

Introduction
The Clarifai platform has advanced considerably. Earlier generations of the platform relied on many small, task-specific fashions for visible classification, detection, OCR, textual content classification and segmentation. These legacy fashions had been constructed on older architectures that had been delicate to area shift, required separate coaching pipelines and didn’t generalize nicely outdoors their unique circumstances.
The ecosystem has moved on. Trendy giant language fashions and vision-language fashions are educated on broader multimodal knowledge, cowl a number of duties inside a single mannequin household and ship extra secure efficiency throughout completely different enter varieties. As a part of the platform improve, we’re standardizing round these newer mannequin varieties.
With this replace, a number of legacy task-specific fashions are being deprecated and can now not be obtainable. Their performance remains to be totally supported on the platform, however is now offered by extra succesful and common mannequin households. Compute Orchestration manages scheduling, scaling and useful resource allocation for these fashions in order that workloads behave constantly throughout open supply and customized mannequin deployments.
This weblog outlines the core process classes supported at present, the beneficial fashions for every and how one can use them throughout the platform. It additionally clarifies which older fashions are being retired and the way their capabilities map to the present mannequin households.
Really useful Fashions for Core Imaginative and prescient and NLP Duties
Visible Classification and Recognition
Visible classification and recognition contain figuring out objects, scenes and ideas in a picture. These duties energy product tagging, content material moderation, semantic search, retrieval indexing and common scene understanding.
Trendy vision-language fashions deal with these duties nicely in zero-shot mode. As a substitute of coaching separate classifiers, you outline the taxonomy within the immediate and the mannequin returns labels immediately, which reduces the necessity for task-specific coaching and simplifies updates.
Fashions on the platform suited to visible classification, recognition and moderation
The fashions beneath supply robust visible understanding and carry out nicely for classification, recognition, idea extraction and picture moderation workflows, together with sensitive-safety taxonomy setups.
MiniCPM-o 2.6
A compact VLM that handles photos, video and textual content. Performs nicely for versatile classification workloads the place pace, price effectivity and protection must be balanced.
Qwen2.5-VL-7B-Instruct
Optimized for visible recognition, localized reasoning and structured visible understanding. Sturdy at figuring out ideas in photos with a number of objects and extracting structured data.
Moderation with MM-Poly-8B
A big portion of real-world visible classification work includes moderation. Many buyer workloads are constructed round figuring out whether or not a picture is secure, delicate or banned in response to a particular coverage. Not like common classification, moderation requires strict taxonomy, conservative thresholds and constant rule-following. That is the place MM-Poly-8B is especially efficient.
MM-Poly-8B is Clarifai’s multimodal mannequin designed for detailed, prompt-driven evaluation throughout photos, textual content, audio and video. It performs nicely when the classification logic must be specific and tightly managed. Moderation groups typically depend on layered directions, examples and edge-case dealing with. MM-Poly-8B helps this sample immediately and behaves predictably when given structured insurance policies or rule units.
Key capabilities:
Accepts picture, textual content, audio and video inputs
Handles detailed taxonomies and multi-level determination logic
Helps example-driven prompting
Produces constant classifications for safety-critical use circumstances
Works nicely when the moderation coverage requires conservative interpretation and bias towards security
As a result of MM-Poly-8B is tuned to observe directions faithfully, it’s suited to moderation situations the place false negatives carry larger threat and fashions should err on the aspect of warning. It may be prompted to categorise content material utilizing your coverage, establish violations, return structured reasoning or generate confidence-based outputs.
If you wish to show a moderation workflow, you possibly can immediate the mannequin with a transparent taxonomy and ruleset. For instance:
“Consider this picture in response to the classes Secure, Suggestive, Express, Drug and Gore. Apply a strict security coverage and classify the picture into essentially the most applicable class.”
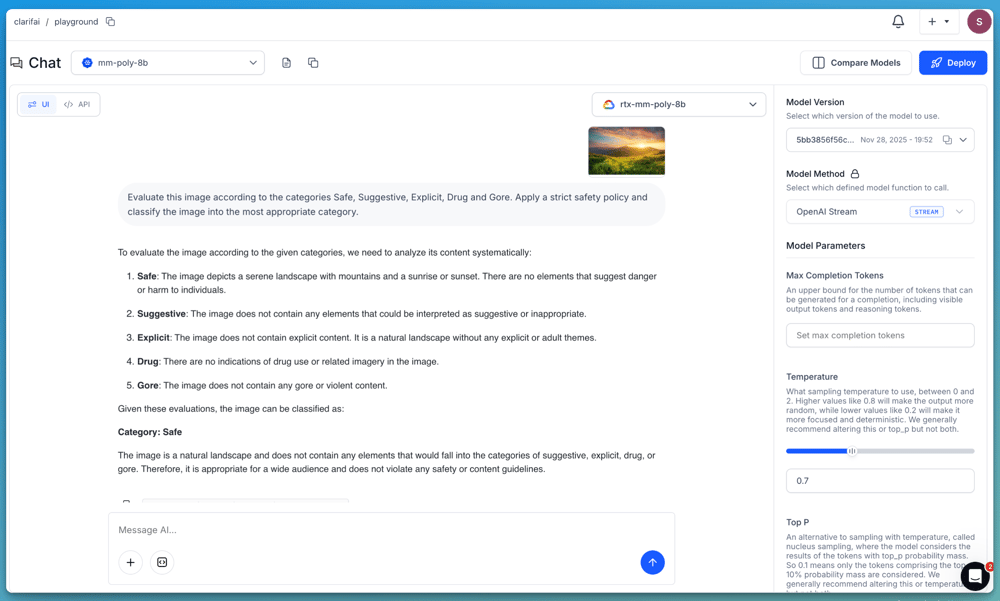
For extra superior use circumstances, you possibly can present the mannequin with an in depth set of moderation guidelines, determination standards and examples that outline how every class ought to be utilized. This lets you confirm how mannequin behaves below stricter, policy-driven circumstances and the way it may be built-in into production-grade moderation pipelines.
MM-Poly-8B is out there on the platform and can be utilized by the Playground or accessed programmatically by way of the OpenAI-compatible API.
Notice: If you wish to entry the above fashions like MiniCPM-o-2.6 and Qwen2.5-VL-7B-Instruct immediately, you possibly can deploy them to your individual devoted compute utilizing the Platform and entry them by way of API similar to another mannequin.
Tips on how to entry these fashions
All fashions described above could be accessed by Clarifai’s OpenAI-compatible API. Ship a picture and a immediate in a single request and obtain both plain textual content or structured JSON, which is beneficial while you want constant labels or need to feed the outcomes into downstream pipelines.
For particulars on structured JSON output, test the documentation right here.
Coaching your individual classifier (fine-tuning)
In case your utility requires domain-specific labels, industry-specific ideas or a dataset that differs from common internet imagery, you possibly can prepare a customized classifier utilizing Clarifai’s visible classification templates. These templates present configurable coaching pipelines with adjustable hyperparameters, permitting you to construct fashions tailor-made to your use case.
Accessible templates embrace:
MMClassification ResNet 50 RSB A1
Clarifai InceptionBatchNorm
Clarifai InceptionV2
Clarifai ResNeXt
Clarifai InceptionTransferEmbedNorm
You may add your dataset, configure hyperparameters and prepare your individual classifier by the UI or API. Try the Nice-tuning Information on the platform.
Doc Intelligence and OCR
Doc intelligence covers OCR, structure understanding and structured subject extraction throughout scanned pages, kinds and text-heavy photos. The legacy OCR pipeline on the platform relied on language-specific PaddleOCR variants. These fashions had been slim in scope, delicate to formatting points and required separate upkeep for every language. They’re now being decommissioned.
Fashions being decommissioned
These fashions had been single-language engines with restricted robustness. Trendy OCR and multimodal methods help multilingual extraction by default and deal with noisy scans, blended codecs and paperwork that mix textual content and visible components with out requiring separate pipelines.
Open-source OCR mannequin on the platform
DeepSeek OCR
DeepSeek OCR is the first open-source possibility. It helps multilingual paperwork, processes noisy scans moderately nicely and might deal with structured and unstructured paperwork. Nevertheless, it’s not excellent. Benchmarks present inconsistent accuracy on messy handwriting, irregular layouts and low-resolution scans. It additionally has enter measurement constraints that may restrict efficiency on giant paperwork or multi-page flows. Whereas it’s stronger than the sooner language-specific engines, it’s not the best choice for high-stakes extraction on advanced paperwork.
Third-party multimodal fashions for OCR-style duties
The platform additionally helps a number of multimodal fashions that mix OCR with visible reasoning. These fashions can extract textual content, interpret tables, establish key fields and summarize content material even when construction is advanced. They’re extra succesful than DeepSeek OCR, particularly for lengthy paperwork or workflows requiring reasoning.
Gemini 2.5 Professional
Handles text-heavy paperwork, receipts, kinds and sophisticated layouts with robust multimodal reasoning.
Claude Opus 4.5
Performs nicely on dense, advanced paperwork, together with desk interpretation and structured extraction.
Claude Sonnet 4.5
A sooner possibility that also produces dependable subject extraction and summarization for scanned pages.
GPT-5.1
Reads paperwork, extracts fields, interprets tables and summarizes multi-section pages with robust semantic accuracy.
Gemini 2.5 Flash
Light-weight and optimized for pace. Appropriate for widespread kinds, receipts and easy doc extraction.
These fashions carry out nicely throughout languages, deal with advanced layouts and perceive doc context. The tradeoffs matter. They’re closed-source, require third-party inference and are costlier to function at scale in comparison with an open-source OCR engine. They are perfect for high-accuracy extraction and reasoning, however not at all times cost-efficient for big batch OCR workloads.
Tips on how to entry these fashions
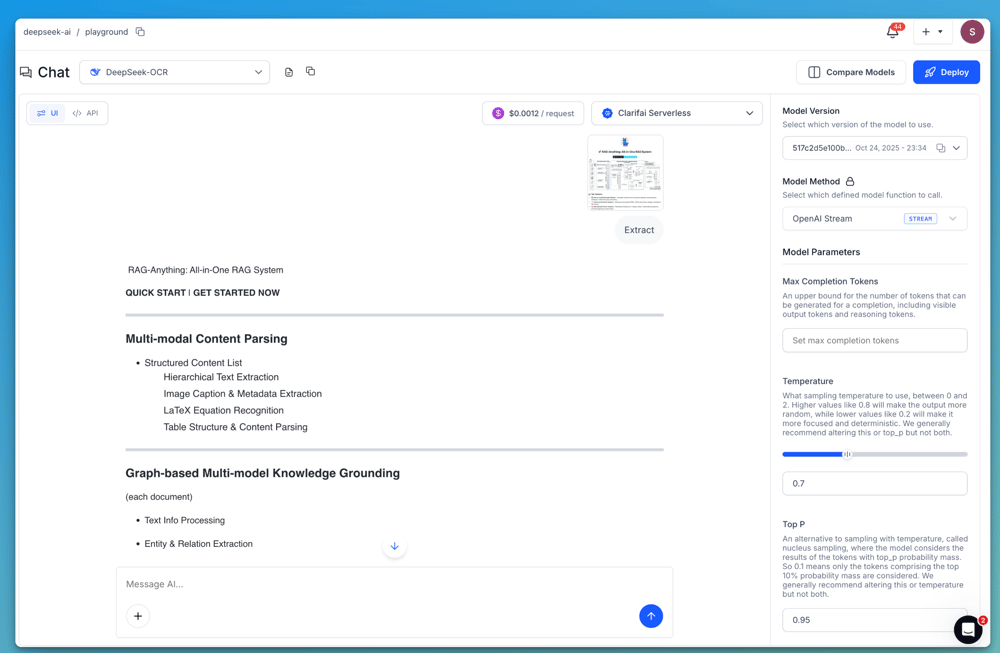
Utilizing the Playground
Add your doc picture or scanned web page within the Playground and run it with DeepSeek OCR or any of the multimodal fashions listed above. These fashions return Markdown-formatted textual content, which preserves construction akin to headings, paragraphs, lists or table-like formatting. This makes it simpler to render the extracted content material immediately or course of it in downstream doc workflows.
Utilizing the API (OpenAI-compatible)
All these fashions are additionally accessible by Clarifai’s OpenAI-compatible API. Ship the picture and immediate in a single request, and the mannequin returns the extracted content material in Markdown. This makes it simple to make use of immediately in downstream pipelines. Try the detailed information on accessing DeepSeek OCR by way of the API.
Textual content Classification and NLP
Textual content classification is utilized in moderation, matter labeling, intent detection, routing, and broader textual content understanding. These duties require fashions that observe directions reliably, generalize throughout domains, and help multilingual enter while not having task-specific retraining.
Instruction-tuned language fashions make this a lot simpler. They’ll carry out classification in a zero-shot method, the place you outline the lessons or guidelines immediately within the immediate and the mannequin returns the label while not having a devoted classifier. This makes it simple to replace classes, experiment with completely different label units and deploy the identical logic throughout a number of languages. In case you want deeper area alignment, these fashions may also be fine-tuned.
Under are the some stronger fashions on the platform for textual content classification and NLP:
Gemma 3 (12B)
A current open mannequin from Google, tuned for effectivity and high-quality language understanding. Sturdy at zero-shot classification, multilingual reasoning, and following immediate directions throughout different classification duties.MiniCPM-4 8B
A compact, high-performing mannequin constructed for instruction following. Works nicely on classification, QA, and general-purpose language duties with aggressive efficiency at decrease latency.Qwen3-14B
A multilingual mannequin educated on a variety of language duties. Excels at zero-shot classification, textual content routing, and multi-language moderation and matter identification.
Notice: If you wish to entry the above open-source fashions like Gemma 3, MiniCPM-4 or Qwen3 immediately, you possibly can deploy them to your individual devoted compute utilizing the Platform and entry them by way of API similar to another mannequin on the platform.
There are additionally many extra third-party and open-source fashions obtainable within the Group part, together with GPT-5.1 household variants, Gemini 2.5 Professional, and several other high-quality fashions. You may discover these based mostly in your scale, and domain-specific wants.
Customized Mannequin Deployment
Along with the fashions listed above, the platform additionally helps you to convey your individual fashions or deploy open supply fashions from the Group utilizing Compute Orchestration (CO). That is useful while you want a mannequin that isn’t already obtainable on the platform, or while you need full management over how a mannequin runs in manufacturing.
CO handles the operational particulars required to serve fashions reliably. It containerizes fashions robotically, applies GPU fractioning so a number of fashions can share the identical {hardware}, manages autoscaling and makes use of optimized scheduling to cut back latency below load. This allows you to scale customized or open supply fashions while not having to handle the underlying infrastructure.
CO helps deployment on a number of cloud environments akin to AWS, Azure and GCP, which helps keep away from vendor lock-in and offers you flexibility in how and the place your fashions run. Try the information right here on importing and deploying your individual customized fashions.
Conclusion
The mannequin households outlined on this information symbolize essentially the most dependable and scalable option to deal with visible classification, detection, moderation, OCR and text-understanding workloads on the platform at present. By consolidating these duties round stronger multimodal and language-model architectures, builders can keep away from sustaining many slim, task-specific legacy fashions and as a substitute work with instruments that generalize nicely, help zero-shot directions and adapt cleanly to new use circumstances.
You may discover extra open supply and third-party fashions within the Group part and use the documentation to get began with the Playground, API or fine-tuning workflows. In case you need assistance planning a migration or choosing the suitable mannequin to your workload, you possibly can attain out to us on Discord or contact our help crew right here.

