

Whether or not predicting the following phrase inside a sentence or figuring out traits in monetary markets, the capability to interpret and analyze sequential information is significant in as we speak’s AI world.
The normal neural networks typically fail at studying long-term patterns. Enter LSTM (Lengthy Quick-Time period Reminiscence), a particular recurrent neural community that modified how machines function with time-dependent information.
On this article, we’ll discover in depth how LSTM works, its structure, the decoding algorithm used, and the way it’s serving to clear up real-world issues throughout industries.
Understanding LSTM
Lengthy Quick-Time period Reminiscence (LSTM) is a sort of Recurrent Neural Community (RNN) that addresses the shortcomings of normal RNNs by way of their capability to trace long-term dependencies, which is a results of their vanishing or exploding gradients.
Invented by Sepp Hochreiter and Jürgen Schmidhuber, the LSTM offered an structure breakthrough utilizing reminiscence cells and gate mechanisms (enter, output, and overlook gates), permitting the mannequin to retain or overlook data throughout time, 1997, selectively.
This invention was particularly efficient for sequential functions akin to speech recognition, language modeling, and time sequence forecasting, the place understanding the context all through time is a major issue.
LSTM Structure: Elements and Design
Overview of LSTM as an Superior RNN with Added Complexity
Though conventional Recurrent Neural Networks (RNNs) can course of serial information, they can not deal with long-term dependencies due to their associated gradient drawback.
LSTM (Lengthy Quick-Time period Reminiscence) networks are an extension of RNNs, with a extra advanced structure to assist the community be taught what to recollect, what to overlook, and what to output over extra prolonged sequences.
This degree of complexity makes LSTM superior in deep context-dependent duties.
Core Elements
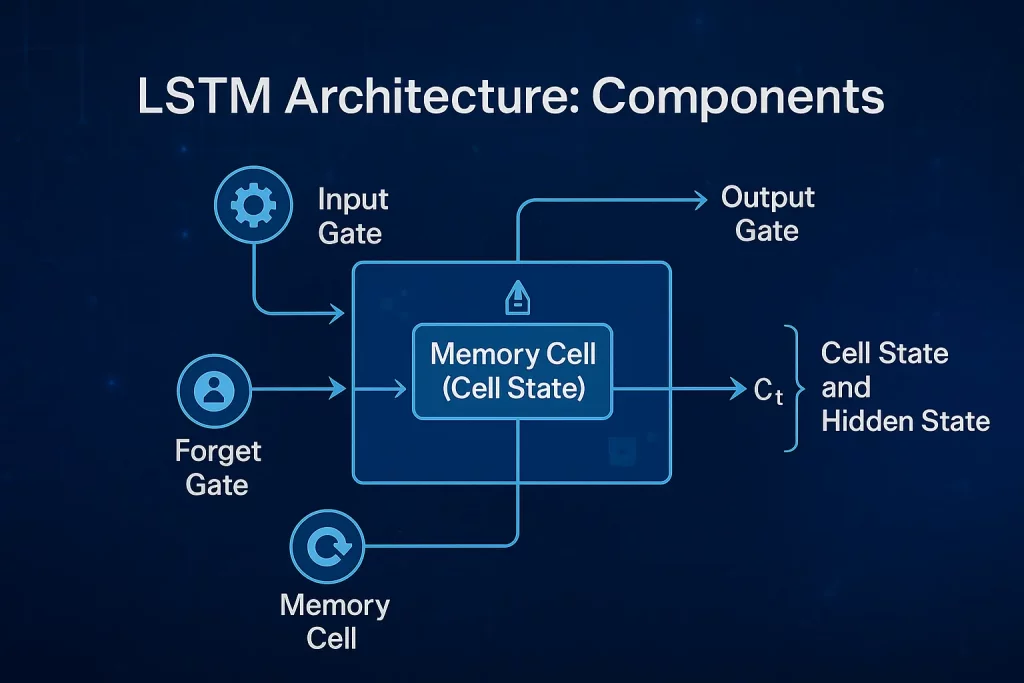
- Reminiscence Cell (Cell State):
The reminiscence cell is the epicenter of the LSTM unit. A conveyor belt transports data throughout time steps with minimal alterations. The reminiscence cell permits LSTM to retailer data for lengthy intervals, making it possible to seize long-term dependencies.
- Enter Gate:
The enter gate controls the entry into the reminiscence cell of latest data. It applies a sigmoid activation perform to find out which values shall be up to date and a tanh perform to generate a candidate vector. This gate makes it potential to retailer solely related new data.
- Overlook Gate:
This gate determines what ought to be thrown out of the reminiscence cell. It offers values between 0 and 1; 0: “fully overlook”, 1: “fully preserve”. This selective forgetting is important in avoiding reminiscence overload.
- Output Gate:
The output gate decides what piece within the reminiscence cell goes to the following hidden state (and possibly whilst output). It helps the community in figuring out which data from the present cell state would affect the following step alongside the sequence.
Cell State and Hidden State:
- Cell State (C<sub>t</sub>): It carries long-term reminiscence modified by enter and overlook gates.
- Hidden State (h<sub>t</sub>): Represents the output worth of the LSTM unit in a specific time step, which relies upon upon each the cell state and the output gate. It’s transferred to the following LSTM unit and tends for use within the last prediction.
How do These Elements Work Collectively?
The LSTM unit performs the sequence of operations in each time step:
- Overlook: The overlook gate makes use of the earlier hidden state and present enter to find out data to overlook from the cell state.
- Enter: The enter gate and the candidate values decide what new data must be added to the cell state.
- Replace: The cell state is up to date when previous retention data is merged with the chosen new enter.
- Output: The output gate will use the up to date cell state to supply the following hidden state that can management the following step, and is likely to be the output itself.
This advanced gating system permits LSTMs to maintain a well-balanced reminiscence, which may retain essential patterns and overlook pointless noise that conventional RNNs discover tough.
LSTM Algorithm: How It Works

- Enter at Time Step :
At every time step ttt, the LSTM receives two items of data:- xtx_txt: The present enter to the LSTM unit (e.g., the following phrase in a sentence, or the following time worth in a sequence
- ht−1h_{t-1}ht−1: The earlier hidden state carries the prior time step data.
- Ct−1C_{t-1}Ct−1: The earlier cell state carries long-term reminiscence from prior time steps.
- Overlook Gate (ftf_tft):
The overlook gate decides what data from the earlier cell state ought to be discarded. It appears on the present enter xtx_txt and the final hidden state ht−1h_{t-1}ht−1 and applies a sigmoid perform to generate values between 0 and 1. 0 means “overlook fully,” and 1 means “preserve all data.”- Formulation:

The place σsigmaσ is the sigmoid perform, WfW_fWf is the burden matrix, and bfb_fbf is the bias time period.
- Formulation:
- Enter Gate (iti_tit):
The enter gate determines what new data ought to be added to the cell state. It has two elements:- The sigmoid layer decides which values shall be up to date (output between 0 and 1).
- The tanh layer generates candidate values for brand spanking new data.
- Formulation:

The place C~ttilde{C}_tC~t is the candidate cell state, and WiW_iWi, WCW_CWC are weight matrices for the enter gate and cell candidate, respectively.
- Cell State Replace (CtC_tCt):
The cell state is up to date by combining the earlier Ct−1C_{t-1}Ct−1 (modified by the overlook gate) and the brand new data generated by the enter gate. The overlook gate’s output controls how a lot of the earlier cell state is saved, whereas the enter gate’s output controls how a lot new data is added.- Formulation:

- ftf_tft controls how a lot of the earlier reminiscence is saved,
- iti_tit decides how a lot of the brand new reminiscence is added.
- Formulation:
- Output Gate (oto_tot):
The output gate determines which data from the cell state ought to be output because the hidden state for the present time step.


The present enter xtx_txt and the earlier hidden state ht−1h_{t-1}ht−1 are handed via a sigmoid perform to resolve which elements of the cell state will affect the key state. The tanh perform is then utilized to the cell state to scale the output.
- Formulation:

WoW_oWo is the burden matrix for the output gate, bob_obo is the bias time period, and hth_tht is the hidden state output at time step ttt.

Mathematical Equations for Gates and State Updates in LSTM
- Overlook Gate (ftf_tft):
The overlook gate decides which data from the earlier cell state ought to be discarded. It outputs a worth between 0 and 1 for every quantity within the cell state, the place 0 means “fully overlook” and 1 means “preserve all data.”
Formulation-

- σsigmaσ: Sigmoid activation perform
- WfW_fWf: Weight matrix for overlook gate
- bfb_fbf: Bias time period
- Enter Gate (iti_tit):
The enter gate controls what new data is saved within the cell state. It decides which values to replace and applies a tanh perform to generate a candidate for the newest reminiscence.Formulation-

- C~ttilde{C}_tC~t: Candidate cell state (new potential reminiscence)
- tanhtanhtanh: Hyperbolic tangent activation perform
- Wi, WCW_i, W_CWi, WC: Weight matrices for enter gate and candidate cell state
- bi,bCb_i, b_Cbi,bC: Bias phrases
- Cell State Replace (CtC_tCt):
The cell state is up to date by combining the data from the earlier cell state and the newly chosen values. The overlook gate decides how a lot of the final state is saved, and the enter gate controls how a lot new data is added.
Formulation-

- Ct−1C_{t-1}Ct−1: Earlier cell state
- ftf_tft: Overlook gate output (decides retention from the previous)
- iti_tit: Enter gate output (decides new data)
- Output Gate (oto_tot):
The output gate determines what a part of the cell state ought to be output on the present time step. It regulates the hidden state (hth_tht) and what data flows ahead to the following LSTM unit.
Formulation- ![]()
- Hidden State (hth_tht):
The hidden state is the LSTM cell output, which is commonly used for the following time step and infrequently as the ultimate prediction output. The output gate and the present cell state decide it.
Formulation- ![]()
- hth_tht: Hidden state output at time step ttt
- oto_tot: Output gate’s choice
Comparability: LSTM vs Vanilla RNN Cell Operations
| Characteristic | Vanilla RNN | LSTM |
| Reminiscence Mechanism | Single hidden state vector hth_tht | Twin reminiscence: Cell state CtC_tCt + Hidden state hth_tht |
| Gate Mechanism | No express gates to regulate data move | A number of gates (overlook, enter, output) to regulate reminiscence and data move |
| Dealing with Lengthy-Time period Dependencies | Struggles with vanishing gradients over lengthy sequences | Can successfully seize long-term dependencies as a consequence of reminiscence cells and gating mechanisms |
| Vanishing Gradient Downside | Vital, particularly in lengthy sequences | Mitigated by cell state and gates, making LSTMs extra steady in coaching |
| Replace Course of | The hidden state is up to date instantly with a easy system | The cell state and hidden state are up to date via advanced gate interactions, making studying extra selective and managed |
| Reminiscence Administration | No particular reminiscence retention course of | Specific reminiscence management: overlook gate to discard, enter gate to retailer new information |
| Output Calculation | Direct output from hth_tht | Output from the oto_tot gate controls how a lot the reminiscence state influences the output. |
Coaching LSTM Networks
1. Information Preparation for Sequential Duties
Correct information preprocessing is essential for LSTM efficiency:
- Sequence Padding: Guarantee all enter sequences have the identical size by padding shorter sequences with zeros.
- Normalization: Scale numerical options to a normal vary (e.g., 0 to 1) to enhance convergence velocity and stability.
- Time Windowing: For time sequence forecasting, create sliding home windows of input-output pairs to coach the mannequin on temporal patterns.
- Practice-Check Cut up: Divide the dataset into coaching, validation, and take a look at units, sustaining the temporal order to forestall information leakage.
2. Mannequin Configuration: Layers, Hyperparameters, and Initialization
- Layer Design: Start with an LSTM layer [1] and end with a Dense output layer. For advanced duties, layer stacking LSTM layers might be thought of.
- Hyperparameters:
- Studying Fee: Begin with a worth from 1e-4 to 1e-2.
- Batch Measurement: Widespread decisions are 32, 64, or 128.
- Variety of Models: Often between 50 and 200 items per LSTM layer.
- Dropout Fee: Dropout (e.g., 0.2 to 0.5) can clear up overfitting.
- Weight Initialization: Use Glorot or He initialization of weights to initialize the preliminary weights to maneuver quicker in the direction of convergence and scale back vanishing/exploding gradient dangers.
3. Coaching Course of
Realizing the fundamental parts of LSTM coaching
- Backpropagation By Time (BPTT)- This algorithm calculates gradients by unrolling the LSTM over time to permit the mannequin to be taught sequential dependencies.
- Gradient Clipping: Clip backpropagator- gradients throughout backpropagation to a given threshold (5.0) to keep away from exploding gradients. This helps within the stabilization of coaching, particularly in deep networks.
- Optimization Algorithms- Optimizer might be chosen to be of Adam or RMSprop sort, which regulate their studying charges and are appropriate for coaching LSTM.
Functions of LSTM in Deep Studying

1. Time Collection Forecasting
Software: LSTM networks are frequent in time sequence forecasting, for ex. Forecasting of inventory costs, climate situations, or gross sales information.
Why LSTM?
LSTMs are extremely efficient in capturing such long-term dependencies and traits in sequential information, making LSTMs glorious in forecasting future values primarily based on earlier ones.
2. Pure Language Processing (NLP)
Software: LSTMs are properly utilized in such NLP issues as machine translation, sentiment evaluation, and language modelling.
Why LSTM?
LSTM’s confluence in remembering contextual data over lengthy sequences permits it to know the which means of phrases or sentences by referring to surrounding phrases, thereby enhancing language understanding and technology.
3. Speech Recognition
Software: LSTMs are integral to speech-to-text, which converts spoken phrases to textual content.
Why LSTM?
Speech has temporal dependency, with phrases spoken at earlier phases affecting these spoken later. LSTMs are extremely correct in sequential processes, efficiently capturing the dependency.
4. Anomaly Detection in Sequential Information
Software: LSTMs can detect anomalies in information streams, akin to fraud detection when monetary transactions are concerned or malfunctioning sensors in IoT networks.
Why LSTM?
With the discovered Regular Patterns of Sequential information, the LSTMs can simply establish new information factors that don’t comply with the discovered patterns, which level to potential Anomalies.
5. Video Processing and Motion Recognition
Software: LSTMs are utilized in video evaluation duties akin to figuring out human actions (e.g, strolling, working, leaping) primarily based on a sequence of frames in a video (motion recognition).
Why LSTM?
Movies are frames with temporal dependencies. LSTMs can course of these sequences and are educated to be taught over time, making them helpful for video classification duties.
Conclusion
LSTM networks are essential for fixing intricate issues in sequential information coming from completely different domains, together with however not restricted to pure language processing and time sequence forecasting.
To take your proficiency a notch increased and preserve forward of the quickly rising AI world, discover the Put up Graduate Program in Synthetic Intelligence and Machine Studying being offered by Nice Studying.
This built-in course, which was developed in partnership with the McCombs College of Enterprise at The College of Texas at Austin, entails in-depth data on matters akin to NLP, Generative AI, and Deep Studying.
With hands-on tasks, stay mentorship from business specialists, and twin certification, it’s supposed to arrange you with the talents essential to do properly in AI and ML jobs.

