
Zephyr-7B-alpha is a brand new open-source language mannequin from HuggingFace and relies on Mistral-7B. This mannequin surpasses Llama 2 70B Chat on the MT Bench.
Now you can check out zephyr-7B-alpha within the Clarifai Platform and entry it via the API.
Desk of Contents
- Introduction
- Immediate Template
- Working Zephyr 7B with Python
- Working Zephyr 7B with Javascript
- Greatest Use instances
- Limitations
Introduction
Zephyr-7B-alpha is the primary mannequin within the Zephyr collection and relies on Mistral-7B. It has been fine-tuned utilizing Direct Desire Optimization (DPO) on a mixture of publicly obtainable and artificial datasets. Notably, the in-built alignment of those datasets was eliminated to spice up efficiency on the MT Bench and make the mannequin extra useful.
Immediate Template
To work together successfully with the Zephyr-7B-alpha mannequin, use the immediate template under.
<|system|> {system_prompt}</s> <|person|> {immediate}</s> <|assistant|> |
This is an instance of the right way to use the immediate template:
<|system|> |
Working Zephyr 7B with Python
You may run Zephyr 7B with our Python SDK with just some traces of code.
To get began, Signup to Clarifai right here and get your Private Entry Token(PAT) below the safety part in settings.
Export your PAT as an surroundings variable:
export CLARIFAI_PAT={your private entry token} |
Take a look at the Code Under:
Working Zephyr 7B with Javascript
You can even run Zephyr Mannequin utilizing different Clarifai Shopper Libraries like Java, cURL, NodeJS, PHP, and so on right here.
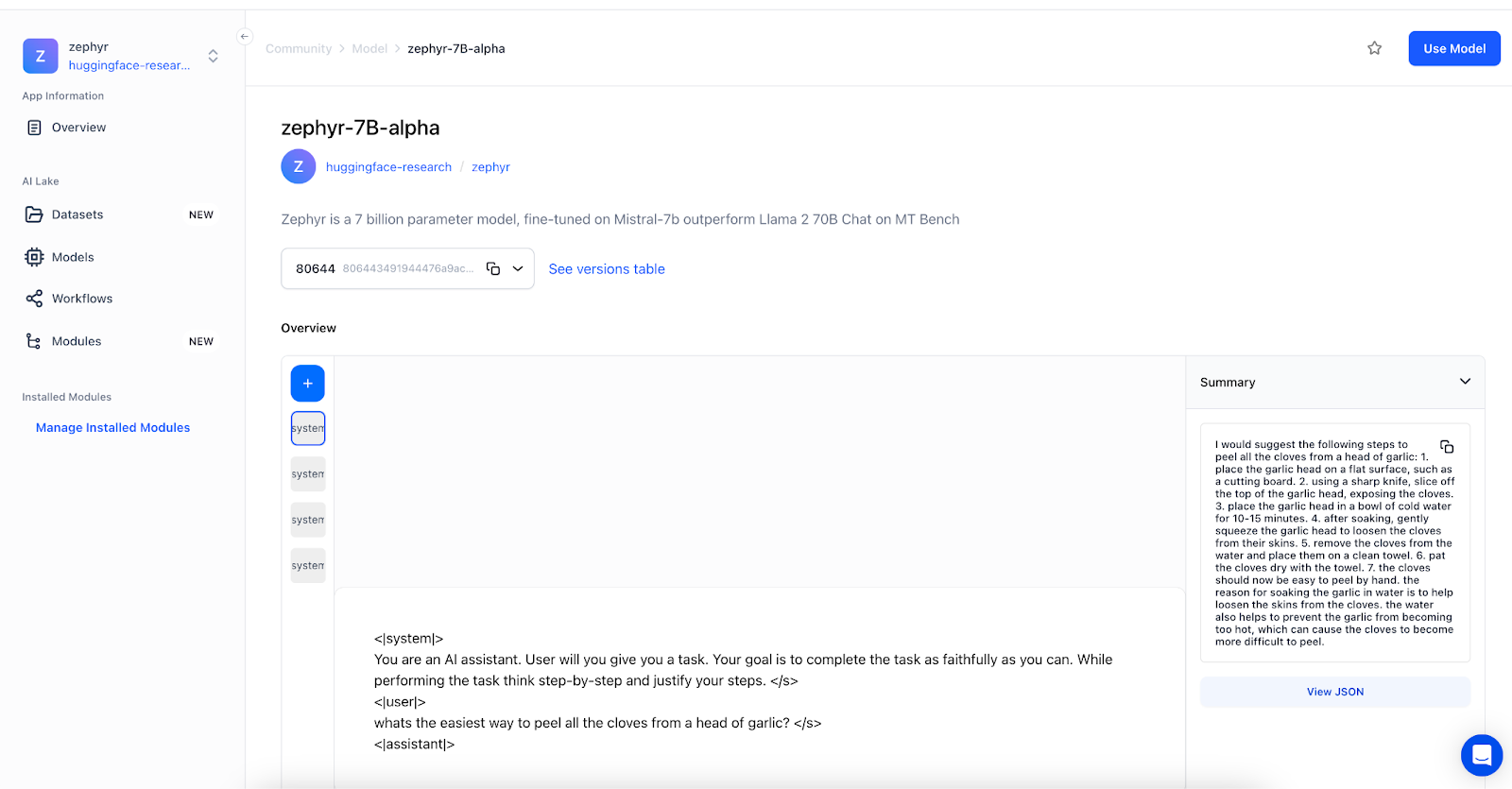
Mannequin Demo within the Clarifai Platform:
Check out the zephyr-7B-alpha mannequin right here: https://clarifai.com/huggingface-research/zephyr/fashions/zephyr-7B-alpha
Greatest Use Circumstances
Chat functions
The Zephyr-7B-alpha mannequin is well-suited for chat functions. It was initially fine-tuned on a model of the UltraChat dataset, which incorporates artificial dialogues generated by ChatGPT. Additional refinement was achieved by using huggingface TRL’s DPOTrainer on the openbmb/UltraFeedback dataset. This dataset comprises prompts and mannequin completions ranked by GPT-4. This intensive coaching course of ensures that the mannequin performs exceptionally properly in chat functions.
Limitations
Zephyr-7B-alpha has not been aligned to human preferences utilizing strategies like Reinforcement Studying from Human Suggestions (RLHF). In consequence, it might probably produce outputs that could be problematic, particularly when deliberately prompted.
Maintain up to the mark with AI
Observe us on Twitter X to get the most recent from the LLMs
Be a part of us in our Discord to speak LLMs

