
Within the ever-evolving area of synthetic intelligence, the pursuit of large-scale deep-learning fashions able to dealing with advanced duties has been on the forefront. These fashions, typically powered by billions of parameters, have demonstrated outstanding capabilities in numerous purposes, from pure language understanding to pc imaginative and prescient. Nonetheless, there’s a catch – constructing and coaching such colossal fashions historically calls for astronomical prices and substantial computational sources, typically rendering them inaccessible to smaller corporations, impartial builders, and researchers. Enter Colossal-AI, a pioneering analysis crew dedicated to democratizing entry to massive fashions by way of modern coaching strategies.
The issue is the exorbitant price of coaching large-scale deep-learning fashions from scratch. Typical approaches necessitate huge quantities of information, computational energy, and monetary sources. This prohibitive barrier to entry has lengthy discouraged many from venturing into the realm of huge fashions. It’s not unusual for business insiders to humorously discuss with this area as reserved just for these with “50 million {dollars}” to spare. This case has stifled innovation and restricted the accessibility of state-of-the-art AI fashions.
Colossal-AI’s groundbreaking answer comes from Colossal-LLaMA-2, an modern strategy to coaching massive fashions that defies conference. In contrast to conventional strategies that eat trillions of information tokens and incur astronomical prices, Colossal-LLaMA-2 achieves outstanding outcomes with just some hundred {dollars}. This strategy opens up the potential of establishing massive fashions from scratch with out breaking the financial institution.
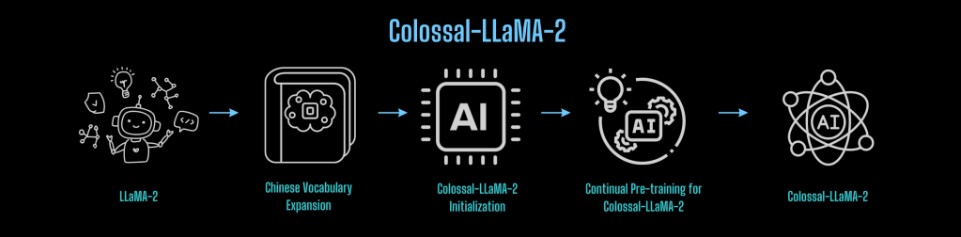
The success of Colossal-LLaMA-2 could be attributed to a number of key methods. Firstly, the analysis crew expanded the mannequin’s vocabulary considerably. This growth improved the effectivity of encoding string sequences and enriched the encoded sequences with extra significant info, enhancing document-level encoding and understanding. Nonetheless, the crew was cautious to take care of the vocabulary, as an excessively massive vocabulary would enhance the variety of embedding-related parameters, impacting coaching effectivity.
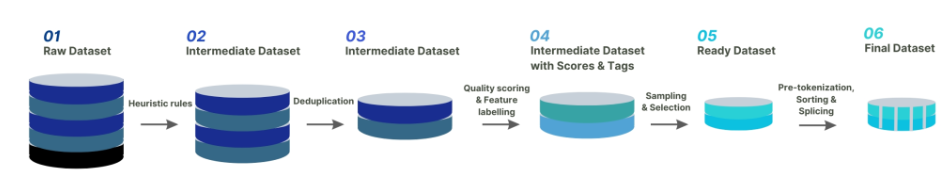
To additional scale back coaching prices and improve effectivity, high-quality information performed an important function. The crew developed an entire information cleansing system and toolkit for choosing higher-quality information for continuous pre-training. This strategy stimulated the mannequin’s capabilities and addressed the difficulty of catastrophic forgetting.
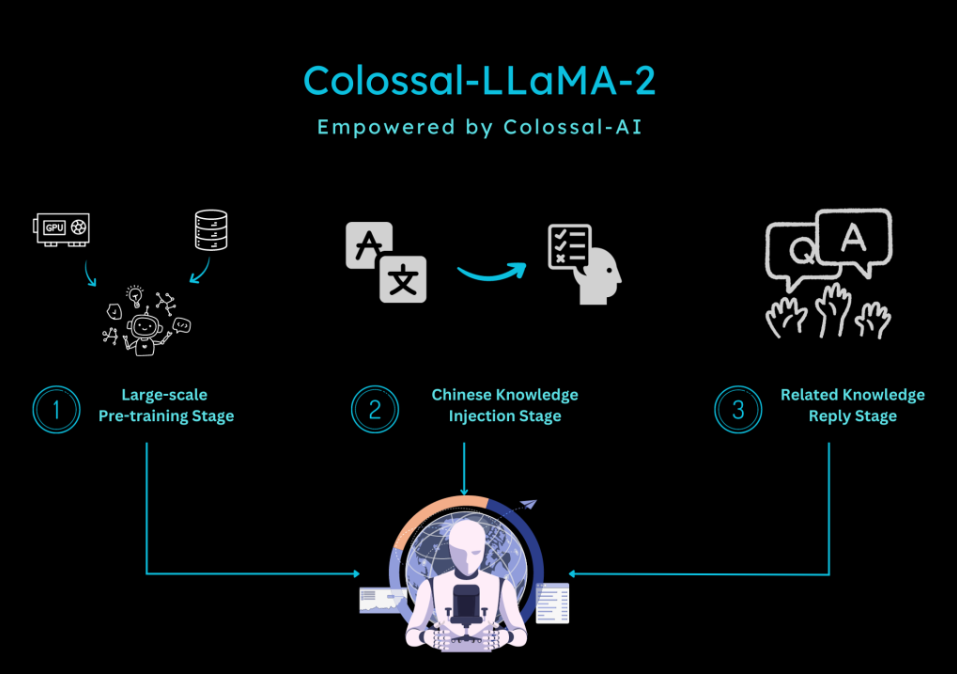
Colossal-LaMA-2′s coaching technique is one other essential part of its success. It makes use of a multi-stage, hierarchical, continuous pre-training scheme that progresses in three levels: large-scale pre-training, Chinese language information injection, and related information replay. This strategy ensures that the mannequin evolves successfully in Chinese language and English, making it versatile and able to dealing with a variety of duties.
Information distribution steadiness is paramount in continuous pre-training, and to realize this, the crew designed a knowledge bucketing technique, dividing the identical kind of information into ten completely different bins. This ensures that the mannequin can make the most of each sort of information evenly.
Efficiency is assessed comprehensively by way of the ColossalEval framework, which evaluates massive language fashions from numerous dimensions, together with information reserve functionality, multiple-choice questions, content material era, and extra. Colossal-LaMA-2 persistently outperforms its opponents in these evaluations, showcasing its robustness and flexibility.
In conclusion, Colossal-LLaMA-2 represents a outstanding breakthrough in large-scale deep-learning fashions. By drastically lowering coaching prices and enhancing accessibility, it brings the ability of state-of-the-art fashions to a wider viewers. The implications of this development are profound. Smaller corporations, impartial builders, and researchers at the moment are dealing with insurmountable obstacles in relation to leveraging the capabilities of huge fashions. This democratization of AI has the potential to spark innovation throughout numerous domains and speed up the event and deployment of AI purposes.
Try the Reference Article. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t neglect to affix our 31k+ ML SubReddit, 40k+ Fb Group, Discord Channel, and E mail Publication, the place we share the most recent AI analysis information, cool AI tasks, and extra.
In the event you like our work, you’ll love our publication..
Madhur Garg is a consulting intern at MarktechPost. He’s at the moment pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Know-how (IIT), Patna. He shares a robust ardour for Machine Studying and enjoys exploring the most recent developments in applied sciences and their sensible purposes. With a eager curiosity in synthetic intelligence and its various purposes, Madhur is decided to contribute to the sphere of Information Science and leverage its potential impression in numerous industries.


