

Picture by Freepik
This complete article will talk about time-based knowledge visualization utilizing Python with the Pandas library. As you realize, time-series knowledge is a treasure trove of insights, and with the skillful resampling method, you possibly can rework uncooked temporal knowledge into visually compelling narratives. Whether or not you are an information fanatic, scientist, analyst, or simply interested in unraveling the tales hidden inside time-based knowledge, this text show you how to with the data and instruments to revamp your knowledge visualization expertise. So, let’s begin discussing the Pandas resampling strategies and switch knowledge into informative and charming temporal masterpieces.
Whereas working with time-based knowledge visualization, Knowledge resampling is essential and really helpful. It permits you to management the granularity of the information to extract significant insights and create visually compelling representations to grasp it higher. Within the beneath image, you possibly can observe which you could both upsample or downsample your time sequence knowledge when it comes to frequencies based mostly in your necessities.
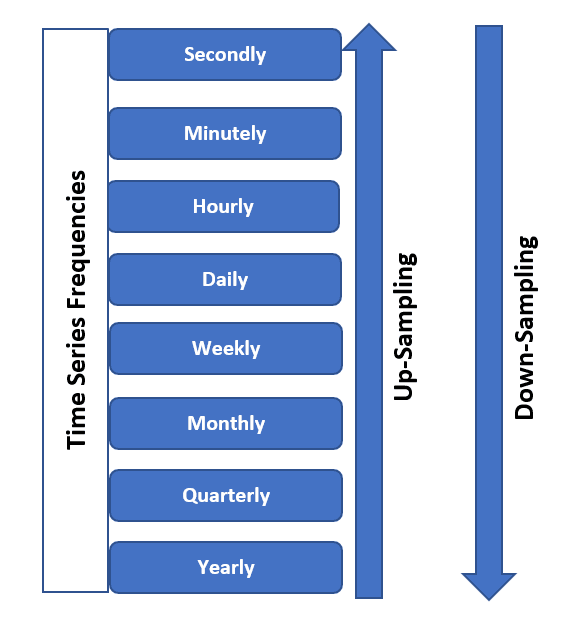
Picture from SQLRelease
Principally, the 2 major functions of information resampling are talked about beneath:
- Granularity Adjustment: Gathering the large knowledge permits you to change the time intervals at which knowledge factors are collected or aggregated. You will get solely the important info as a substitute of getting the noise. This can assist you take away the noisy knowledge, which converts the information to extra manageable for visualization.
- Alignment: It additionally helps align knowledge from a number of sources with completely different time intervals, making certain consistency when creating visualizations or conducting analyses.
For Instance,
Suppose you may have every day inventory worth knowledge for a selected firm that you’re getting from a inventory trade, and also you purpose to visualise the long-term developments with out together with the noisy knowledge factors in your evaluation. So, to do that, you possibly can resample this every day knowledge to a month-to-month frequency by taking the typical closing worth for every month, and in consequence, the scale of the information for visualization goal lower, and your evaluation can present higher insights.
import pandas as pd
# Pattern every day inventory worth knowledge
knowledge = {
'Date': pd.date_range(begin="2023-01-01", durations=365, freq='D'),
'StockPrice': [100 + i + 10 * (i % 7) for i in range(365)]
}
df = pd.DataFrame(knowledge)
# Resample to month-to-month frequency
monthly_data = df.resample('M', on='Date').imply()
print(monthly_data.head())
Within the above instance, you may have noticed that we’ve got resampled the every day knowledge into month-to-month intervals and calculated the imply closing worth for every month, as a result of which you bought the smoother, much less noisy illustration of the inventory worth knowledge, making it simpler to establish long-term developments and patterns for determination making.
When working with time-series knowledge, the principle parameter for resampling is the frequency, which it’s essential to choose accurately to get insightful and sensible visualizations. Principally, there’s a tradeoff between granularity, which suggests how detailed the information is, and readability, which implies how nicely the information patterns are revealed.
For Instance,
Think about you may have temperature knowledge recorded each minute for a 12 months. Suppose you must visualize the annual temperature pattern; utilizing minute-level knowledge would end in an excessively dense and cluttered plot. Then again, if you happen to combination the information to yearly averages, you may lose invaluable info.
# Pattern minute-level temperature knowledge
knowledge = {
'Timestamp': pd.date_range(begin="2023-01-01", durations=525600, freq='T'),
'Temperature': [20 + 10 * (i % 1440) / 1440 for i in range(525600)]
}
df = pd.DataFrame(knowledge)
# Resample to completely different frequencies
daily_avg = df.resample('D', on='Timestamp').imply()
monthly_avg = df.resample('M', on='Timestamp').imply()
yearly_avg = df.resample('Y', on='Timestamp').imply()
print(daily_avg.head())
print(monthly_avg.head())
print(yearly_avg.head())
On this instance, we resample the minute-level temperature knowledge into every day, month-to-month, and yearly averages. Relying in your analytical or visualization objectives, you possibly can select the extent of element that greatest serves your goal. Each day averages reveal every day temperature patterns, whereas yearly averages present a high-level overview of annual developments.
By choosing the optimum resampling frequency, you possibly can steadiness the quantity of information element with the readability of your visualizations, making certain your viewers can simply discern the patterns and insights you wish to convey.
When working with time-based knowledge, it is important to grasp numerous aggregation strategies and strategies. These strategies permit you to successfully summarize and analyze your knowledge, revealing completely different points of your time-based info. Customary aggregation strategies embrace calculating sums and means or making use of customized capabilities.
Picture from TowardsDataScience
For Instance,
Take into account you may have a dataset containing every day gross sales knowledge for a retail retailer over a 12 months. You wish to analyze the yearly income pattern. To do that, you need to use aggregation strategies to calculate the overall gross sales for every month and 12 months.
# Pattern every day gross sales knowledge
knowledge = {
'Date': pd.date_range(begin="2023-01-01", durations=365, freq='D'),
'Gross sales': [1000 + i * 10 + 5 * (i % 30) for i in range(365)]
}
df = pd.DataFrame(knowledge)
# Calculate month-to-month and yearly gross sales with the aggregation technique
monthly_totals = df.resample('M', on='Date').sum()
yearly_totals = df.resample('Y', on='Date').sum()
print(monthly_totals.head())
print(yearly_totals.head())
On this instance, we resample the every day gross sales knowledge into month-to-month and yearly totals utilizing the sum() aggregation technique. By doing this, you possibly can analyze the gross sales pattern at completely different ranges of granularity. Month-to-month totals present insights into seasonal differences, whereas yearly totals give a high-level overview of the annual efficiency.
Relying in your particular evaluation necessities, you can even use different aggregation strategies like calculating means and medians or making use of customized capabilities relying on the dataset distribution, which is significant based on the issue. These strategies permit you to extract invaluable insights out of your time-based knowledge by summarizing it in a means that is smart to your evaluation or visualization objectives.
Dealing with lacking knowledge is a important side of working with time sequence, making certain that your visualizations and analyses stay correct and informative even when coping with gaps in your knowledge.
For Instance,
Think about you are working with a historic temperature dataset, however some days have lacking temperature readings as a result of gear malfunctions or knowledge assortment errors. You will need to deal with these lacking values to create significant visualizations and preserve knowledge integrity.
# Pattern temperature knowledge with lacking values
knowledge = {
'Date': pd.date_range(begin="2023-01-01", durations=365, freq='D'),
'Temperature': [25 + np.random.randn() * 5 if np.random.rand() > 0.2 else np.nan for _ in range(365)]
}
df = pd.DataFrame(knowledge)
# Ahead-fill lacking values (fill with the day before today's temperature)
df['Temperature'].fillna(technique='ffill', inplace=True)
# Visualize the temperature knowledge
import matplotlib.pyplot as plt
plt.determine(figsize=(12, 6))
plt.plot(df['Date'], df['Temperature'], label="Temperature", coloration="blue")
plt.title('Each day Temperature Over Time')
plt.xlabel('Date')
plt.ylabel('Temperature (°C)')
plt.grid(True)
plt.present()
Output:
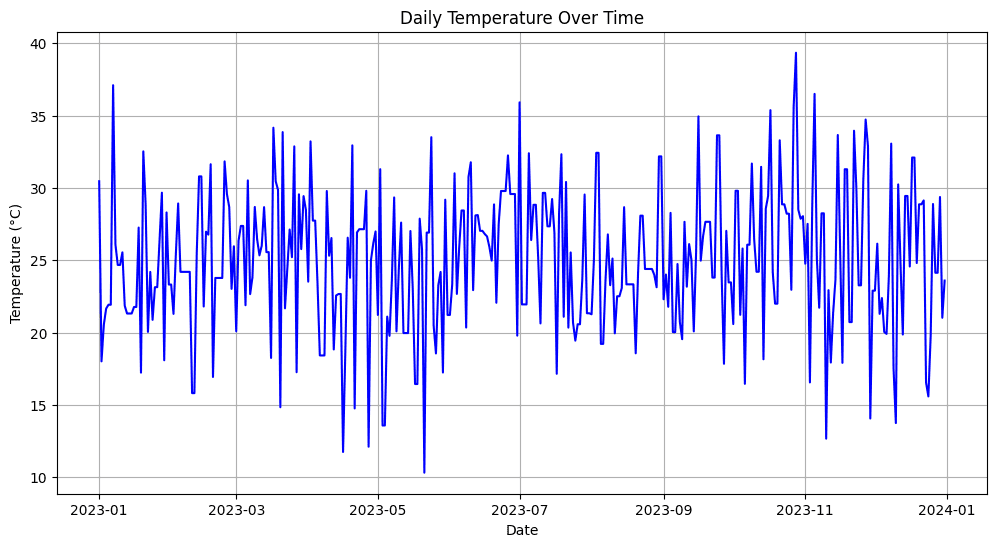
Picture by Creator
Within the above instance, you possibly can see that firstly, we’ve got simulated the lacking temperature values (about 20% of the information) after which used the forward-fill (ffill) technique to fill within the gaps, which signifies that the lacking values are changed with the temperature from the day before today.
Due to this fact, dealing with the lacking knowledge ensures that your visualizations precisely symbolize the underlying developments and patterns within the time sequence, stopping gaps from distorting your insights or deceptive your viewers. Varied methods, akin to interpolation or backward-filling, could be employed based mostly on the character of the information and the analysis query.
Knowledge resampling in pandas permits you to visualize developments and patterns in sequential or time-based knowledge, which additional lets you gather insights and successfully talk the outcomes to others. Consequently, yow will discover clear and informative visible representations of your knowledge to focus on the completely different parts, together with developments, seasonality, and irregular patterns (presumably the noise within the knowledge)
For Instance,
Suppose you may have a dataset containing every day web site site visitors knowledge collected over the previous years. You purpose to visualise the general site visitors pattern within the subsequent years, establish any seasonal patterns, and spot irregular spikes or dips in site visitors.
# Pattern every day web site site visitors knowledge
knowledge = {
'Date': pd.date_range(begin="2019-01-01", durations=1095, freq='D'),
'Guests': [500 + 10 * ((i % 365) - 180) + 50 * (i % 30) for i in range(1095)]
}
df = pd.DataFrame(knowledge)
# Create a line plot to visualise the pattern
plt.determine(figsize=(12, 6))
plt.plot(df['Date'], df['Visitors'], label="Each day Guests", coloration="blue")
plt.title('Web site Visitors Over Time')
plt.xlabel('Date')
plt.ylabel('Guests')
plt.grid(True)
# Add seasonal decomposition plot
from statsmodels.tsa.seasonal import seasonal_decompose
consequence = seasonal_decompose(df['Visitors'], mannequin="additive", freq=365)
consequence.plot()
plt.present()
Output:
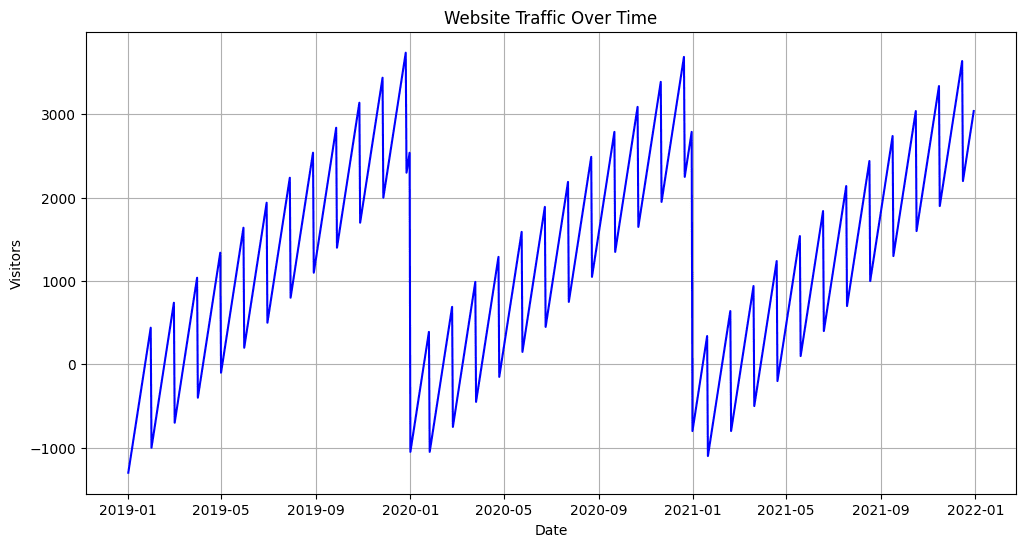
Picture by Creator
Within the above instance, we’ve got first created a line plot to visualise the every day web site site visitors pattern over time. This plot describes the general progress and any irregular patterns within the dataset. Additionally, to decompose the information into completely different parts, we use the seasonal decomposition method from the statsmodels library, together with pattern, seasonality, and residual parts.
This manner, you possibly can successfully talk the web site’s site visitors developments, seasonality, and anomalies to stakeholders, which boosts your skill to derive necessary insights from time-based knowledge and convert it into data-driven selections.
Colab Pocket book hyperlink: https://colab.analysis.google.com/drive/19oM7NMdzRgQrEDfRsGhMavSvcHx79VDK#scrollTo=nHg3oSjPfS-Y
On this article, we mentioned the time-based resampling of information in Python. So, to conclude our session, let’s summarize the details lined on this article:
- Time-based resampling is a strong method for remodeling and summarizing time-series knowledge to get higher insights for decision-making.
- Cautious choice of resampling frequency is crucial to steadiness granularity and readability in knowledge visualization.
- Aggregation strategies like sum, imply, and customized capabilities assist reveal completely different points of time-based knowledge.
- Efficient visualization strategies assist in figuring out developments, seasonality, and irregular patterns, facilitating clear communication of findings.
- Actual-world use circumstances in finance, climate forecasting, and social media analytics show the wide-ranging affect of time-based resampling.
Aryan Garg is a B.Tech. Electrical Engineering scholar, at the moment within the closing 12 months of his undergrad. His curiosity lies within the area of Internet Improvement and Machine Studying. He have pursued this curiosity and am desirous to work extra in these instructions.

