.
The transformation exhibits up in how individuals work: as a substitute of context-switching between instruments, you simply present and ask. The friction disappears. Multimodal approaches let every info sort stay in its native type.
The problem in manufacturing is usually much less about functionality and extra about latency. Voice-to-voice methods should course of audio → textual content → reasoning → textual content → audio in beneath 500ms to really feel pure, requiring streaming architectures that course of information in chunks.
# Navigating the Rising Multimodal Infrastructure
A brand new infrastructure layer is forming round multimodal growth:
- Mannequin Suppliers: OpenAI, Anthropic, and Google lead business choices. Open-source initiatives just like the LLaVA household and Qwen-VL democratize entry.
- Framework Help: LangChain added multimodal chains for processing mixed-media workflows. LlamaIndex extends retrieval-augmented era (RAG) patterns to pictures and audio.
- Specialised Suppliers: ElevenLabs dominates voice synthesis, whereas Midjourney and Stability AI lead picture era.
- Integration Protocols: The Mannequin Context Protocol (MCP) is standardizing how AI methods hook up with multimodal information sources.
The infrastructure is democratizing multimodal AI. What required analysis groups years in the past now runs in framework code. What price 1000’s in API charges now runs regionally on shopper {hardware}.
# Summarizing Key Takeaways
Multimodal AI represents greater than technical functionality; it is altering how people and computer systems work together. Graphical consumer interfaces (GUIs) are giving technique to multimodal interfaces the place you present, inform, draw, and converse naturally.
This permits new interplay patterns like visible grounding. As an alternative of typing “what’s that crimson object within the nook?”, customers draw a circle on their display and ask “what is that this?” The AI receives each picture coordinates and textual content, anchoring language in visible pixels.
The way forward for AI is not selecting between imaginative and prescient, voice, or textual content. It is constructing methods that perceive all three as naturally as people do.
Vinod Chugani is an AI and information science educator who bridges the hole between rising AI applied sciences and sensible software for working professionals. His focus areas embody agentic AI, machine studying functions, and automation workflows. By means of his work as a technical mentor and teacher, Vinod has supported information professionals via ability growth and profession transitions. He brings analytical experience from quantitative finance to his hands-on educating strategy. His content material emphasizes actionable methods and frameworks that professionals can apply instantly.

