

Picture by Editor
Within the ever-evolving panorama of expertise, the function of information scientists and analysts has change into essential for each group to seek out data-driven insights for decision-making. Kaggle, a platform that brings collectively information scientists and machine studying engineers lovers, turns into a central platform for enhancing information science and machine studying expertise. As we’re going into 2024, the demand for proficient information scientists continues to rise considerably, making it an opportune time to speed up your journey on this dynamic discipline.
So, on this article, you’ll get to know the highest 10 Kaggle machine-learning tasks to deal with in 2024, which might help you acquire sensible expertise in fixing information science issues. By implementing these tasks, you’ll get a complete studying expertise overlaying numerous features of information science, from information preprocessing and exploratory information evaluation to superior machine studying mannequin improvement.
Let’s discover the thrilling world of information science collectively and elevate your expertise to new heights in 2024.
Concept: On this mission, you have to implement a deep studying mannequin that helps acknowledge and classify a canine’s breed based mostly on enter pictures offered by the person within the testing surroundings. By exploring this traditional picture classification job, you’ll study one of many well-known architectures of deep studying, i.e., convolutional neural networks (CNNs), and their utility to real-world issues.
Dataset: Since it is a supervised downside, the dataset would include labeled pictures of varied canine breeds. One of the crucial standard decisions to implement this job is the “Stanford Canine Dataset,” freely out there on Kaggle.

Picture from Medium
Applied sciences: Based mostly in your experience, Python libraries and frameworks like TensorFlow or PyTorch can be utilized to implement this picture classification job.
Implementation: Firstly, you must preprocess the photographs, design a CNN structure with completely different layers concerned, practice the mannequin, and consider its efficiency utilizing analysis metrics comparable to accuracy and confusion matrix.
Concept: On this mission, you’ll be taught the sensible features of deploying a machine-learning mannequin utilizing Gradio. This user-friendly library facilitates mannequin deployment with nearly no code necessities. This mission emphasizes making machine studying fashions accessible via a easy interface and utilized in a real-time manufacturing surroundings.
Dataset: Based mostly on the issue assertion starting from picture classification to pure language processing duties, you’ll be able to select the respective dataset, and accordingly, algorithm choice could be executed by maintaining various factors comparable to latency for prediction and accuracy, and so on., after which deploying it.
Applied sciences: Gradio for deployment, together with the required libraries for mannequin improvement (e.g., TensorFlow, PyTorch).
Implementation: Firstly, practice a mannequin, then save the weights, that are the learnable parameters that assist to make the prediction, and eventually combine these with Gradio to create a easy person interface and deploy the mannequin for interactive predictions.
Concept: On this mission, you must develop a machine studying mannequin that helps to seek out the distinction between actual and pretend information articles collected from completely different social media purposes utilizing pure language processing strategies. This mission entails textual content preprocessing, characteristic extraction, and classification.
Dataset: Use datasets containing labeled information articles, such because the “Pretend Information Dataset” on Kaggle.
Picture from Kaggle
Applied sciences: Pure Language Processing libraries like NLTK or spaCy and machine studying algorithms like Naive Bayes or deep studying fashions.
Implementation: You may tokenize and clear textual content information, extract related options, practice a classification mannequin, and assess its efficiency utilizing metrics like precision, recall, and F1 rating.
Concept: On this mission, you have to construct a advice system that mechanically suggests motion pictures or net sequence to customers based mostly on their previous watches via the correlated platforms. Advice programs like Netflix and Amazon Prime are extensively utilized in streaming media to reinforce person expertise.
Dataset: Generally used datasets embrace MovieLens or IMDb, which include person rankings and film info.
Applied sciences: Collaborative filtering algorithms, matrix factorization, and advice system frameworks like Shock or LightFM.
Implementation: You may discover user-item interactions, construct a advice algorithm, consider its efficiency utilizing metrics like Imply Absolute Error, and fine-tune the mannequin for higher predictions.
Concept: On this mission, you must create a machine studying mannequin to phase clients based mostly on their previous buying habits in order that when the identical buyer comes once more, that system can advocate previous issues to extend gross sales. On this means, by using segmentation, organizations can goal advertising and personalised companies to all clients.
Dataset: Since it is a sort of unsupervised studying downside, labels is not going to be required for such duties, and you should use datasets containing buyer transaction information, on-line retail datasets, or any e-commerce-related datasets comparable to from Amazon, Flipkart, and so on.,
Applied sciences: Completely different clustering algorithms from the category of unsupervised machine studying algorithms, comparable to Ok-means or hierarchical clustering(both divisive or agglomerative), for segmenting clients based mostly on their habits.
Implementation: Firstly, you must course of the transaction information, together with visualizing the information after which apply completely different clustering algorithms, visualize buyer segments based mostly on different clusters shaped by the mannequin, analyze the traits of every phase for advertising insights, after which consider it utilizing completely different metrics comparable to Silhouette rating, and so on.
Concept: The habits of shares is a bit random, however by utilizing machine studying, you’ll be able to predict the approximated inventory costs utilizing historic monetary information by capturing the variance within the information. This mission entails time sequence evaluation and forecasting to mannequin the dynamics of various inventory costs amongst a number of sectors comparable to Banking, Vehicle, and so on.
Picture from Devpost
Dataset: You want the historic costs of shares, which embrace Open, Excessive, Low, Shut, Quantity, and so on, in several time frames, together with every day or minute-by-minute costs and traded portions.
Applied sciences: You need to use completely different strategies to investigate the time sequence fashions, comparable to Autocorrelation operate and forecasting fashions, together with Autoregressive Built-in Shifting Common (ARIMA), Lengthy Brief-Time period Reminiscence (LSTM) networks, and so on.
Implementation: Firstly, you must course of the time sequence information, together with its decomposition comparable to cyclical, seasonal, random, and so on., then select an acceptable forecasting mannequin to coach the mannequin, and eventually consider its efficiency utilizing metrics like Imply Squared Error, Imply Absolute Error or Root Imply Squared Error.
Concept: On this mission, you must develop a mannequin that may acknowledge several types of feelings in spoken languages, comparable to offended, glad, loopy, and so on., which entails the processing of the audio information captured from numerous individuals and making use of machine studying strategies for emotion classification.
Picture from Kaggle
Dataset: Make the most of datasets with labeled audio clips, such because the “RAVDESS” dataset containing emotional speech recordings.
Applied sciences: Sign processing strategies for characteristic extraction deep studying fashions for audio evaluation.
Implementation: You may extract options from audio information, design a neural community for emotion recognition, practice the mannequin, and assess its efficiency utilizing metrics like accuracy and confusion matrix.
Concept: On this mission, you have to construct a system to foretell future gross sales based mostly on historic gross sales information. This mission is important for companies to optimize stock and plan for future demand.
Dataset: Historic gross sales information for services or products, together with info on gross sales quantity, time, and related elements.
Applied sciences: Time sequence forecasting strategies, regression fashions, and machine studying frameworks.
Implementation: Firstly, you may preprocess gross sales information, select an acceptable forecasting or regression mannequin, practice the mannequin, and consider its efficiency utilizing metrics like Imply Squared Error or R-squared.
Concept: On this mission, you have to create a mannequin to categorise hand-written digits utilizing the MNIST dataset. This mission is a basic introduction to picture classification and is commonly thought of a place to begin for these new to deep studying.
Dataset: The MNIST dataset consists of grayscale pictures of hand-written digits (0-9).
Picture from ResearchGate
Applied sciences: Convolutional Neural Networks (CNNs) utilizing frameworks comparable to TensorFlow or PyTorch.
Implementation: Firstly, you have to preprocess the picture information, design a CNN structure, practice the mannequin, and consider its efficiency utilizing metrics like accuracy and confusion matrix.
Concept: On this mission, you must develop a machine studying mannequin to detect fraudulent bank card transactions, which is essential for monetary establishments to reinforce safety, defend customers from fraudulent actions, and make the surroundings for various transactions very simple.
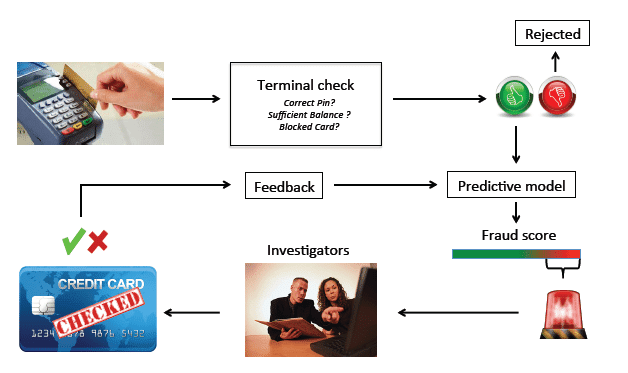
Picture from ResearchGate
Dataset: Since it is a supervised studying downside, you must acquire the dataset, which comprises Bank card transaction datasets with labeled instances of fraud and non-fraud transactions.
Applied sciences: Anomaly detection algorithms, classification fashions like Random Forest or Assist Vector Machines, and machine studying frameworks for implementation.
Implementation: Firstly, you must preprocess the transaction information, practice a fraud detection mannequin, tune parameters for optimum efficiency, and consider the mannequin utilizing classification analysis metrics like precision, recall, and ROC-AUC.
In conclusion, exploring the Prime 10 Kaggle Machine Studying Initiatives has been implausible. From unraveling the mysteries of canine breeds and deploying machine studying fashions with Gradio to combating faux information and predicting inventory costs, every mission has provided a novel characteristic within the diversified discipline of information science. These tasks assist acquire invaluable insights into fixing real-world challenges.
Bear in mind, changing into an information scientist in 2024 is not only about mastering algorithms or frameworks—it is about crafting options to intricate issues, understanding various datasets, and always adapting to the evolving panorama of expertise. Hold exploring, keep curious, and let the insights from these tasks information you in making impactful contributions to the world of information science. Cheers to your ongoing journey within the dynamic and ever-expanding discipline of information science!
Aryan Garg is a B.Tech. Electrical Engineering pupil, at present within the closing 12 months of his undergrad. His curiosity lies within the discipline of Net Growth and Machine Studying. He have pursued this curiosity and am desirous to work extra in these instructions.

