

Picture by Creator
Having title is essential for an article’s success. Folks spend just one second (if we consider Ryan Vacation’s e-book “Belief Me, I am Mendacity” deciding whether or not to click on on the title to open the entire article. The media are obsessive about optimizing clickthrough fee (CTR), the variety of clicks a title receives divided by the variety of instances the title is proven. Having a click-bait title will increase CTR. The media will doubtless select a title with a better CTR between the 2 titles as a result of this can generate extra income.
I’m not actually into squeezing advert income. It’s extra about spreading my information and experience. And nonetheless, viewers have restricted time and a spotlight, whereas content material on the Web is just about limitless. So, I need to compete with different content-makers to get viewers’ consideration.
How do I select a correct title for my subsequent article? After all, I want a set of choices to select from. Hopefully, I can generate them by myself or ask ChatGPT. However what do I do subsequent? As a knowledge scientist, I counsel working an A/B/N check to know which choice is the very best in a data-driven method. However there’s a drawback. First, I must resolve shortly as a result of content material expires shortly. Secondly, there might not be sufficient observations to identify a statistically important distinction in CTRs as these values are comparatively low. So, there are different choices than ready a few weeks to resolve.
Hopefully, there’s a resolution! I can use a “multi-armed bandit” machine studying algorithm that adapts to the information we observe about viewers’ conduct. The extra folks click on on a selected choice within the set, the extra site visitors we are able to allocate to this selection. On this article, I’ll briefly clarify what a “Bayesian multi-armed bandit” is and present the way it works in apply utilizing Python.
Multi-armed Bandits are machine studying algorithms. The Bayesian sort makes use of Thompson sampling to decide on an choice based mostly on our prior beliefs about likelihood distributions of CTRs which can be up to date based mostly on the brand new knowledge afterward. All these likelihood idea and mathematical statistics phrases could sound complicated and daunting. Let me clarify the entire idea utilizing as few formulation as I can.
Suppose there are solely two titles to select from. We don’t know about their CTRs. However we wish to have the highest-performing title. We have now a number of choices. The primary one is to decide on whichever title we consider in additional. That is the way it labored for years within the business. The second allocates 50% of the incoming site visitors to the primary title and 50% to the second. This turned doable with the rise of digital media, the place you possibly can resolve what textual content to indicate exactly when a viewer requests an inventory of articles to learn. With this strategy, you possibly can make sure that 50% of site visitors was allotted to the best-performing choice. Is that this a restrict? After all not!
Some folks would learn the article inside a few minutes after publishing. Some folks would do it in a few hours or days. This implies we are able to observe how “early” readers responded to totally different titles and shift site visitors allocation from 50/50 and allocate just a little bit extra to the better-performing choice. After a while, we are able to once more calculate CTRs and alter the cut up. Within the restrict, we wish to alter the site visitors allocation after every new viewer clicks on or skips the title. We’d like a framework to adapt site visitors allocation scientifically and automatedly.
Right here comes Bayes’ theorem, Beta distribution, and Thompson sampling.
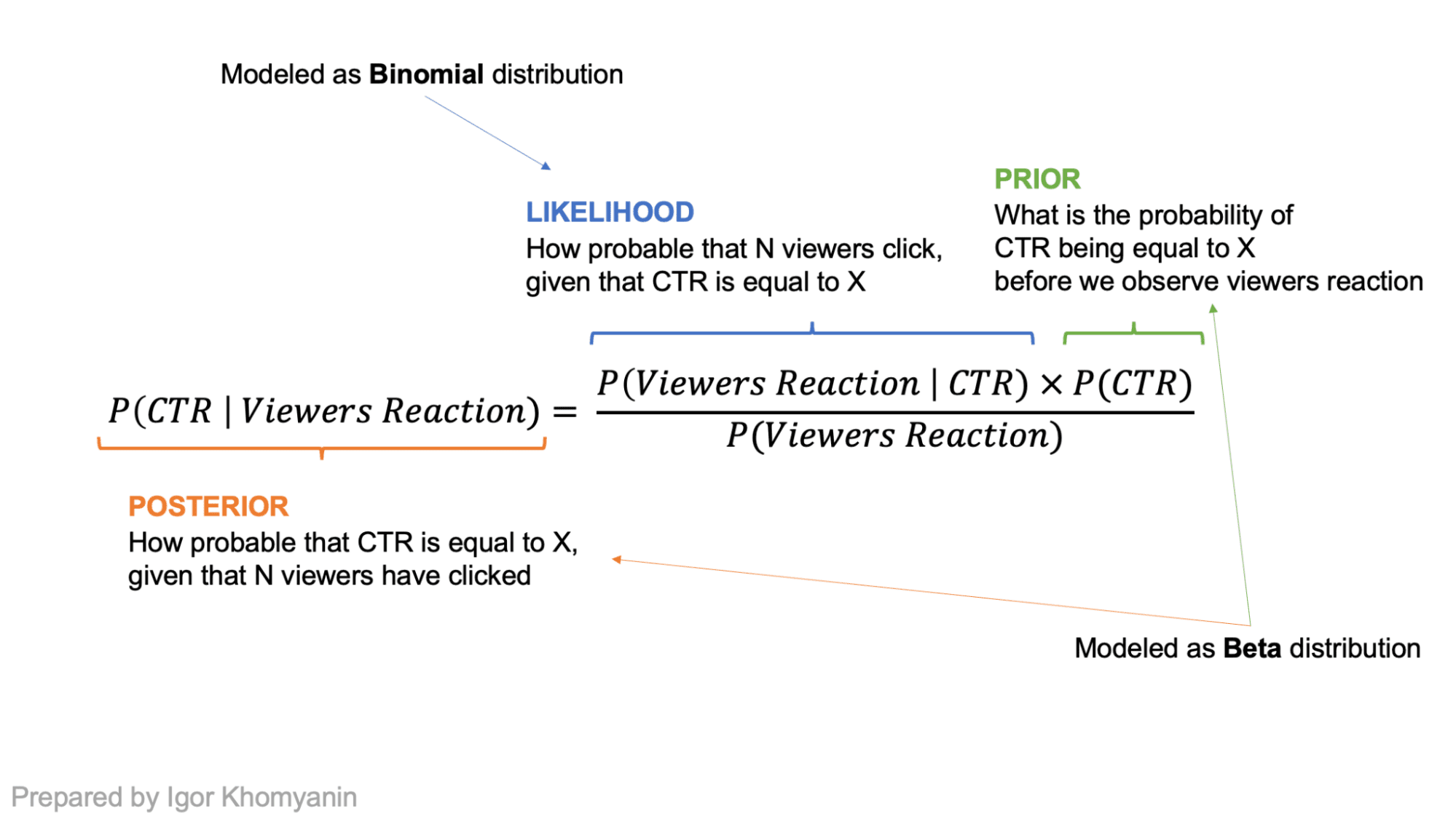
Let’s assume that the CTR of an article is a random variable “theta.” By design, it lies someplace between 0 and 1. If we now have no prior beliefs, it may be any quantity between 0 and 1 with equal likelihood. After we observe some knowledge “x,” we are able to alter our beliefs and have a brand new distribution for “theta” that shall be skewed nearer to 0 or 1 utilizing Bayes’ theorem.
The quantity of people that click on on the title could be modeled as a Binomial distribution the place “n” is the variety of guests who see the title, and “p” is the CTR of the title. That is our chance! If we mannequin the prior (our perception in regards to the distribution of CTR) as a Beta distribution and take binomial chance, the posterior would even be a Beta distribution with totally different parameters! In such instances, Beta distribution is named a conjugate prior to the chance.
Proof of that truth isn’t that onerous however requires some mathematical train that isn’t related within the context of this text. Please confer with the attractive proof right here:
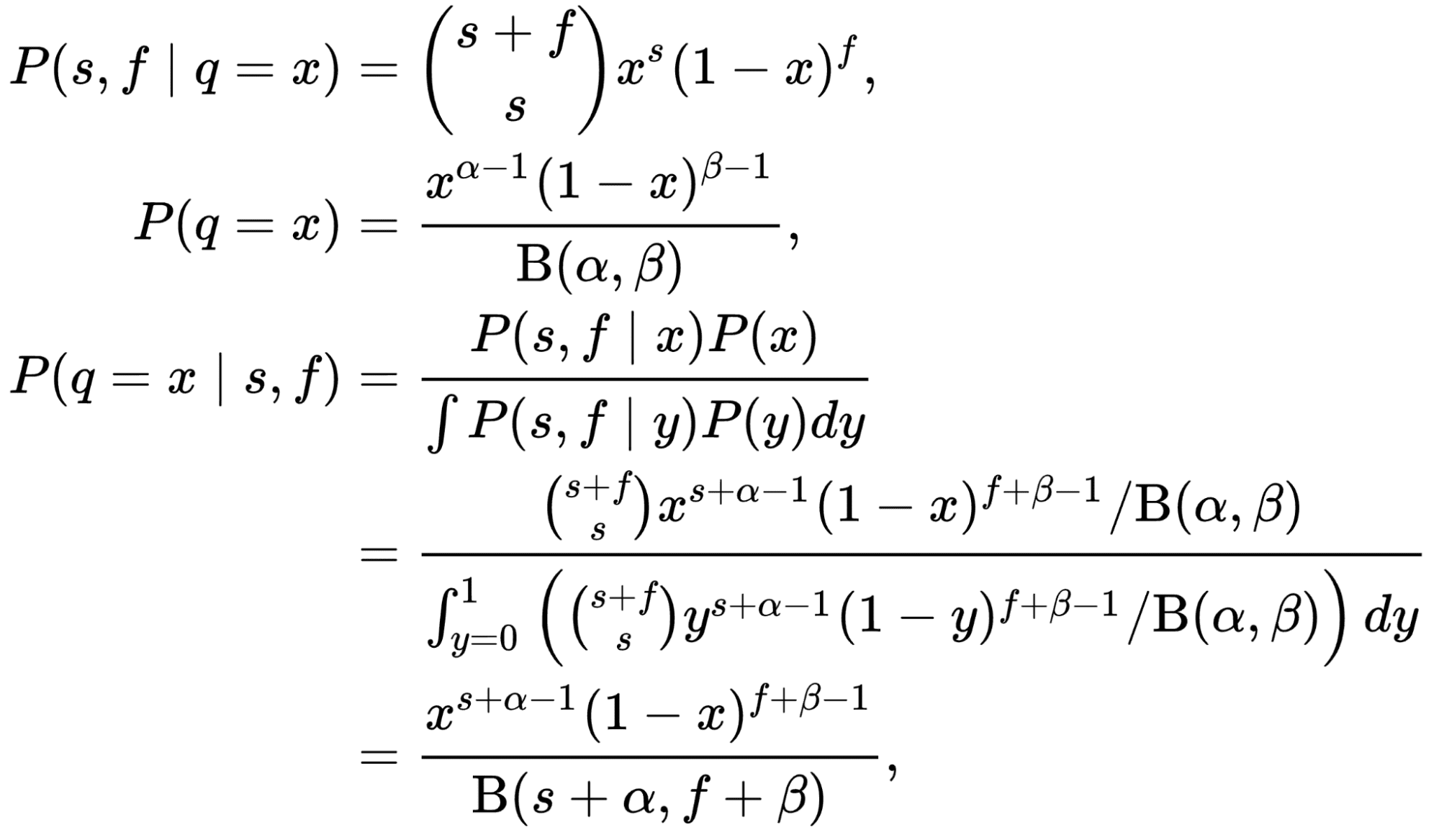
The beta distribution is bounded by 0 and 1, which makes it an ideal candidate to mannequin a distribution of CTR. We will begin from “a = 1” and “b = 1” as Beta distribution parameters that mannequin CTR. On this case, we’d don’t have any beliefs about distribution, making any CTR equally possible. Then, we are able to begin including noticed knowledge. As you possibly can see, every “success” or “click on” will increase “a” by 1. Every “failure” or “skip” will increase “b” by 1. This skews the distribution of CTR however doesn’t change the distribution household. It’s nonetheless a beta distribution!
We assume that CTR could be modeled as a Beta distribution. Then, there are two title choices and two distributions. How will we select what to indicate to a viewer? Therefore, the algorithm is named a “multi-armed bandit.” On the time when a viewer requests a title, you “pull each arms” and pattern CTRs. After that, you examine values and present a title with the best sampled CTR. Then, the viewer both clicks or skips. If the title was clicked, you’ll alter this selection’s Beta distribution parameter “a,” representing “successes.” In any other case, you improve this selection’s Beta distribution parameter “b,” that means “failures.” This skews the distribution, and for the following viewer, there shall be a distinct likelihood of selecting this selection (or “arm”) in comparison with different choices.
After a number of iterations, the algorithm could have an estimate of CTR distributions. Sampling from this distribution will primarily set off the best CTR arm however nonetheless permit new customers to discover different choices and readjust allocation.
Properly, this all works in idea. Is it actually higher than the 50/50 cut up we now have mentioned earlier than?
All of the code to create a simulation and construct graphs could be present in my GitHub Repo.
As talked about earlier, we solely have two titles to select from. We have now no prior beliefs about CTRs of this title. So, we begin from a=1 and b=1 for each Beta distributions. I’ll simulate a easy incoming site visitors assuming a queue of viewers. We all know exactly whether or not the earlier viewer “clicked” or “skipped” earlier than exhibiting a title to the brand new viewer. To simulate “click on” and “skip” actions, I must outline some actual CTRs. Allow them to be 5% and seven%. It’s important to say that the algorithm is aware of nothing about these values. I want them to simulate a click on; you’ll have precise clicks in the actual world. I’ll flip a super-biased coin for every title that lands heads with a 5% or 7% likelihood. If it landed heads, then there’s a click on.
Then, the algorithm is easy:
- Based mostly on the noticed knowledge, get a Beta distribution for every title
- Pattern CTR from each distribution
- Perceive which CTR is greater and flip a related coin
- Perceive if there was a click on or not
- Improve parameter “a” by 1 if there was a click on; improve parameter “b” by 1 if there was a skip
- Repeat till there are customers within the queue.
To know the algorithm’s high quality, we can even save a price representing a share of viewers uncovered to the second choice because it has a better “actual” CTR. Let’s use a 50/50 cut up technique as a counterpart to have a baseline high quality.
Code by Creator
After 1000 customers within the queue, our “multi-armed bandit” already has understanding of what are the CTRs.
And here’s a graph that exhibits that such a method yields higher outcomes. After 100 viewers, the “multi-armed bandit” surpassed a 50% share of viewers supplied the second choice. As a result of increasingly proof supported the second title, the algorithm allotted increasingly site visitors to the second title. Virtually 80% of all viewers have seen the best-performing choice! Whereas within the 50/50 cut up, solely 50% of the folks have seen the best-performing choice.
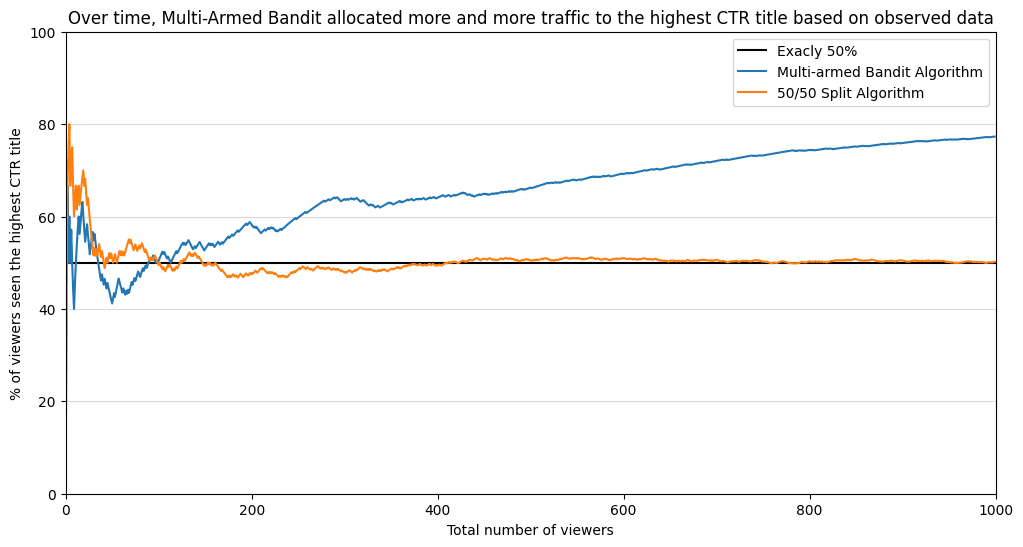
Bayesian Multi-armed Bandit uncovered a further 25% of viewers to a better-performing choice! With extra incoming knowledge, the distinction will solely improve between these two methods.
After all, “Multi-armed bandits” usually are not good. Actual-time sampling and serving of choices is dear. It will be greatest to have infrastructure to implement the entire thing with the specified latency. Furthermore, it’s possible you’ll not wish to freak out your viewers by altering titles. If in case you have sufficient site visitors to run a fast A/B, do it! Then, manually change the title as soon as. Nevertheless, this algorithm can be utilized in lots of different functions past media.
I hope you now perceive what a “multi-armed bandit” is and the way it may be used to decide on between two choices tailored to the brand new knowledge. I particularly didn’t deal with maths and formulation because the textbooks would higher clarify it. I intend to introduce a brand new expertise and spark an curiosity in it!
If in case you have any questions, don’t hesitate to achieve out on LinkedIn.
The pocket book with all of the code could be present in my GitHub repo.
Igor Khomyanin is a Information Scientist at Salmon, with prior knowledge roles at Yandex and McKinsey. I specialise in extracting worth from knowledge utilizing Statistics and Information Visualization.

