

Robots are getting into their GPT-3 period. For years, researchers have tried to coach robots utilizing the identical autoregressive (AR) fashions that energy massive language fashions (LLMs). If a mannequin can predict the following phrase in a sentence, it ought to be capable to predict the following transfer for a robotic arm. Nonetheless, a technical wall has blocked this progress: steady robotic actions are troublesome to show into discrete tokens.
A group of researchers from Harvard College and Stanford College have launched a brand new framework known as Ordered Motion Tokenization (OAT) to bridge this hole.
The Messy Actuality of Robotic Actions
Tokenization turns advanced knowledge right into a sequence of discrete numbers (tokens). For robots, these actions are steady alerts like joint angles. Earlier methods had deadly flaws:
- Binning: Turns each motion dimension right into a ‘bin.’ Whereas easy, it creates large sequences that make coaching and inference gradual.
- FAST (Frequency-space Motion Sequence Tokenization): Makes use of math to compress actions into frequency coefficients. It’s quick however typically produces ‘undecodable’ sequences the place small errors trigger the robotic to halt or transfer unpredictably.
- Realized Latent Tokenizers: These use a realized ‘dictionary’ of actions. They’re protected however lack a selected order, which means the mannequin treats early and late tokens as equally vital.

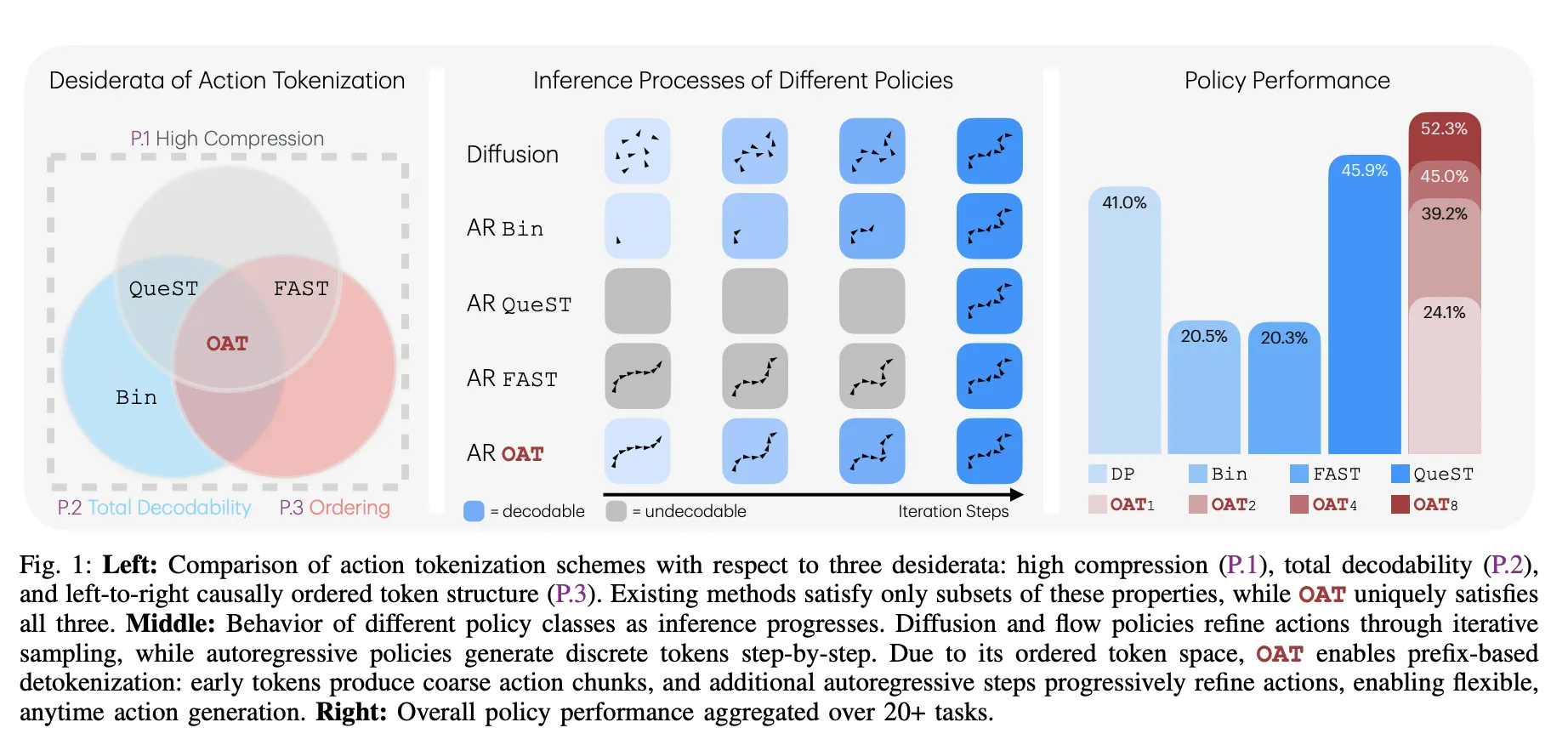
The Three Golden Guidelines of OAT
The analysis group recognized 3 important properties—desiderata—for a practical robotic tokenizer:
- Excessive Compression (P.1): Token sequences have to be quick to maintain fashions environment friendly.
- Whole Decodability (P.2): The decoder have to be a complete operate, guaranteeing each doable token sequence maps to a sound motion.
- Causal Ordering (P.3): Tokens will need to have a left-to-right construction the place early tokens seize international movement and later tokens refine particulars.
The Secret Sauce: Nested Dropout and Registers
OAT makes use of a transformer encoder with register tokens to summarize motion chunks. To drive the mannequin to study ‘vital’ issues first, the analysis group used a modern method known as Nested Dropout.

Breaking the Benchmarks
The analysis group examined OAT throughout 20+ duties in 4 main simulation benchmarks. OAT constantly outperformed the industry-standard Diffusion Coverage (DP) and former tokenizers.
Efficiency Outcomes
| Benchmark | OAT Success Charge | DP Success Charge | Bin Token Depend | OAT Token Depend |
| LIBERO | 56.3% | 36.6% | 224 | 8 |
| RoboMimic | 73.1% | 67.1% | 224 | 8 |
| MetaWorld | 24.4% | 19.3% | 128 | 8 |
| RoboCasa | 54.6% | 54.0% | 384 | 8 |
‘Anytime’ Inference: Velocity vs. Precision
Probably the most sensible good thing about OAT is prefix-based detokenization. Because the tokens are ordered by significance, you may cease the mannequin early.
- Coarse Actions: Decoding simply 1 or 2 tokens offers the robotic a basic route shortly, which is helpful for low-latency duties.
- Tremendous Actions: Producing all 8 tokens offers the high-precision particulars wanted for advanced insertions.
This enables for a easy trade-off between computation value and motion constancy that earlier fixed-length tokenizers couldn’t supply.
Key Takeaways
- Fixing the Tokenization Hole: OAT addresses a basic limitation in making use of autoregressive fashions to robotics by introducing a realized tokenizer that concurrently achieves excessive compression, whole decodability, and causal ordering.
- Ordered Illustration by way of Nested Dropout: By using nested dropout throughout coaching, OAT forces the mannequin to prioritize international, coarse movement patterns in early tokens whereas reserving later tokens for fine-grained refinements.
- Whole Decodability and Reliability: In contrast to prior frequency-domain strategies like FAST, OAT ensures the detokenizer is a complete operate, which means each doable token sequence generates a sound motion chunk, stopping runtime execution failures.
- Versatile ‘Anytime’ Inference: The ordered construction permits prefix-based decoding, permitting robots to execute coarse actions from only one or two tokens to save lots of computation or full eight-token sequences for high-precision duties.
- Superior Efficiency Throughout Benchmarks: Autoregressive insurance policies outfitted with OAT constantly outperform diffusion-based baselines and different tokenization schemes, attaining a 52.3% mixture success charge and superior leads to real-world ‘Decide & Place’ and ‘Stack Cups’ duties.
Try the Paper, Repo and Challenge Web page. Additionally, be happy to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you may be a part of us on telegram as nicely.

Michal Sutter is an information science skilled with a Grasp of Science in Information Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at reworking advanced datasets into actionable insights.


