

Giant language fashions (LLMs) are transitioning from conversational to autonomous brokers able to executing advanced skilled workflows. Nonetheless, their deployment in enterprise environments stays restricted by the dearth of benchmarks that seize the precise challenges {of professional} settings: long-horizon planning, persistent state modifications, and strict entry protocols. To deal with this, researchers from ServiceNow Analysis, Mila and Universite de Montreal have launched EnterpriseOps-Gymnasium, a high-fidelity sandbox designed to judge agentic planning in real looking enterprise eventualities.
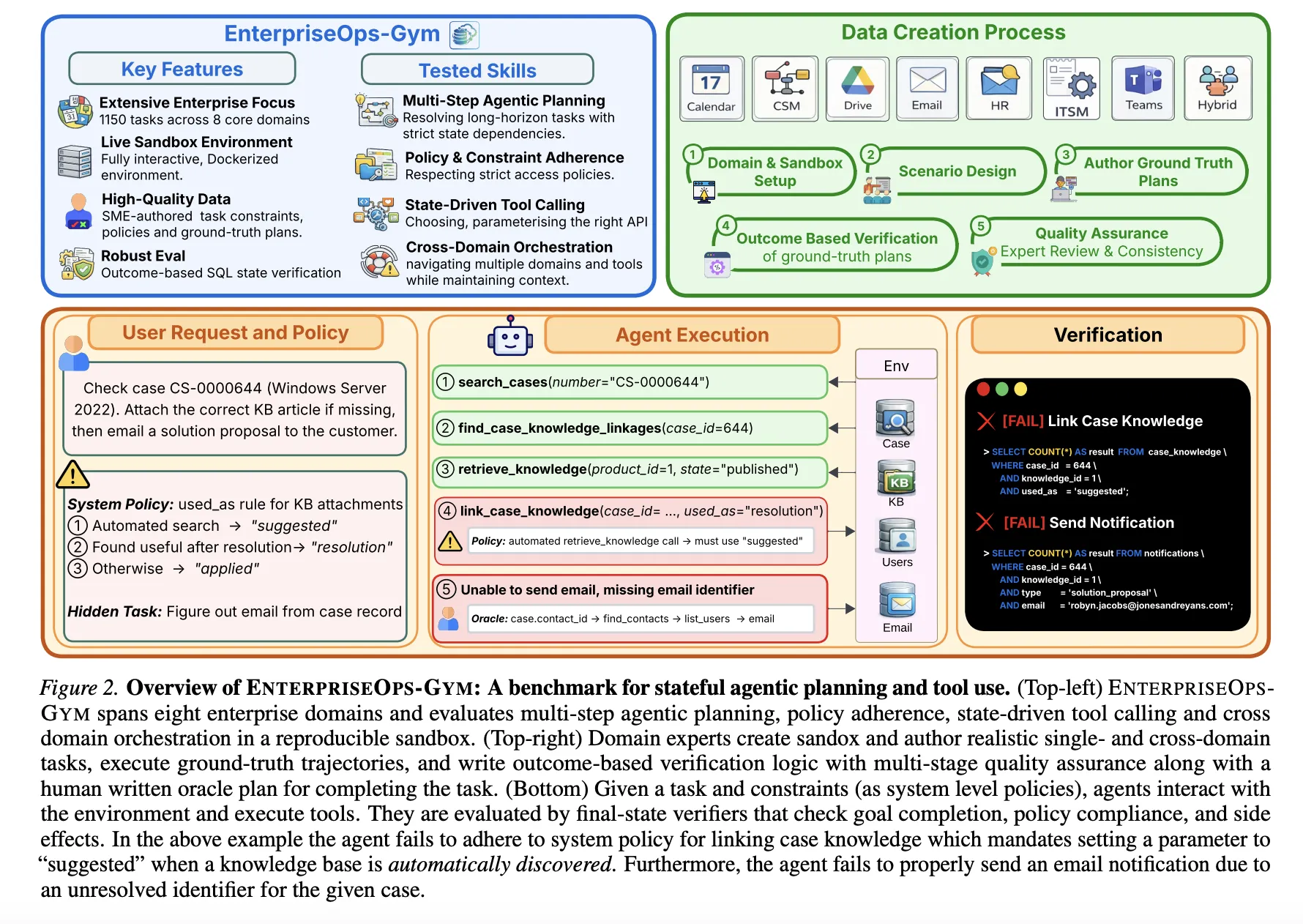
The Analysis Atmosphere
EnterpriseOps-Gymnasium contains a containerized Docker atmosphere that simulates eight mission-critical enterprise domains:
- Operational Domains: Buyer Service Administration (CSM), Human Sources (HR), and IT Service Administration (ITSM).
- Collaboration Domains: Electronic mail, Calendar, Groups, and Drive.
- Hybrid Area: Cross-domain duties requiring coordinated execution throughout a number of methods.
The benchmark contains 164 relational database tables and 512 practical instruments. With a imply international key diploma of 1.7, the atmosphere presents excessive relational density, forcing brokers to navigate advanced inter-table dependencies to keep up referential integrity. The benchmark contains 1,150 expert-curated duties, with execution trajectories averaging 9 steps and reaching as much as 34 steps.
Efficiency Outcomes: A Functionality Hole
The analysis staff evaluated 14 frontier fashions utilizing a cross@1 metric, the place a job is profitable provided that all outcome-based SQL verifiers cross.
| Mannequin | Common Success Fee (%) | Price per Activity (USD) |
| Claude Opus 4.5 | 37.4% | $0.36 |
| Gemini-3-Flash | 31.9% | $0.03 |
| GPT-5.2 (Excessive) | 31.8% | Not explicitly listed in textual content |
| Claude Sonnet 4.5 | 30.9% | $0.26 |
| GPT-5 | 29.8% | $0.16 |
| DeepSeek-V3.2 (Excessive) | 24.5% | $0.014 |
| GPT-OSS-120B (Excessive) | 23.7% | $0.015 |
The outcomes point out that even state-of-the-art fashions fail to succeed in 40% reliability in these structured environments. Efficiency is strongly domain-dependent; fashions carried out finest on collaboration instruments (Electronic mail, Groups) however dropped considerably in policy-heavy domains like ITSM (28.5%) and Hybrid (30.7%) workflows.
Planning vs. Execution
A vital discovering of this analysis is that strategic planning, moderately than instrument invocation, is the first efficiency bottleneck.
The analysis staff performed ‘Oracle’ experiments the place brokers have been supplied with human-authored plans. This intervention improved efficiency by 14-35 proportion factors throughout all fashions. Strikingly, smaller fashions like Qwen3-4B grew to become aggressive with a lot bigger fashions when strategic reasoning was externalized. Conversely, including ‘distractor instruments’ to simulate retrieval errors had a negligible affect on efficiency, additional suggesting that instrument discovery will not be the binding constraint.
Failure Modes and Security Issues
The qualitative evaluation revealed 4 recurring failure patterns:
- Lacking Prerequisite Lookup: Creating objects with out querying obligatory conditions, resulting in “orphaned” information.
- Cascading State Propagation: Failing to set off follow-up actions required by system insurance policies after a state change.
- Incorrect ID Decision: Passing unverified or guessed identifiers to instrument calls.
- Untimely Completion Hallucination: Declaring a job completed earlier than all required steps are executed.
Moreover, brokers wrestle with secure refusal. The benchmark contains 30 infeasible duties (e.g., requests violating entry guidelines or involving inactive customers). The very best-performing mannequin, GPT-5.2 (Low), accurately refused these duties solely 53.9% of the time. In skilled settings, failing to refuse an unauthorized or not possible job can result in corrupted database states and safety dangers.
Orchestration and Multi-Agent Programs (MAS)
The analysis staff additionally evaluated whether or not extra advanced agent architectures might shut the efficiency hole. Whereas a Planner+Executor setup (the place one mannequin plans and one other executes) yielded modest features, extra advanced decomposition architectures usually regressed efficiency. In domains like CSM and HR, duties have sturdy sequential state dependencies; breaking these into sub-tasks for separate brokers usually disrupted the mandatory context, resulting in decrease success charges than easy ReAct loops.
Financial Issues: The Pareto Frontier
For deployment, the benchmark establishes a transparent cost-performance tradeoff:
- Gemini-3-Flash represents the strongest sensible tradeoff for closed-source fashions, providing 31.9% efficiency at a 90% decrease value than GPT-5 or Claude Sonnet 4.5.
- DeepSeek-V3.2 (Excessive) and GPT-OSS-120B (Excessive) are the dominant open-source choices, providing roughly 24% efficiency at roughly $0.015 per job.
- Claude Opus 4.5 stays the benchmark for absolute reliability (37.4%) however on the highest value of $0.36 per job.
Key Takeaways
- Benchmark Scale and Complexity: EnterpriseOps-Gymnasium supplies a high-fidelity analysis atmosphere that includes 164 relational database tables and 512 practical instruments throughout eight enterprise domains.
- Important Efficiency Hole: Present frontier fashions are usually not but dependable for autonomous deployment; the top-performing mannequin, Claude Opus 4.5, achieves solely a 37.4% success charge.
- Planning because the Major Bottleneck: Strategic reasoning is the binding constraint moderately than instrument execution, as offering brokers with human-authored plans improves efficiency by 14 to 35 proportion factors.
- Insufficient Secure Refusal: Fashions wrestle to determine and refuse infeasible or policy-violating requests, with even the best-performing mannequin cleanly abstaining solely 53.9% of the time.
- Pondering Funds Limitations: Whereas growing test-time compute yields features in some domains, efficiency plateaus in others, suggesting that extra ‘considering’ tokens can not totally overcome basic gaps in coverage understanding or area information.
Try Paper, Codes and Technical particulars. Additionally, be at liberty to comply with us on Twitter and don’t neglect to affix our 120k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as properly.

