

Picture created by the creator utilizing DALL-E 3
“Computer systems are like bicycles for our minds,” Steve Jobs as soon as remarked. Let’s take into consideration pedaling by the scenic panorama of Internet Scraping with ChatGPT as your information.
Together with its different wonderful makes use of, ChatGPT may be your information and companion in studying something, together with Internet Scraping. And bear in mind, we’re not simply speaking about studying Internet Scraping; we’re speaking about rethinking how we be taught it.
Buckle up for sections that sew curiosity with code and explanations. Let’s get began.
Right here, we want a fantastic plan. Internet Scraping can serve you in doing novel Information Science tasks that can entice employers and will provide help to discovering your dream job. Or you’ll be able to even promote the info you scrape. However earlier than all of this, you must make a plan. Let’s discover what I’m speaking about.
First Factor First : Let’s Make a Plan
Albert Einstein as soon as stated, ‘If I had an hour to resolve an issue, I might spend 55 minutes interested by the issue and 5 minutes interested by options.’ On this instance, we are going to observe his logic.
To be taught Internet Scraping, first, you must outline which coding library to make use of it. As an illustration, if you wish to be taught Python for Information Science, you must break it down into subsections, corresponding to:
- Internet Scraping
- Information Exploration and Evaluation
- Information Visualization
- Machine Studying
Like this, we will divide Internet Scraping into subsections earlier than doing our choice. We nonetheless have many minutes to spend. Listed below are the Internet Scraping libraries;
- Requests
- Scrapy
- BeautifulSoup
- Selenium
Nice, as an instance you’ve got chosen BeautifulSoup. I’d advise you to organize a superb content material desk. You possibly can select this content material desk from a e-book you discovered on the net. As an instance your content material desk’s first two sections will likely be like this:
Title: Mastering Internet Scraping with BeautifulSoup
Contents
Part 1: Foundations of Internet Scraping
- Introduction to Internet Scraping
- Getting Began with Python and BeautifulSoup
- Understanding HTML and the DOM Construction
Part 2: Setting Up and Primary Methods
- Setting Up Your Internet Scraping Setting
- Primary Methods in BeautifulSoup
Additionally, please do not analysis the E-Ebook talked about above as I created it only for this instance.
Now, you will have your content material desk. It is time to observe your every day studying schedule. As an instance at this time you wish to be taught Part 1. Right here is the immediate you should utilize:
Act as a Python trainer and clarify the next subsections to me, utilizing coding examples. Maintain the tone conversational and appropriate for a ninth grade degree, and assume I'm a whole newbie. After every subsection, ask if I've understood the ideas and if I've any questions
Part 1: Foundations of Internet Scraping
- Introduction to Internet Scraping
- Getting Began with Python and BeautifulSoup
- Understanding HTML and the DOM Construction”
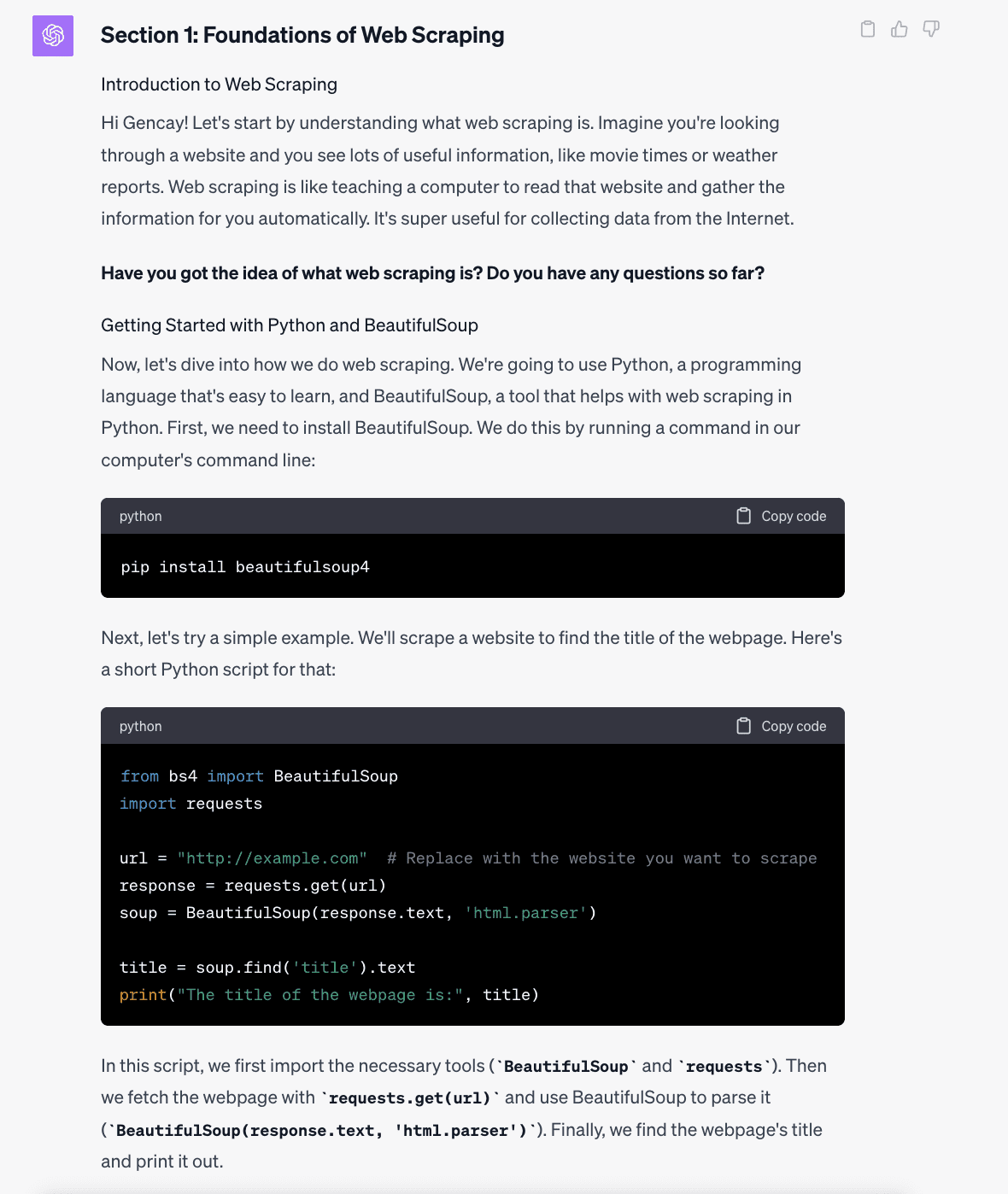
Right here is the primary part of the ChatGPT output. It explains ideas as if to a newbie, supplies coding examples, and asks inquiries to examine your understanding, which is cool. Let’s have a look at the remaining a part of its reply.
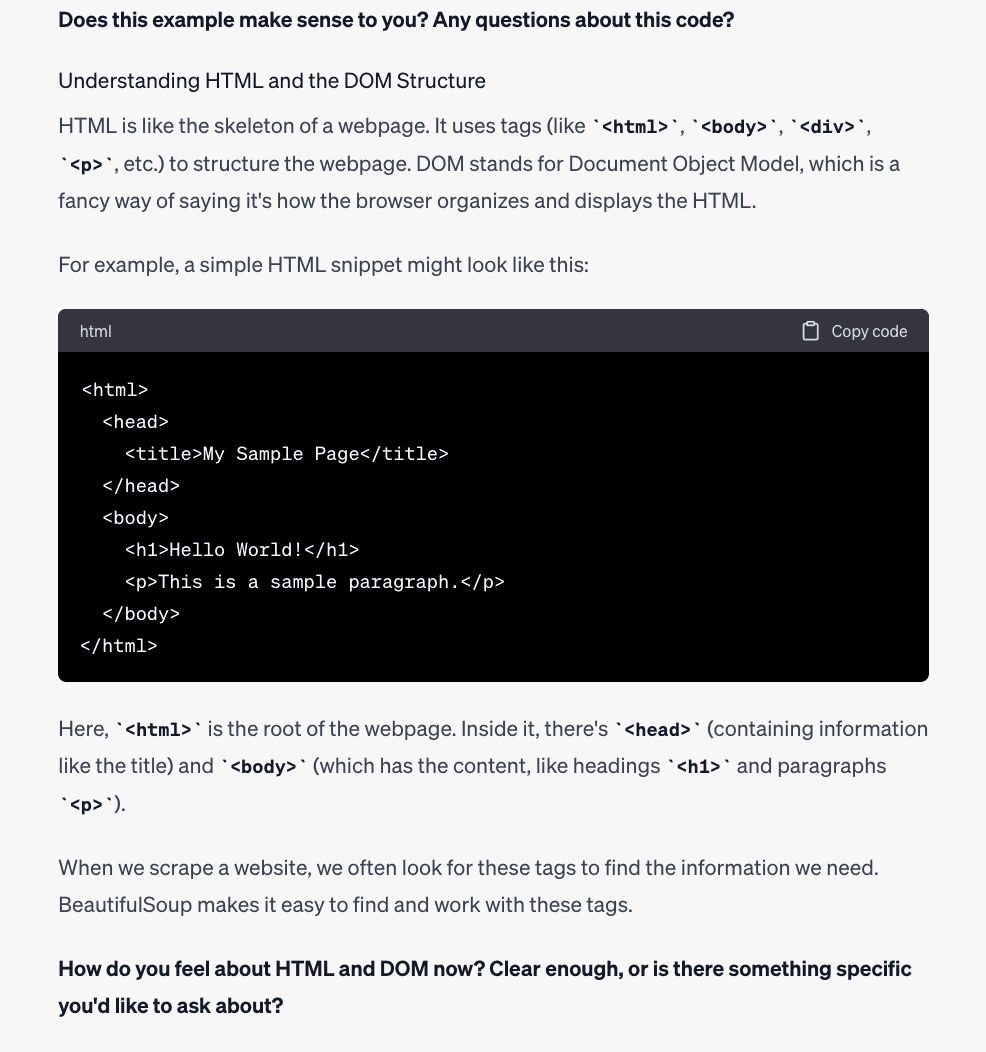
Nice, now you perceive it a bit higher. As you’ll be able to see from this instance, it has already supplied worthwhile details about Internet Scraping. However let’s discover the way it can help you with extra superior functions.
Vital Word: Be conscious of potential inaccuracies in ChatGPT’s responses. At all times confirm the data it supplies afterward.
As you’ll be able to see from the earlier examples, after getting a stable plan, ChatGPT may be fairly useful in studying ideas, like Internet Scraping. On this part, we are going to discover additional functions of ChatGPT, corresponding to debugging or enhancing your code.
Debug Your Code
Typically, debugging may be actually tough and time-consuming, and should you did not write the code accurately, you may spend plenty of time on it, as proven within the code under.
Within the code under, we goal to scrape quotes from the web site, that oftenly used, whereas studying Internet Scraping with Python, let’s see.
import requests
from bs4 import BeautifulSoup
def scrape_quotes():
web page = 1
whereas True:
# This URL is not going to change with web page quantity, inflicting the bug.
url = "https://quotes.toscrape.com/web page/1/"
response = requests.get(url)
if response.okay:
soup = BeautifulSoup(response.textual content, 'html.parser')
quotes = soup.find_all('span', class_='textual content')
if quotes:
for quote in quotes:
print(quote.textual content)
else:
# This situation won't ever be true since 'quotes' is not going to be empty.
print("No extra quotes to scrape.")
break
# The web page variable is incremented, however not used within the URL.
web page += 1
else:
print(f"Did not retrieve the webpage, standing code: {response.status_code}")
break
scrape_quotes()
Are you able to detect the error within the code? If not, that is okay; I assume other than expertes, there are only a few individuals who can try this.
The error was a traditional case of a loop that by no means reaches its finish situation, so watch out earlier than operating or make able to cease it manually.
This error meant that though our web page variable elevated, our script stored requesting the identical web page, trapping us in an infinite loop.
Right here, all you might want to do is utilizing following immediate to debug your code.
And voila, it is going to debug your code chunk immediately and supply you the most recent model.
import requests
from bs4 import BeautifulSoup
def scrape_quotes():
web page = 1
whereas True:
url = f"https://quotes.toscrape.com/web page/{web page}/" # Now the URL updates with the web page quantity.
response = requests.get(url)
if response.okay:
soup = BeautifulSoup(response.textual content, 'html.parser')
quotes = soup.find_all('span', class_='textual content')
if quotes:
for quote in quotes:
print(quote.textual content)
else:
print("No extra quotes to scrape.")
break
web page += 1 # Increment the web page quantity.
else:
print(f"Did not retrieve the webpage, standing code: {response.status_code}")
break
scrape_quotes()
The output will comprise the all quotes from the web site.
Enhance Your Code
Let’s say you’ll scrape quotes from the web site above.
Right here is the code.
import requests
from bs4 import BeautifulSoup
import time
def scrape_quotes_longer():
web page = 1
all_quotes = []
whereas True:
attempt:
response = requests.get(f"https://quotes.toscrape.com/web page/{web page}/", timeout=5)
if not response.okay:
break
soup = BeautifulSoup(response.textual content, 'html.parser')
quotes = soup.find_all('span', class_='textual content')
for quote in quotes:
all_quotes.append(quote.textual content)
# Naive examine for the 'subsequent' button
next_btn = soup.select_one('li.subsequent > a')
if not next_btn:
break
web page += 1
time.sleep(2) # Sleep for two seconds between requests
besides requests.RequestException as e:
print(f"Request failed: {e}")
break
return all_quotes
quotes = scrape_quotes_longer()
for q in quotes:
print(q)
The output would be the identical we had earlier than, all quotes will likely be there, however let’s say, you aren’t happy with the code and also you wish to enhance your code.
You need to use following immediate, it’s easy however highly effective.
Now let’s see the brand new code that ChatGPT provides.
import requests
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
from time import sleep
def scrape_quotes_improved():
web page = 1
all_quotes = []
headers = {'Consumer-Agent': 'Mozilla/5.0'}
whereas True:
url = f"https://quotes.toscrape.com/web page/{web page}/"
attempt:
response = requests.get(url, headers=headers, timeout=5)
response.raise_for_status() # Will elevate an HTTPError if the HTTP request returned an unsuccessful standing code
soup = BeautifulSoup(response.textual content, 'html.parser')
quotes = [quote.text for quote in soup.find_all('span', class_='text')]
if not quotes:
break
all_quotes.prolong(quotes)
next_btn = soup.select_one('li.subsequent > a')
if not next_btn:
break # No extra pages
web page += 1
sleep(1) # Extra cheap delay
besides RequestException as e:
print(f"Request failed: {e}")
break
return all_quotes
quotes = scrape_quotes_improved()
for q in quotes:
print(q)
The output would be the identical, however right here is the enhancements that ChatGPT made.
As you’ll be able to see it’s actually highly effective.

Picture created by the creator utilizing DALL-E 3
Right here, you’ll be able to attempt to automate the entire net scraping course of, by downloading HTML file from the webpage you wish to scrape, and ship the HTML doc to the ChatGPT Superior Information Evaluation, by including file to it.
Let’s see from the instance. Right here is the IMDB web site, that incorporates high 100 score motion pictures, in keeping with IMDB consumer rankings, however on the finish of this webpage, don’t neglect to click on 50 extra, to permit this net web page, that can present all 100 collectively.
After that, let’s obtain the html file by proper clicking on the net web page after which click on on save as, and choose html file. Now you bought the file, open ChatGPT and choose the superior knowledge evaluation.
Now it’s time to add the file you downloaded HTML file at first. After including file, use the immediate under.
Save the highest 100 IMDb motion pictures, together with the film title, IMDb score, Then, show the primary 5 rows. Moreover, save this dataframe as a CSV file and ship it to me.
However right here, if the net pages construction is a bit difficult, ChatGPT won’t perceive the construction of your web site totally. Right here I counsel you to make use of new characteristic of it, sending footage. You possibly can ship the screenshot of the net web page you wish to gather info.
To make use of this characteristic, click on proper on the net web page and click on examine, right here you’ll be able to see the html parts.
Ship this pages screenshot to the ChatGPT and ask extra details about this net pages parts. As soon as you bought these extra info ChatGPT wants, flip again to your earlier dialog and ship these info to the ChatGPT once more. And voila!

We uncover Internet Scraping by ChatGPT. Planning, debugging, and refining code alongside AI proved not simply productive however illuminating. It is a dialogue with expertise main us to new insights.
As you already know, Information Science like Internet Scraping calls for observe. It is like crafting. Code, appropriate, and code once more—that is the mantra for budding knowledge scientists aiming to make their mark.
Prepared for hands-on expertise? StrataScratch platform is your enviornment. Go into knowledge tasks and crackinterview questions, and be a part of a group which is able to provide help to develop. See you there!
Nate Rosidi is an information scientist and in product technique. He is additionally an adjunct professor educating analytics, and is the founding father of StrataScratch, a platform serving to knowledge scientists put together for his or her interviews with actual interview questions from high firms. Join with him on Twitter: StrataScratch or LinkedIn.

