
Estimated studying time: 5 minutes
Introduction
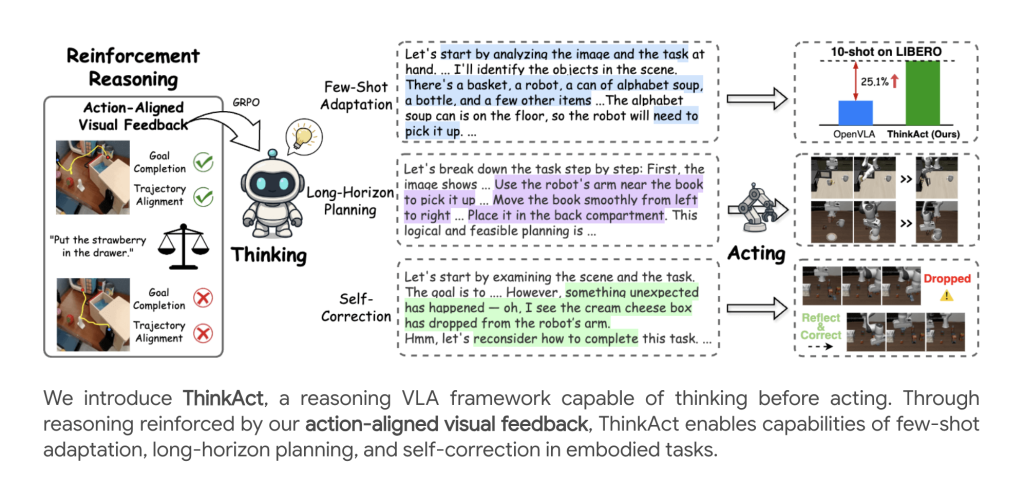
Embodied AI brokers are more and more being referred to as upon to interpret advanced, multimodal directions and act robustly in dynamic environments. ThinkAct, introduced by researchers from Nvidia and Nationwide Taiwan College, affords a breakthrough for vision-language-action (VLA) reasoning, introducing strengthened visible latent planning to bridge high-level multimodal reasoning and low-level robotic management.
Typical VLA fashions map uncooked visible and language inputs on to actions by end-to-end coaching, which limits reasoning, long-term planning, and adaptableness. Latest strategies started to include intermediate chain-of-thought (CoT) reasoning or try RL-based optimization, however struggled with scalability, grounding, or generalization when confronted with extremely variable and long-horizon robotic manipulation duties.
The ThinkAct Framework
Twin-System Structure
ThinkAct consists of two tightly built-in parts:
- Reasoning Multimodal LLM (MLLM): Performs structured, step-by-step reasoning over visible scenes and language directions, outputting a visible plan latent that encodes high-level intent and planning context.
- Motion Mannequin: A Transformer-based coverage conditioned on the visible plan latent, executing the decoded trajectory as robotic actions within the atmosphere.
This design permits asynchronous operation: the LLM “thinks” and generates plans at a gradual cadence, whereas the motion module carries out fine-grained management at greater frequency.
Strengthened Visible Latent Planning
A core innovation is the reinforcement studying (RL) method leveraging action-aligned visible rewards:
- Aim Reward: Encourages the mannequin to align the beginning and finish positions predicted within the plan with these in demonstration trajectories, supporting objective completion.
- Trajectory Reward: Regularizes the anticipated visible trajectory to intently match distributional properties of knowledgeable demonstrations utilizing dynamic time warping (DTW) distance.
Complete reward rrr blends these visible rewards with a format correctness rating, pushing the LLM to not solely produce correct solutions but additionally plans that translate into bodily believable robotic actions.
Coaching Pipeline
The multi-stage coaching process consists of:
- Supervised High-quality-Tuning (SFT): Chilly-start with manually-annotated visible trajectory and QA knowledge to show trajectory prediction, reasoning, and reply formatting.
- Strengthened High-quality-Tuning: RL optimization (utilizing Group Relative Coverage Optimization, GRPO) additional incentivizes high-quality reasoning by maximizing the newly outlined action-aligned rewards.
- Motion Adaptation: The downstream motion coverage is educated utilizing imitation studying, leveraging the frozen LLM’s latent plan output to information management throughout various environments.
Inference
At inference time, given an noticed scene and a language instruction, the reasoning module generates a visible plan latent, which then circumstances the motion module to execute a full trajectory—enabling strong efficiency even in new, beforehand unseen settings.

Experimental Outcomes
Robotic Manipulation Benchmarks
Experiments on SimplerEnv and LIBERO benchmarks reveal ThinkAct’s superiority:
- SimplerEnv: Outperforms robust baselines (e.g., OpenVLA, DiT-Coverage, TraceVLA) by 11–17% in numerous settings, particularly excelling in long-horizon and visually numerous duties.
- LIBERO: Achieves the best general success charges (84.4%), excelling in spatial, object, objective, and long-horizon challenges, confirming its potential to generalize and adapt to novel expertise and layouts.

Embodied Reasoning Benchmarks
On EgoPlan-Bench2, RoboVQA, and OpenEQA, ThinkAct demonstrates:
- Superior multi-step and long-horizon planning accuracy.
- State-of-the-art BLEU and LLM-based QA scores, reflecting improved semantic understanding and grounding for visible query answering duties.
Few-Shot Adaptation
ThinkAct permits efficient few-shot adaptation: with as few as 10 demonstrations, it achieves substantial success charge positive factors over different strategies, highlighting the ability of reasoning-guided planning for rapidly studying new expertise or environments.
Self-Reflection and Correction
Past process success, ThinkAct displays emergent behaviors:
- Failure Detection: Acknowledges execution errors (e.g., dropped objects).
- Replanning: Robotically revises plans to get well and full the duty, due to reasoning on current visible enter sequences.
Ablation Research and Mannequin Evaluation
- Reward Ablations: Each objective and trajectory rewards are important for structured planning and generalization. Eradicating both considerably drops efficiency, and relying solely on QA-style rewards limits multi-step reasoning functionality.
- Discount in Replace Frequency: ThinkAct achieves a steadiness between reasoning (gradual, planning) and motion (quick, management), permitting strong efficiency with out extreme computational demand1.
- Smaller Fashions: The method generalizes to smaller MLLM backbones, sustaining robust reasoning and motion capabilities.
Implementation Particulars
- Most important spine: Qwen2.5-VL 7B MLLM.
- Datasets: Numerous robotic and human demonstration movies (Open X-Embodiment, One thing-One thing V2), plus multimodal QA units (RoboVQA, EgoPlan-Bench, Video-R1-CoT, and many others.).
- Makes use of a imaginative and prescient encoder (DINOv2), textual content encoder (CLIP), and a Q-Former for connecting reasoning output to motion coverage enter.
- Intensive experiments on actual and simulated settings verify scalability and robustness.
Conclusion
Nvidia’s ThinkAct units a brand new customary for embodied AI brokers, proving that strengthened visible latent planning—the place brokers “assume earlier than they act”—delivers strong, scalable, and adaptive efficiency in advanced, real-world reasoning and robotic manipulation duties. Its dual-system design, reward shaping, and robust empirical outcomes pave the best way for clever, generalist robots able to long-horizon planning, few-shot adaptation, and self-correction in numerous environments.
Take a look at the Paper and Venture. All credit score for this analysis goes to the researchers of this undertaking. Additionally, be happy to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our Publication.
You may additionally like NVIDIA’s Open Sourced Cosmos DiffusionRenderer [Check it now]
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


