

On this planet of voice AI, the distinction between a useful assistant and an ungainly interplay is measured in milliseconds. Whereas text-based Retrieval-Augmented Era (RAG) methods can afford a couple of seconds of ‘pondering’ time, voice brokers should reply inside a 200ms finances to keep up a pure conversational circulate. Normal manufacturing vector database queries usually add 50-300ms of community latency, successfully consuming all the finances earlier than an LLM even begins producing a response.
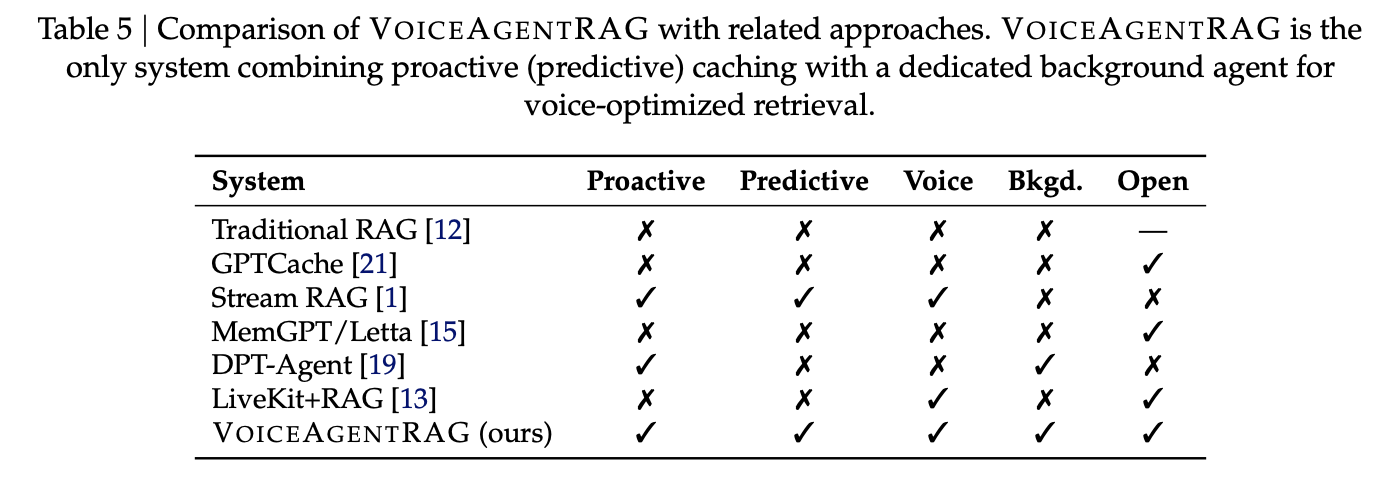
Salesforce AI analysis workforce has launched VoiceAgentRAG, an open-source dual-agent structure designed to bypass this retrieval bottleneck by decoupling doc fetching from response technology.
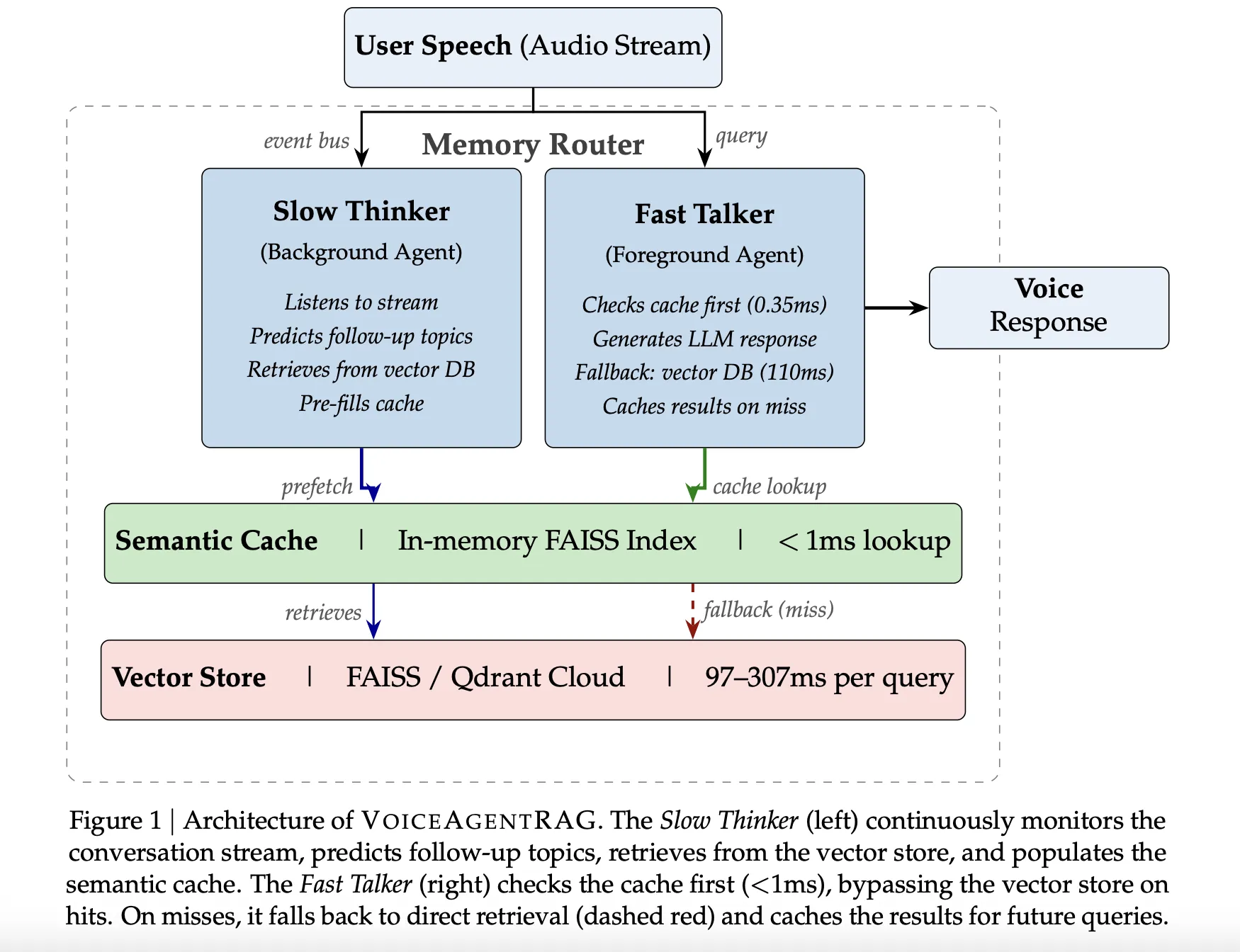
The Twin-Agent Structure: Quick Talker vs. Sluggish Thinker
VoiceAgentRAG operates as a reminiscence router that orchestrates two concurrent brokers by way of an asynchronous occasion bus:
- The Quick Talker (Foreground Agent): This agent handles the essential latency path. For each person question, it first checks an area, in-memory Semantic Cache. If the required context is current, the lookup takes roughly 0.35ms. On a cache miss, it falls again to the distant vector database and instantly caches the outcomes for future turns.
- The Sluggish Thinker (Background Agent): Operating as a background process, this agent constantly screens the dialog stream. It makes use of a sliding window of the final six dialog turns to foretell 3–5 doubtless follow-up matters. It then pre-fetches related doc chunks from the distant vector retailer into the native cache earlier than the person even speaks their subsequent query.
To optimize search accuracy, the Sluggish Thinker is instructed to generate document-style descriptions quite than questions. This ensures the ensuing embeddings align extra intently with the precise prose discovered within the information base.
The Technical Spine: Semantic Caching
The system’s effectivity hinges on a specialised semantic cache applied with an in-memory FAISS IndexFlat IP (interior product).
- Doc-Embedding Indexing: In contrast to passive caches that index by question that means, VoiceAgentRAG indexes entries by their very own doc embeddings. This enables the cache to carry out a correct semantic search over its contents, making certain relevance even when the person’s phrasing differs from the system’s predictions.
- Threshold Administration: As a result of query-to-document cosine similarity is systematically decrease than query-to-query similarity, the system makes use of a default threshold of to steadiness precision and recall.
- Upkeep: The cache detects near-duplicates utilizing a 0.95 cosine similarity threshold and employs a Least Lately Used (LRU) eviction coverage with a 300-second Time-To-Dwell (TTL).
- Precedence Retrieval: On a Quick Talker cache miss, a
PriorityRetrievaloccasion triggers the Sluggish Thinker to carry out an instantaneous retrieval with an expanded top-k (2x the default) to quickly populate the cache across the new matter space.
Benchmarks and Efficiency
The analysis workforce evaluated the system utilizing Qdrant Cloud as a distant vector database throughout 200 queries and 10 dialog situations.
| Metric | Efficiency |
| Total Cache Hit Charge | 75% (79% on heat turns) |
| Retrieval Speedup | 316x |
| Whole Retrieval Time Saved | 16.5 seconds over 200 turns |
The structure is only in topically coherent or sustained-topic situations. For instance, ‘Characteristic comparability’ (S8) achieved a 95% hit charge. Conversely, efficiency dipped in additional risky situations; the lowest-performing situation was ‘Current buyer improve’ (S9) at a 45% hit charge, whereas ‘Combined rapid-fire’ (S10) maintained 55%.
Integration and Assist
The VoiceAgentRAG repository is designed for broad compatibility throughout the AI stack:
- LLM Suppliers: Helps OpenAI, Anthropic, Gemini/Vertex AI, and Ollama. The paper’s default analysis mannequin was GPT-4o-mini.
- Embeddings: The analysis utilized OpenAI text-embedding-3-small (1536 dimensions), however the repository gives assist for each OpenAI and Ollama embeddings.
- STT/TTS: Helps Whisper (native or OpenAI) for speech-to-text and Edge TTS or OpenAI for text-to-speech.
- Vector Shops: Constructed-in assist for FAISS and Qdrant.
Key Takeaways
- Twin-Agent Structure: The system solves the RAG latency bottleneck through the use of a foreground ‘Quick Talker’ for sub-millisecond cache lookups and a background ‘Sluggish Thinker’ for predictive pre-fetching.
- Vital Speedup: It achieves a 316x retrieval speedup on cache hits, which is essential for staying throughout the pure 200ms voice response finances.
- Excessive Cache Effectivity: Throughout numerous situations, the system maintains a 75% total cache hit charge, peaking at 95% in topically coherent conversations like function comparisons.
- Doc-Listed Caching: To make sure accuracy no matter person phrasing, the semantic cache indexes entries by doc embeddings quite than the expected question’s embedding.
- Anticipatory Prefetching: The background agent makes use of a sliding window of the final 6 dialog turns to foretell doubtless follow-up matters and populate the cache throughout pure inter-turn pauses.
Take a look at the Paper and Repo right here. Additionally, be happy to comply with us on Twitter and don’t overlook to hitch our 120k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you may be a part of us on telegram as properly.

