

As context lengths transfer into tens and a whole bunch of hundreds of tokens, the important thing worth cache in transformer decoders turns into a major deployment bottleneck. The cache shops keys and values for each layer and head with form (2, L, H, T, D). For a vanilla transformer akin to Llama1-65B, the cache reaches about 335 GB at 128k tokens in bfloat16, which instantly limits batch dimension and will increase time to first token.
Architectural compression leaves the sequence axis untouched
Manufacturing fashions already compress the cache alongside a number of axes. Grouped Question Consideration shares keys and values throughout a number of queries and yields compression elements of 4 in Llama3, 12 in GLM 4.5 and as much as 16 in Qwen3-235B-A22B, all alongside the top axis. DeepSeek V2 compresses the important thing and worth dimension via Multi head Latent Consideration. Hybrid fashions combine consideration with sliding window consideration or state house layers to scale back the variety of layers that keep a full cache.
These adjustments don’t compress alongside the sequence axis. Sparse and retrieval type consideration retrieve solely a subset of the cache at every decoding step, however all tokens nonetheless occupy reminiscence. Sensible lengthy context serving subsequently wants methods that delete cache entries which could have negligible impact on future tokens.
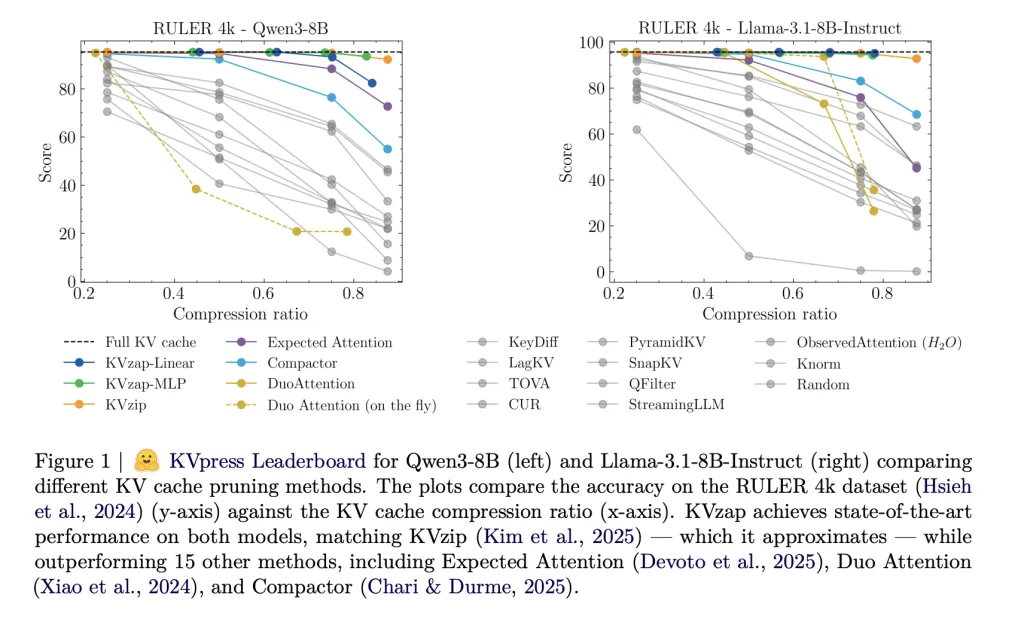
The KVpress venture from NVIDIA collects greater than twenty such pruning strategies in a single codebase and exposes them via a public leaderboard on Hugging Face. Strategies akin to H2O, Anticipated Consideration, DuoAttention, Compactor and KVzip are all evaluated in a constant method.
KVzip and KVzip plus because the scoring oracle
KVzip is at present the strongest cache pruning baseline on the KVpress Leaderboard. It defines an significance rating for every cache entry utilizing a duplicate and paste pretext process. The mannequin runs on an prolonged immediate the place it’s requested to repeat the unique context precisely. For every token place within the unique immediate, the rating is the utmost consideration weight that any place within the repeated section assigns again to that token, throughout heads in the identical group when grouped question consideration is used. Low scoring entries are evicted till a world price range is met.
KVzip+ refines this rating. It multiplies the eye weight by the norm of the worth contribution into the residual stream and normalizes by the norm of the receiving hidden state. This higher matches the precise change {that a} token induces within the residual stream and improves correlation with downstream accuracy in comparison with the unique rating.
These oracle scores are efficient however costly. KVzip requires prefilling on the prolonged immediate, which doubles the context size and makes it too sluggish for manufacturing. It additionally can’t run throughout decoding as a result of the scoring process assumes a set immediate.
KVzap, a surrogate mannequin on hidden states
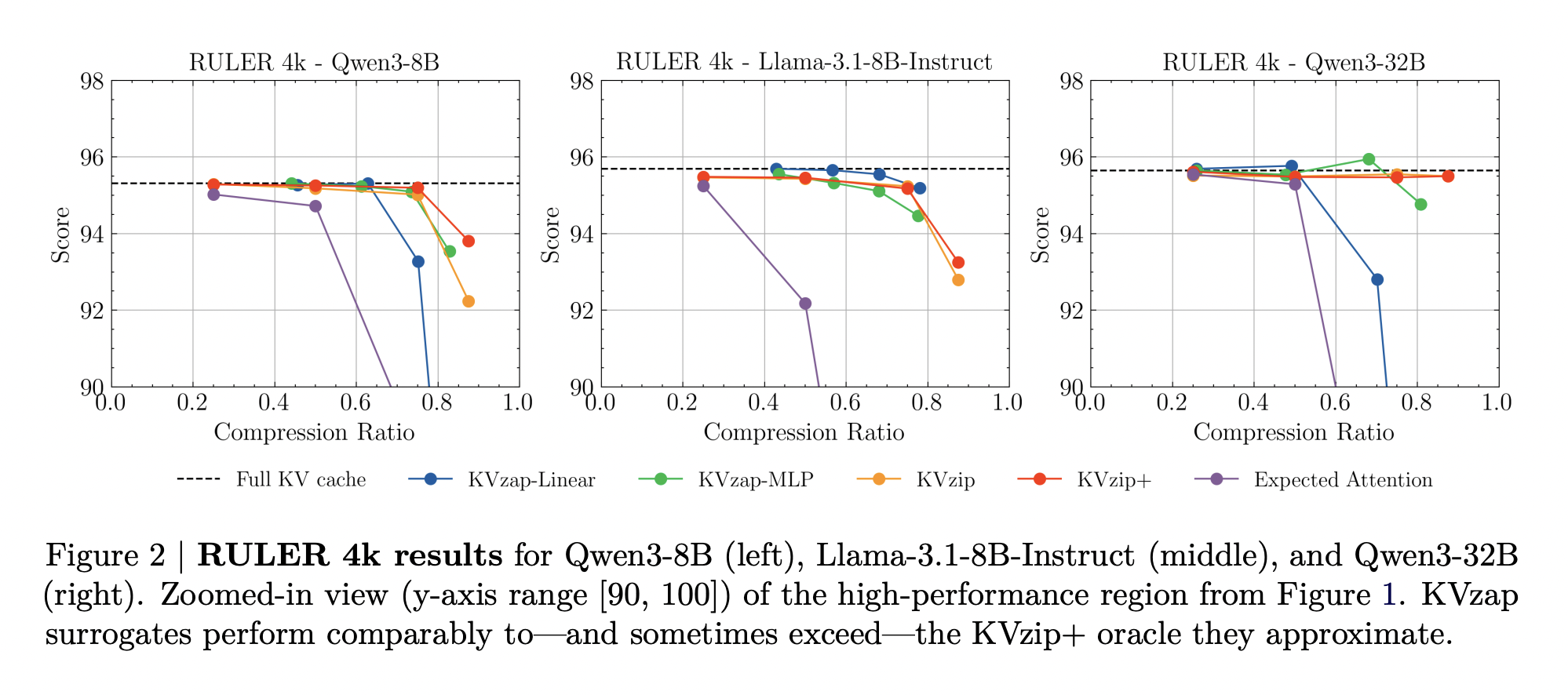
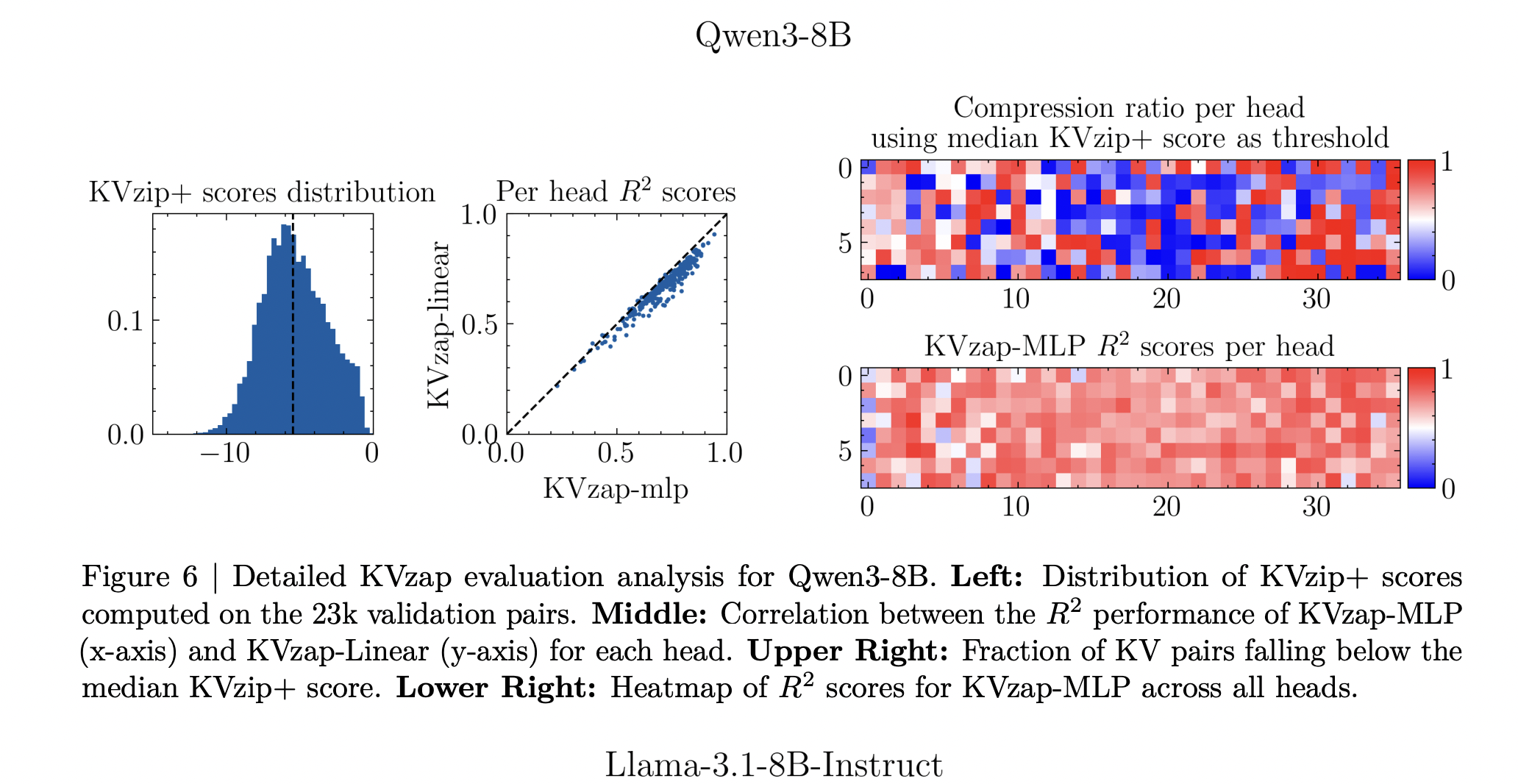
KVzap replaces the oracle scoring with a small surrogate mannequin that operates instantly on hidden states. For every transformer layer and every sequence place t, the module receives the hidden vector hₜ and outputs predicted log scores for each key worth head. Two architectures are thought-about, a single linear layer (KVzap Linear) and a two layer MLP with GELU and hidden width equal to 1 eighth of the mannequin hidden dimension (KVzap MLP).
Coaching makes use of prompts from the Nemotron Pretraining Dataset pattern. The analysis workforce filter 27k prompts to lengths between 750 and 1,250 tokens, pattern as much as 500 prompts per subset, after which pattern 500 token positions per immediate. For every key worth head they acquire about 1.2 million coaching pairs and a validation set of 23k pairs. The surrogate learns to regress from the hidden state to the log KVzip+ rating. Throughout fashions, the squared Pearson correlation between predictions and oracle scores reaches between about 0.63 and 0.77, with the MLP variant constantly outperforming the linear variant.
Thresholding, sliding window and negligible overhead
Throughout inference, the KVzap mannequin processes hidden states and produces scores for every cache entry. Entries with scores under a set threshold are pruned, whereas a sliding window of the latest 128 tokens is all the time saved. The analysis workforce offers a concise PyTorch type operate that applies the mannequin, units scores of the native window to infinity and returns compressed key and worth tensors. In all experiments, pruning is utilized after the eye operation.
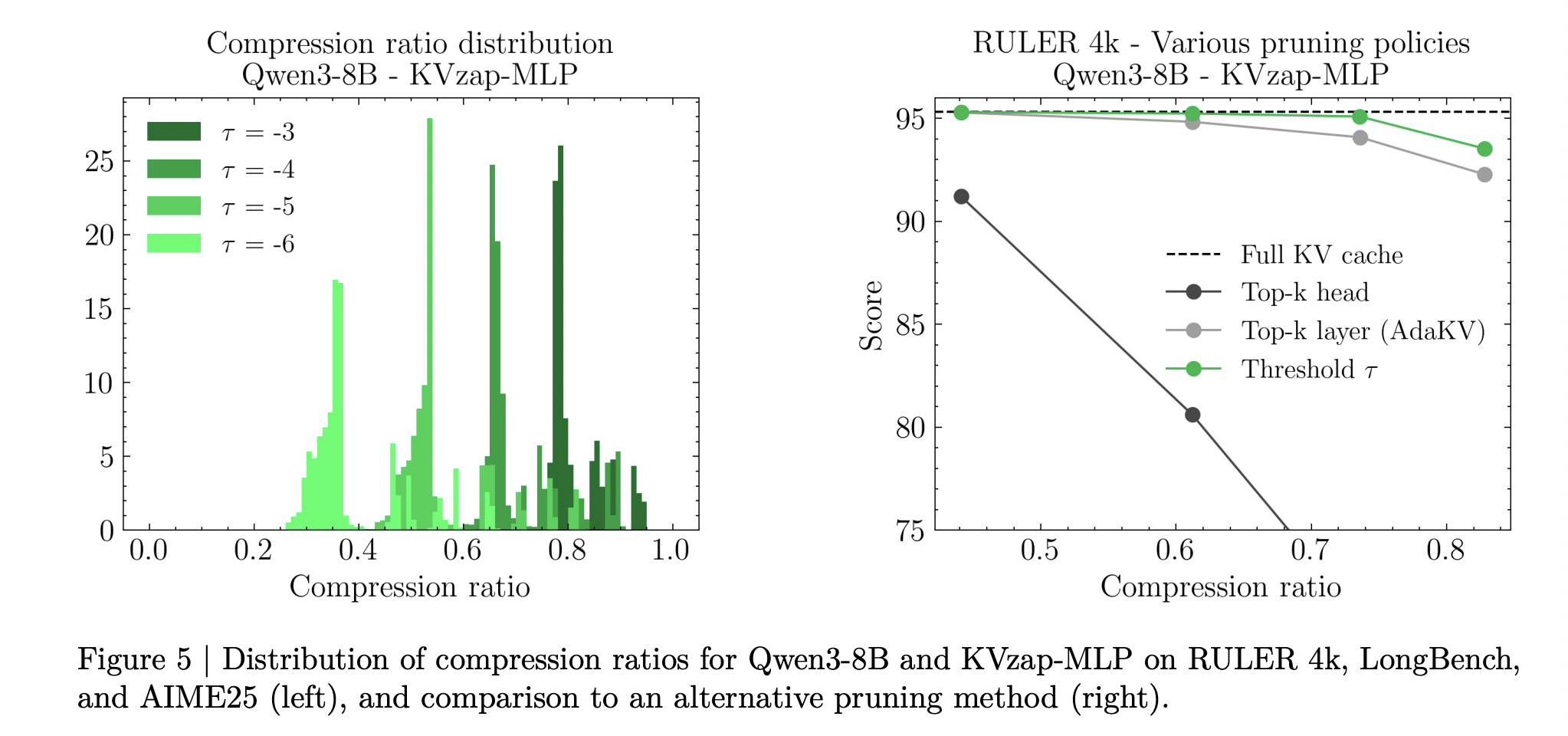
KVzap makes use of rating thresholding fairly than mounted prime okay choice. A single threshold yields totally different efficient compression ratios on totally different benchmarks and even throughout prompts throughout the similar benchmark. The analysis workforce report as much as 20 p.c variation in compression ratio throughout prompts at a set threshold, which displays variations in info density.
Compute overhead is small. An evaluation on the layer stage exhibits that the additional value of KVzap MLP is at most about 1.1 p.c of the linear projection FLOPs, whereas the linear variant provides about 0.02 p.c. The relative reminiscence overhead follows the identical values. In lengthy context regimes, the quadratic value of consideration dominates so the additional FLOPs are successfully negligible.
Outcomes on RULER, LongBench and AIME25
KVzap is evaluated on lengthy context and reasoning benchmarks utilizing Qwen3-8B, Llama-3.1-8B Instruct and Qwen3-32B. Lengthy context conduct is measured on RULER and LongBench. RULER makes use of artificial duties over sequence lengths from 4k to 128k tokens, whereas LongBench makes use of actual world paperwork from a number of process classes. AIME25 offers a math reasoning workload with 30 Olympiad stage issues evaluated underneath go at 1 and go at 4.
On RULER, KVzap matches the complete cache baseline inside a small accuracy margin whereas eradicating a big fraction of the cache. For Qwen3-8B, one of the best KVzap configuration achieves a eliminated fraction above 0.7 on RULER 4k and 16k whereas conserving the common rating inside a number of tenths of a degree of the complete cache. Related conduct holds for Llama-3.1-8B Instruct and Qwen3-32B.
On LongBench, the identical thresholds result in decrease compression ratios as a result of the paperwork are much less repetitive. KVzap stays near the complete cache baseline as much as about 2 to three instances compression, whereas mounted price range strategies akin to Anticipated Consideration degrade extra on a number of subsets as soon as compression will increase.
On AIME25, KVzap MLP maintains or barely improves go at 4 accuracy at compression close to 2 instances and stays usable even when discarding greater than half of the cache. Extraordinarily aggressive settings, for instance linear variants at excessive thresholds that take away greater than 90 p.c of entries, collapse efficiency as anticipated.
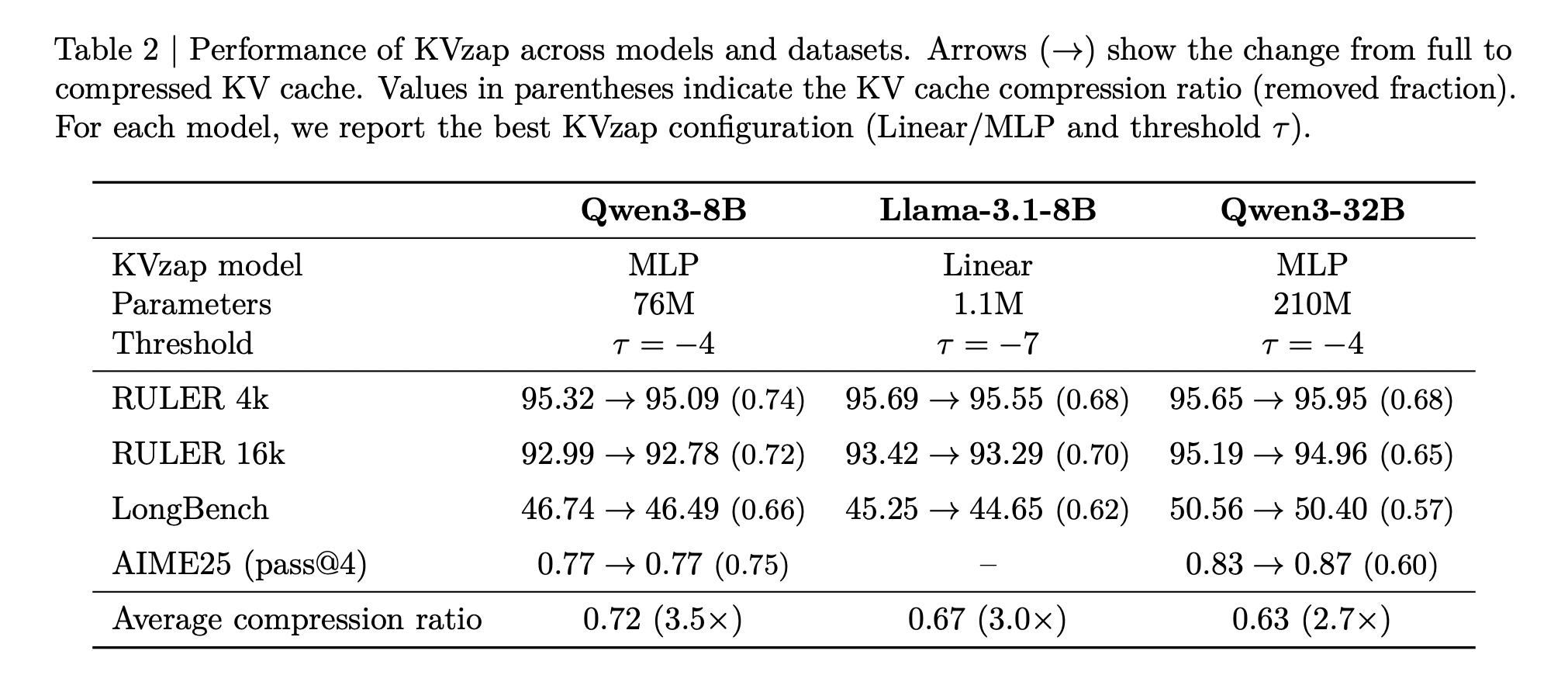
Total, the above Desk exhibits that one of the best KVzap configuration per mannequin delivers common cache compression between roughly 2.7 and three.5 whereas conserving process scores very near the complete cache baseline throughout RULER, LongBench and AIME25.
Key Takeaways
- KVzap is an enter adaptive approximation of KVzip+ that learns to foretell oracle KV significance scores from hidden states utilizing small per layer surrogate fashions, both a linear layer or a shallow MLP, after which prunes low rating KV pairs.
- Coaching makes use of Nemotron pretraining prompts the place KVzip+ offers supervision, producing about 1.2 million examples per head and attaining squared correlation within the 0.6 to 0.8 vary between predicted and oracle scores, which is enough for trustworthy cache significance rating.
- KVzap applies a world rating threshold with a set sliding window of latest tokens, so compression routinely adapts to immediate info density, and the analysis workforce report as much as 20 p.c variation in achieved compression throughout prompts on the similar threshold.
- Throughout Qwen3-8B, Llama-3.1-8B Instruct and Qwen3-32B on RULER, LongBench and AIME25, KVzap reaches about 2 to 4 instances KV cache compression whereas conserving accuracy very near the complete cache, and it achieves state-of-the-art tradeoffs on the NVIDIA KVpress Leaderboard.
- The extra compute is small, at most about 1.1 p.c further FLOPs for the MLP variant, and KVzap is carried out within the open supply kvpress framework with prepared to make use of checkpoints on Hugging Face, which makes it sensible to combine into present lengthy context LLM serving stacks.
Try the Paper and GitHub Repo. Additionally, be at liberty to comply with us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you possibly can be a part of us on telegram as effectively.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

