
Large vision-language fashions, or LVLMs, can interpret visible cues and supply simple replies for customers to work together with. That is achieved by skillfully fusing giant language fashions (LLMs) with large-scale visible instruction finetuning. Nonetheless, LVLMs solely want hand-crafted or LLM-generated datasets for alignment by supervised fine-tuning (SFT). Though it really works properly to vary LVLMs from caption mills to fashions that obey directions, LVLMs can nonetheless produce replies which can be hurtful, ill-intentioned, or ineffective. This means that they nonetheless must be extra aligned with human preferences. Moreover, whereas earlier analysis encourages the group of visible instruction tuning samples in multi-turn varieties, the LVLMs’ capability to work together is proscribed by the weak connections and interdependence between completely different turns. Right here, the interplay potential assesses how properly LVLMs can alter their replies utilizing the prior context in multi-turn interactions. These two drawbacks restrict the sensible use of LVLMs as visible helpers.
The analysis crew from SRI Worldwide and the College of Illinois Urbana-Champaign presents DRESS, an LVLM that’s uniquely taught utilizing Pure Language Suggestions (NLF) produced by LLMs on this work (consult with Determine 1). The analysis crew instructs LLMs to supply fine-grained suggestions on the LVLM’s replies by offering them with particular guidelines and in depth picture annotation. In step with the method of making human-aligned LLMs, this suggestions annotation considers the three H standards: helpfulness, honesty, and harmlessness. The suggestions measures the replies’ total high quality alongside the 3H standards and offers a numerical rating and NLF. The analysis crew’s technique divides NLF into critique and refining. It is a novel classification. Whereas the refinement NLF provides exact suggestions to LVLMs on bettering their replies to align with the bottom fact reference, the critique NLF evaluates the responses’ strengths and faults. This classification offers a pure utility of two sorts of NLF to make LVLMs extra palatable to people and improve their interplay capabilities.
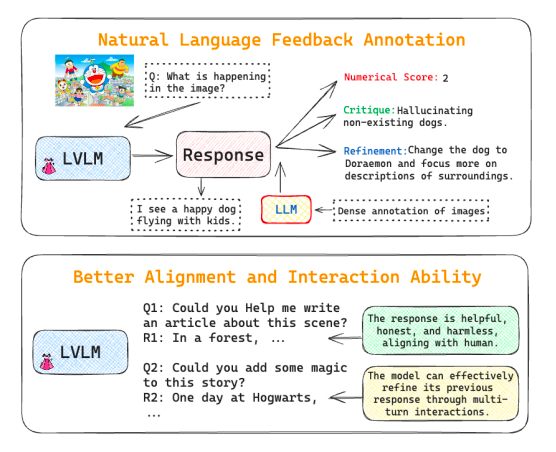
The analysis crew generalizes the conditional reinforcement studying method to fulfill the non-differentiable character of NLF and trains the LVLMs with such suggestions. Particularly, the analysis crew makes use of linguistic modeling (LM) loss on the replies to coach DRESS to generate equal responses conditioned on the 2 NLFs. The analysis crew refines DRESS by analyzing and deciphering the numerical outcomes to match person preferences higher. By way of multi-turn interactions throughout inference, the analysis crew trains DRESS to be taught the meta-skill of refining its unique replies by using refinement NLF.
The analysis crew assesses DRESS on multi-turn interactions, adversarial prompting for harmlessness evaluation, image captioning for honesty evaluation, and open-ended visible query responding for helpfulness analysis. The experiments’ findings present that, in comparison with earlier LVLMs, DRESS can present replies that align with human values and have superior interplay capabilities that enable it to be taught from suggestions and modify responses as wanted effectively. To their information, the analysis crew’s effort is the primary to handle the interplay potential and all three 3H standards for LVLMs.
The analysis crew’s contributions are summed up as follows:
• The analysis crew suggests utilizing pure language suggestions (NLF), which can be divided into critique and refining NLF, to reinforce LVLMs’ potential to work together and align with human preferences.
• By coaching the mannequin to supply matching responses conditioned on the NLF, the analysis crew generalizes the conditional reinforcement studying technique to accommodate the non-differentiable NLF efficiently. In comparison with the earlier SOTA, the analysis crew’s prompt mannequin, DRESS, demonstrates relative enhancements of 9.76%, 11.52%, and 21.03% primarily based on a scientific analysis of helpfulness, honesty, and harmlessness alignment.
• The analysis group generates and makes 63K annotated language NLF examples accessible for public use, together with 3H traits. Moreover, the analysis crew created a publicly accessible dataset of 4.7K samples for harmlessness alignment and LVLM evaluation.
Try the Paper and Dataset. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to affix our 33k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and Electronic mail Publication, the place we share the newest AI analysis information, cool AI initiatives, and extra.
In the event you like our work, you’ll love our e-newsletter..
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at the moment pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on initiatives aimed toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is obsessed with constructing options round it. He loves to attach with folks and collaborate on fascinating initiatives.

