

The race to construct autonomous AI brokers has hit an enormous bottleneck: knowledge. Whereas frontier fashions like Claude Code and Codex CLI have demonstrated spectacular proficiency in terminal environments, the coaching methods and knowledge mixtures behind them have remained intently guarded secrets and techniques. This lack of transparency has pressured researchers and devs right into a expensive cycle of trial and error.
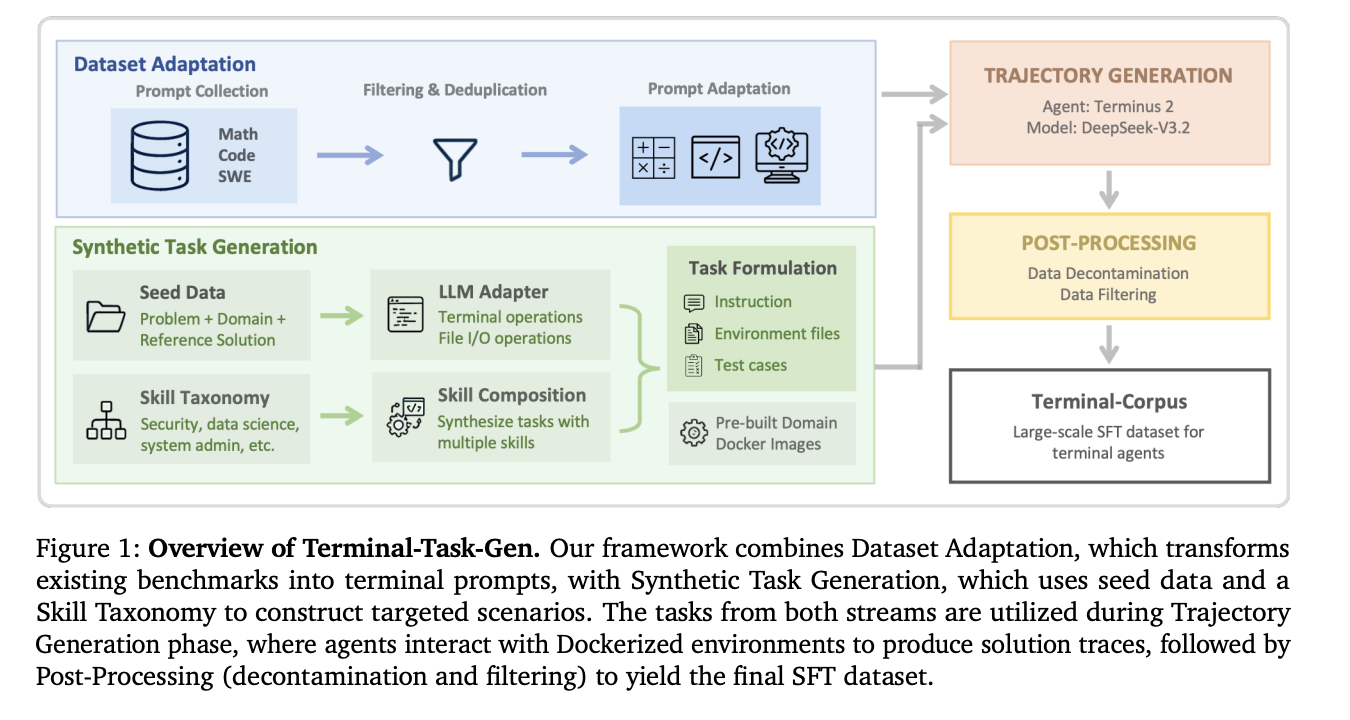
NVIDIA is now breaking that silence by unveiling a complete framework for constructing high-performance terminal brokers. By introducing Terminal-Job-Gen and the Terminal-Corpus dataset, NVIDIA is basically giving the developer neighborhood the blueprints to construct brokers that don’t simply ‘chat’ about code, however truly execute it with surgical precision.
The Knowledge Shortage Downside
The problem of coaching an agent for the command line is two-fold. First, there’s a shortage of foundational assets—particularly, various job prompts and the complicated dependency recordsdata wanted to create sensible environments. Second, capturing ‘trajectories’ (the step-by-step terminal interactions) is logistically painful. Human interactions are sluggish to document, and artificial technology through LLM brokers is prohibitively costly as a result of it requires recent Docker surroundings instantiation for each single flip.
Terminal-Job-Gen: A Two-Pronged Technique
NVIDIA’s resolution is a ‘coarse-to-fine’ knowledge technology pipeline known as Terminal-Job-Gen. It makes use of two distinct methods to scale coaching knowledge with out breaking the financial institution.
1. Dataset Adaptation (The Coarse Layer)
As a substitute of ranging from scratch, the crew leverages high-quality present Supervised High-quality-Tuning (SFT) datasets from math, code, and software program engineering (SWE) domains. They rework these static prompts into interactive terminal duties.
- Math and Code: Utilizing 163K math prompts and 35K code prompts, they wrap these challenges in a terminal scaffold.
- SWE: They pull 32K distinctive prompts from repositories like SWE-bench and SWE-reBench. The intelligent half? This course of doesn’t require an LLM “within the loop” for the preliminary adaptation, making it extremely environment friendly to scale quantity.
2. Artificial Job Era (The High-quality Layer)
To bridge the hole between common reasoning and the particular rigors of terminal company, NVIDIA crew makes use of Terminal-Job-Gen to create novel, executable duties.
- Seed-based Era: The LLM makes use of present scientific computing or algorithmic issues as “inspiration” to synthesize new duties. The agent is pressured to put in packages, learn enter recordsdata, and write outcomes—mirroring a real-world developer workflow.
- Talent-based Era: That is the place it will get technical. NVIDIA curated a taxonomy of “primitive terminal abilities” throughout 9 domains, together with Safety, Knowledge Science, and System Administration. The LLM is then instructed to mix 3–5 of those primitives (like graph traversal + community configuration + file I/O) right into a single, complicated job.
Fixing the Infrastructure Overhead
One of the vital vital engineering breakthroughs on this analysis is the transfer to Pre-Constructed Docker Photographs. Earlier frameworks typically generated a novel Dockerfile for each single job, resulting in huge build-time overhead and frequent failures. NVIDIA crew as an alternative maintains 9 shared base pictures pre-configured with important libraries (like pandas for knowledge science or cryptography instruments for safety). This ‘single-pass’ creation technique permits for enormous parallelization and a considerably smaller useful resource footprint.
Efficiency: When 32B Beats 480B
The outcomes of this data-centric method are staggering. NVIDIA crew used this pipeline to coach the Nemotron-Terminal household of fashions, initialized from Qwen3.
On the Terminal-Bench 2.0 benchmark, which checks brokers on end-to-end workflows like coaching machine studying fashions or debugging system environments, the enhancements had been vertical:
- Nemotron-Terminal-8B: Jumped from a 2.5% success charge to 13.0%.
- Nemotron-Terminal-32B: Achieved a 27.4% accuracy.
To place that in perspective, the 32B mannequin outperformed the 480B Qwen3-Coder (23.9%) and rivaled the efficiency of closed-source giants like Grok 4 (23.1%) and GPT-5-Mini (24.0%). This proves that for terminal brokers, high-quality, various trajectory knowledge is a extra highly effective lever than sheer parameter scale.
Crucial Insights
NVIDIA’s analysis additionally debunks a number of frequent myths in knowledge engineering:
- Don’t Filter Out Errors: The analysis crew discovered that preserving ‘unsuccessful’ trajectories within the coaching knowledge truly improved efficiency (12.4% vs 5.06% for success-only filtering). Exposing fashions to sensible error states and restoration patterns makes them extra sturdy.
- Skip the Curriculum: They experimented with ‘curriculum studying’ (coaching on simple knowledge earlier than arduous knowledge) however discovered that straightforward blended coaching was simply as efficient, if not higher.
- Context Size Limits: Whereas terminal trajectories could be lengthy, most high-quality supervision suits inside an ordinary 32,768-token window. Extending the context size barely damage efficiency, seemingly as a result of long-tail trajectories are typically noisier.
Take a look at Paper and HF Mission Web page. Additionally, be happy to comply with us on Twitter and don’t overlook to affix our 120k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you’ll be able to be part of us on telegram as effectively.

