

The generative AI panorama is dominated by large language fashions, usually designed for the huge capacities of cloud knowledge facilities. These fashions, whereas highly effective, make it tough or inconceivable for on a regular basis customers to deploy superior AI privately and effectively on native gadgets like laptops, smartphones, or embedded techniques. As an alternative of compressing cloud-scale fashions for the sting—usually leading to substantial efficiency compromises—the crew behind SmallThinker requested a extra elementary query: What if a language mannequin had been architected from the beginning for native constraints?
This was the genesis for SmallThinker, a household of Combination-of-Specialists (MoE) fashions developed by Researchers at Shanghai Jiao Tong College and Zenergize AI, that targets at high-performance, memory-limited, and compute-constrained on-device inference. With two important variants—SmallThinker-4B-A0.6B and SmallThinker-21B-A3B—they set a brand new benchmark for environment friendly, accessible AI.
Native Constraints Turn into Design Ideas
Architectural Improvements

Superb-Grained Combination-of-Specialists (MoE):
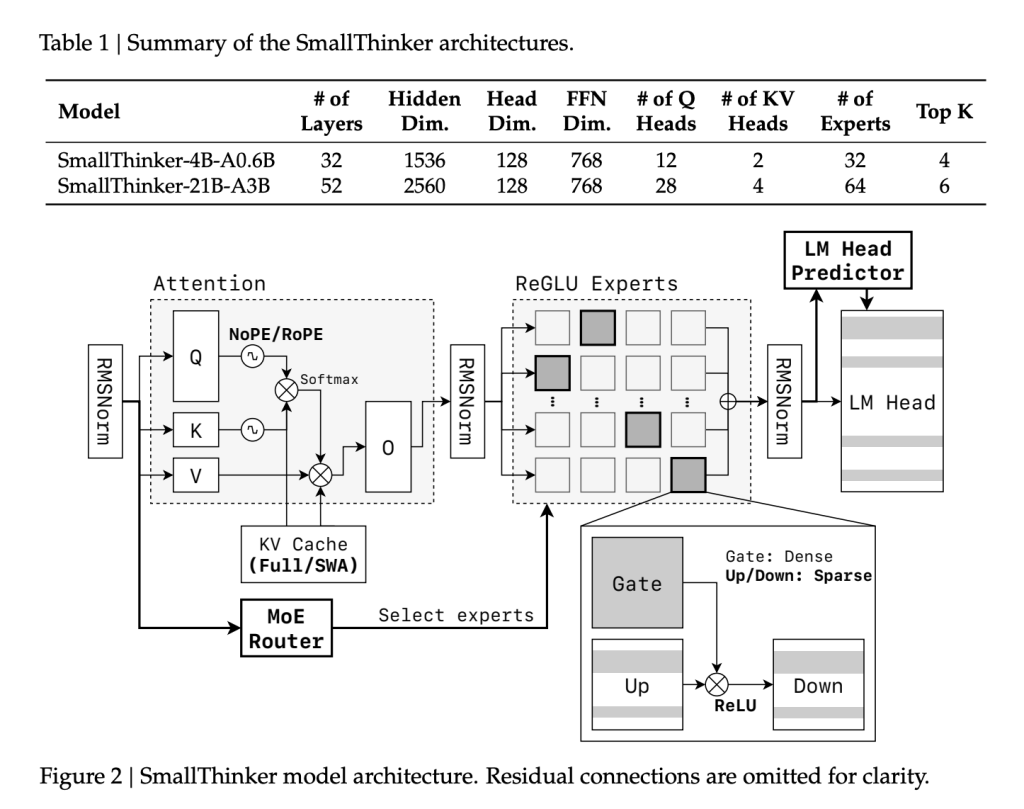
Not like typical monolithic LLMs, SmallThinker’s spine incorporates a fine-grained MoE design. A number of specialised knowledgeable networks are educated, however solely a small subset is activated for every enter token:
- SmallThinker-4B-A0.6B: 4 billion parameters in whole, with simply 600 million in play per token.
- SmallThinker-21B-A3B: 21 billion parameters, of which solely 3 billion are energetic directly.
This permits excessive capability with out the reminiscence and computation penalties of dense fashions.
ReGLU-Primarily based Feed-Ahead Sparsity:
Activation sparsity is additional enforced utilizing ReGLU. Even inside activated specialists, over 60% of neurons are idle per inference step, realizing large compute and reminiscence financial savings.
NoPE-RoPE Hybrid Consideration:
For environment friendly context dealing with, SmallThinker employs a novel consideration sample: alternating between world NoPositionalEmbedding (NoPE) layers and native RoPE sliding-window layers. This strategy helps giant context lengths (as much as 32K tokens for 4B and 16K for 21B) however trims the Key/Worth cache measurement in comparison with conventional all-global consideration.
Pre-Consideration Router and Clever Offloading:
Vital to on-device use is the decoupling of inference velocity from sluggish storage. SmallThinker’s “pre-attention router” predicts which specialists might be wanted earlier than every consideration step, so their parameters are prefetched from SSD/flash in parallel with computation. The system depends on caching “scorching” specialists in RAM (utilizing an LRU coverage), whereas less-used specialists stay on quick storage. This design primarily hides I/O lag and maximizes throughput even with minimal system reminiscence.
Coaching Regime and Knowledge Procedures
SmallThinker fashions had been educated afresh, not as distillations, on a curriculum that progresses from common data to extremely specialised STEM, mathematical, and coding knowledge:
- The 4B variant processed 2.5 trillion tokens; the 21B mannequin noticed 7.2 trillion.
- Knowledge comes from a mix of curated open-source collections, augmented artificial math and code datasets, and supervised instruction-following corpora.
- Methodologies included quality-filtering, MGA-style knowledge synthesis, and persona-driven immediate methods—notably to lift efficiency in formal and reasoning-heavy domains.
Benchmark Outcomes
On Tutorial Duties:
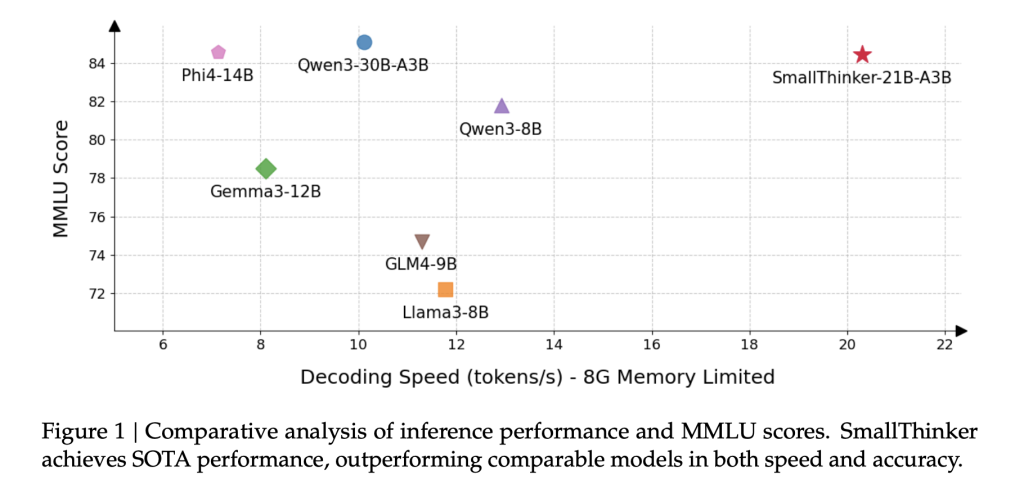
SmallThinker-21B-A3B, regardless of activating far fewer parameters than equal rivals, stands shoulder to shoulder with or beats them in fields starting from arithmetic (MATH-500, GPQA-Diamond) to code technology (HumanEval) and broad data assessments (MMLU):
| Mannequin | MMLU | GPQA | Math-500 | IFEval | LiveBench | HumanEval | Common |
|---|---|---|---|---|---|---|---|
| SmallThinker-21B-A3B | 84.4 | 55.1 | 82.4 | 85.8 | 60.3 | 89.6 | 76.3 |
| Qwen3-30B-A3B | 85.1 | 44.4 | 84.4 | 84.3 | 58.8 | 90.2 | 74.5 |
| Phi-4-14B | 84.6 | 55.5 | 80.2 | 63.2 | 42.4 | 87.2 | 68.8 |
| Gemma3-12B-it | 78.5 | 34.9 | 82.4 | 74.7 | 44.5 | 82.9 | 66.3 |
The 4B-A0.6B mannequin additionally outperforms or matches different fashions with related activated parameter counts, notably excelling in reasoning and code.
On Actual {Hardware}:
The place SmallThinker actually shines is on memory-starved gadgets:
- The 4B mannequin works comfortably with as little as 1 GiB RAM, and the 21B mannequin with simply 8 GiB, with out catastrophic velocity drops.
- Prefetching and caching imply that even underneath these limits, inference stays vastly sooner and smoother than baseline fashions merely swapped to disk.
For instance, the 21B-A3B variant maintains over 20 tokens/sec on an ordinary CPU, whereas Qwen3-30B-A3B practically crashes underneath related reminiscence constraints.
Impression of Sparsity and Specialization
Skilled Specialization:
Activation logs reveal that 70–80% of specialists are sparsely used, whereas a core few “hotspot” specialists gentle up for particular domains or languages—a property which allows extremely predictable and environment friendly caching.
Neuron-Degree Sparsity:
Even inside energetic specialists, median neuron inactivity charges exceed 60%. Early layers are virtually completely sparse, whereas deeper layers retain this effectivity, illustrating why SmallThinker manages to take action a lot with so little compute.
System Limitations and Future Work
Whereas the achievements are substantial, SmallThinker isn’t with out caveats:
- Coaching Set Measurement: Its pretraining corpus, although large, remains to be smaller than these behind some frontier cloud fashions—probably limiting generalization in uncommon or obscure domains.
- Mannequin Alignment: Solely supervised fine-tuning is utilized; not like main cloud LLMs, no reinforcement studying from human suggestions is used, presumably leaving some security and helpfulness gaps.
- Language Protection: English and Chinese language, with STEM, dominate coaching—different languages might even see diminished high quality.
The authors anticipate increasing the datasets and introducing RLHF pipelines in future variations.
Conclusion
SmallThinker represents a radical departure from the “shrink cloud fashions for edge” custom. By ranging from local-first constraints, it delivers excessive functionality, excessive velocity, and low reminiscence use by architectural and techniques innovation. This opens the door for personal, responsive, and succesful AI on practically any system—democratizing superior language expertise for a much wider swath of customers and use circumstances.
The fashions—SmallThinker-4B-A0.6B-Instruct and SmallThinker-21B-A3B-Instruct—are freely obtainable for researchers and builders, and stand as compelling proof of what’s potential when mannequin design is pushed by deployment realities, not simply data-center ambition.
Try the Paper, SmallThinker-4B-A0.6B-Instruct and SmallThinker-21B-A3B-Instruct right here. Be at liberty to examine our Tutorials web page on AI Agent and Agentic AI for numerous purposes. Additionally, be happy to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our Publication.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

