

NVIDIA has simply launched its new streaming English transcription mannequin (Nemotron Speech ASR) constructed particularly for low latency voice brokers and reside captioning. The checkpoint nvidia/nemotron-speech-streaming-en-0.6b on Hugging Face combines a cache conscious FastConformer encoder with an RNNT decoder, and is tuned for each streaming and batch workloads on fashionable NVIDIA GPUs.
Mannequin design, structure and enter assumptions
Nemotron Speech ASR (Automated Speech Recognition) is a 600M parameter mannequin based mostly on a cache conscious FastConformer encoder with 24 layers and an RNNT decoder. The encoder makes use of aggressive 8x convolutional downsampling to cut back the variety of time steps, which immediately lowers compute and reminiscence prices for streaming workloads. The mannequin consumes 16 kHz mono audio and requires not less than 80 ms of enter audio per chunk.
Runtime latency is managed via configurable context sizes. The mannequin exposes 4 customary chunk configurations, equivalent to about 80 ms, 160 ms, 560 ms and 1.12 s of audio. These modes are pushed by the att_context_size parameter, which units left and proper consideration context in multiples of 80 ms frames, and could be modified at inference time with out retraining.
Cache conscious streaming, not buffered sliding home windows
Conventional ‘streaming ASR’ typically makes use of overlapping home windows. Every incoming window reprocesses a part of the earlier audio to take care of context, which wastes compute and causes latency to float upward as concurrency will increase.
Nemotron Speech ASR as a substitute retains a cache of encoder states for all self consideration and convolution layers. Every new chunk is processed as soon as, with the mannequin reusing cached activations reasonably than recomputing overlapping context. This provides:
- Non overlapping body processing, so work scales linearly with audio size
- Predictable reminiscence development, as a result of cache measurement grows with sequence size reasonably than concurrency associated duplication
- Steady latency beneath load, which is essential for flip taking and interruption in voice brokers
Accuracy vs latency: WER beneath streaming constraints
Nemotron Speech ASR is evaluated on the Hugging Face OpenASR leaderboard datasets, together with AMI, Earnings22, Gigaspeech and LibriSpeech. Accuracy is reported as phrase error price (WER) for various chunk sizes.
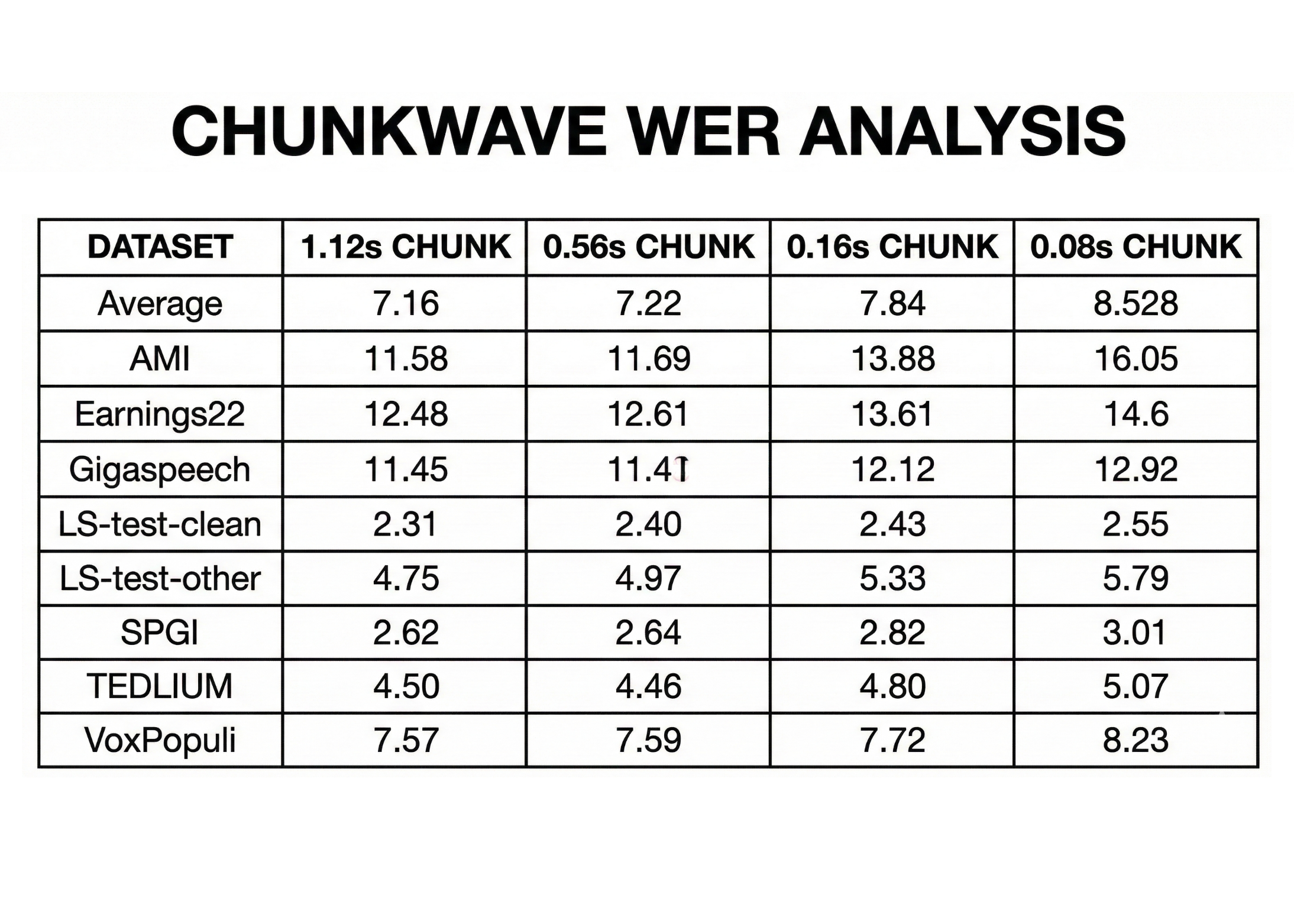
For a median throughout these benchmarks, the mannequin achieves:
- About 7.84 % WER at 0.16 s chunk measurement
- About 7.22 % WER at 0.56 s chunk measurement
- About 7.16 % WER at 1.12 s chunk measurement
This illustrates the latency accuracy tradeoff. Bigger chunks give extra phonetic context and barely decrease WER, however even the 0.16 s mode retains WER beneath 8 % whereas remaining usable for actual time brokers. Builders can select the working level at inference time relying on utility wants, for instance 160 ms for aggressive voice brokers, or 560 ms for transcription centric workflows.
Throughput and concurrency on fashionable GPUs
The cache conscious design has measurable affect on concurrency. On an NVIDIA H100 GPU, Nemotron Speech ASR helps about 560 concurrent streams at a 320 ms chunk measurement, roughly 3x the concurrency of a baseline streaming system on the identical latency goal. RTX A5000 and DGX B200 benchmarks present comparable throughput beneficial properties, with greater than 5x concurrency on A5000 and as much as 2x on B200 throughout typical latency settings.
Equally vital, latency stays secure as concurrency will increase. In Modal’s exams with 127 concurrent WebSocket purchasers at 560 ms mode, the system maintained a median finish to finish delay round 182 ms with out drift, which is important for brokers that should keep synchronized with reside speech over multi minute periods.
Coaching knowledge and ecosystem integration
Nemotron Speech ASR is educated primarily on the English portion of NVIDIA’s Granary dataset together with a big combination of public speech corpora, for a complete of about 285k hours of audio. Datasets embody YouTube Commons, YODAS2, Mosel, LibriLight, Fisher, Switchboard, WSJ, VCTK, VoxPopuli and a number of Mozilla Frequent Voice releases. Labels mix human and ASR generated transcripts.
Key Takeaways
- Nemotron Speech ASR is a 0.6B parameter English streaming mannequin that makes use of a cache conscious FastConformer encoder with an RNNT decoder and operates on 16 kHz mono audio with not less than 80 ms enter chunks.
- The mannequin exposes 4 inference time chunk configurations, about 80 ms, 160 ms, 560 ms and 1.12 s, which let engineers commerce latency for accuracy with out retraining whereas holding WER round 7.2 % to 7.8 % on customary ASR benchmarks.
- Cache conscious streaming removes overlapping window recomputation so every audio body is encoded as soon as, which yields about 3 instances larger concurrent streams on H100, greater than 5 instances on RTX A5000 and as much as 2 instances on DGX B200 in comparison with a buffered streaming baseline at comparable latency.
- In an finish to finish voice agent with Nemotron Speech ASR, Nemotron 3 Nano 30B and Magpie TTS, measured median time to last transcription is about 24 ms and server facet voice to voice latency on RTX 5090 is round 500 ms, which makes ASR a small fraction of the overall latency funds.
- Nemotron Speech ASR is launched as a NeMo checkpoint beneath the NVIDIA Permissive Open Mannequin License with open weights and coaching particulars, so groups can self host, fantastic tune and profile the total stack for low latency voice brokers and speech functions.
Take a look at the MODEL WEIGHTS right here. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be a part of us on telegram as properly.
Take a look at our newest launch of ai2025.dev, a 2025-focused analytics platform that turns mannequin launches, benchmarks, and ecosystem exercise right into a structured dataset you possibly can filter, evaluate, and export
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

