

Can a completely sovereign open reasoning mannequin match state-of-the-art methods when each a part of its coaching pipeline is clear. Researchers from Mohamed bin Zayed College of Synthetic Intelligence (MBZUAI) launch K2 Suppose V2, a completely sovereign reasoning mannequin designed to check how far open and totally documented pipelines can push lengthy horizon reasoning on math, code, and science when the complete stack is open and reproducible. K2 Suppose V2 takes the 70 billion parameter K2 V2 Instruct base mannequin and applies a fastidiously engineered reinforcement studying method to show it right into a excessive precision reasoning mannequin that continues to be totally open in each weights and information.

From K2 V2 base mannequin to reasoning specialist
K2 V2 is a dense decoder solely transformer with 80 layers, hidden measurement 8192, and 64 consideration heads with grouped question consideration and rotary place embeddings. It’s skilled on round 12 trillion tokens drawn from the TxT360 corpus and associated curated datasets that cowl net textual content, math, code, multilingual information, and scientific literature.
Coaching proceeds in three phases. Pretraining runs at context size 8192 tokens on pure information to determine sturdy common data. Mid coaching then extends context as much as 512k tokens utilizing TxT360 Midas, which mixes lengthy paperwork, artificial considering traces, and numerous reasoning behaviors whereas fastidiously conserving at the least 30 % brief context information in each stage. Lastly, supervised high-quality tuning, known as TxT360 3efforts, injects instruction following and structured reasoning alerts.
The essential level is that K2 V2 just isn’t a generic base mannequin. It’s explicitly optimized for lengthy context consistency and publicity to reasoning behaviors throughout mid coaching. That makes it a pure basis for a put up coaching stage that focuses solely on reasoning high quality, which is precisely what K2 Suppose V2 does.
Absolutely sovereign RLVR on GURU dataset
K2 Suppose V2 is skilled with a GRPO type RLVR recipe on prime of K2 V2 Instruct. The group makes use of the Guru dataset, model 1.5, which focuses on math, code, and STEM questions. Guru is derived from permissively licensed sources, expanded in STEM protection, and decontaminated towards key analysis benchmarks earlier than use. That is essential for a sovereign declare, as a result of each the bottom mannequin information and the RL information are curated and documented by the identical institute.
The GRPO setup removes the same old KL and entropy auxiliary losses and makes use of uneven clipping of the coverage ratio with the excessive clip set to 0.28. Coaching runs totally on coverage with temperature 1.2 to extend rollout variety, international batch measurement 256, and no micro batching. This avoids off coverage corrections which are identified to introduce instability in GRPO like coaching.
RLVR itself runs in two levels. Within the first stage, response size is capped at 32k tokens and the mannequin trains for about 200 steps. Within the second stage, the utmost response size is elevated to 64k tokens and coaching continues for about 50 steps with the identical hyperparameters. This schedule particularly exploits the lengthy context functionality inherited from K2 V2 in order that the mannequin can apply full chain of thought trajectories quite than brief options.
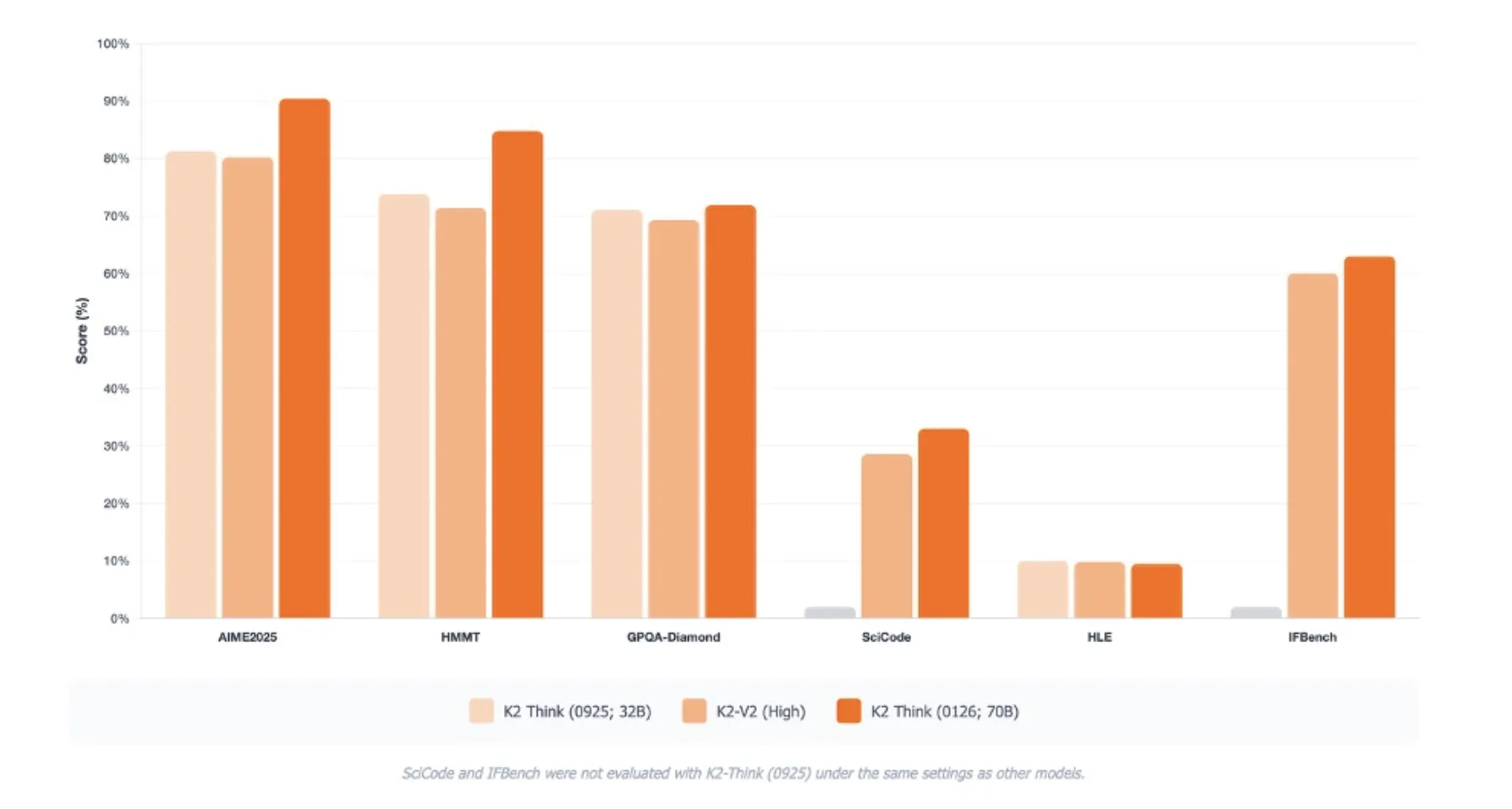
Benchmark profile
K2 Suppose V2 targets reasoning benchmarks quite than purely data benchmarks. On AIME 2025 it reaches go at 1 of 90.42. On HMMT 2025 it scores 84.79. On GPQA Diamond, a troublesome graduate degree science benchmark, it reaches 72.98. On SciCode it data 33.00, and on Humanity’s Final Examination it reaches 9.5 beneath the benchmark settings.
These scores are reported as averages over 16 runs and are instantly comparable solely throughout the similar analysis protocol. The MBZUAI group additionally highlights enhancements on IFBench and on the Synthetic Evaluation analysis suite, with explicit features in hallucination charge and lengthy context reasoning in contrast with the earlier K2 Suppose launch.
Security and openness
The analysis group experiences a Security 4 type evaluation that aggregates 4 security surfaces. Content material and public security, truthfulness and reliability, and societal alignment all attain macro common threat ranges within the low vary. Information and infrastructure dangers stay increased and are marked as crucial, which displays issues about delicate private data dealing with quite than mannequin habits alone. The group states that K2 Suppose V2 nonetheless shares the generic limitations of enormous language fashions regardless of these mitigations. On Synthetic Evaluation’s Openness Index, K2 Suppose V2 sits on the frontier along with K2 V2 and Olmo-3.
Key Takeaways
- K2 Suppose V2 is a completely sovereign 70B reasoning mannequin: Constructed on K2 V2 Instruct, with open weights, open information recipes, detailed coaching logs, and full RL pipeline launched through Reasoning360.
- Base mannequin is optimized for lengthy context and reasoning earlier than RL: K2 V2 is a dense decoder transformer skilled on round 12T tokens, with mid coaching extending context size to 512K tokens and supervised ‘3 efforts’ SFT concentrating on structured reasoning.
- Reasoning is aligned utilizing GRPO based mostly RLVR on the Guru dataset: Coaching makes use of a 2 stage on coverage GRPO setup on Guru v1.5, with uneven clipping, temperature 1.2, and response caps at 32K then 64K tokens to be taught lengthy chain of thought options.
- Aggressive outcomes on onerous reasoning benchmarks: K2 Suppose V2 experiences robust go at 1 scores equivalent to 90.42 on AIME 2025, 84.79 on HMMT 2025, and 72.98 on GPQA Diamond, positioning it as a excessive precision open reasoning mannequin for math, code, and science.
Take a look at the Paper, Mannequin Weight, Repo and Technical particulars. Additionally, be at liberty to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you possibly can be part of us on telegram as properly.
Max is an AI analyst at MarkTechPost, based mostly in Silicon Valley, who actively shapes the way forward for expertise. He teaches robotics at Brainvyne, combats spam with ComplyEmail, and leverages AI every day to translate advanced tech developments into clear, comprehensible insights

