

This tutorial is predicated on this video, which is a step-by-step information on utilizing a big language mannequin to construct a textual content classification mannequin.
Textual content classification is a standard activity in Pure Language Processing that assigns a set of predefined classes to open-ended textual content and on this demonstration, we’ll use Cohere AI’s embedding mannequin to seize semantic relationships and classify several types of check questions from the Scholar Questions dataset. Whereas the dataset incorporates round 120,000 questions, we’ll work with a smaller subset of 5,000 questions for simplicity.
- This is the place you may obtain the Python utility used.
- This is the hyperlink to the dataset on Kaggle.
- This is the hyperlink to the shortened 5000 pattern dataset used.
- This is the hyperlink to the shortened 5000 pattern dataset used AFTER being processed by the utility in order that it’s now in Clarifai format.
Dataset Overview:
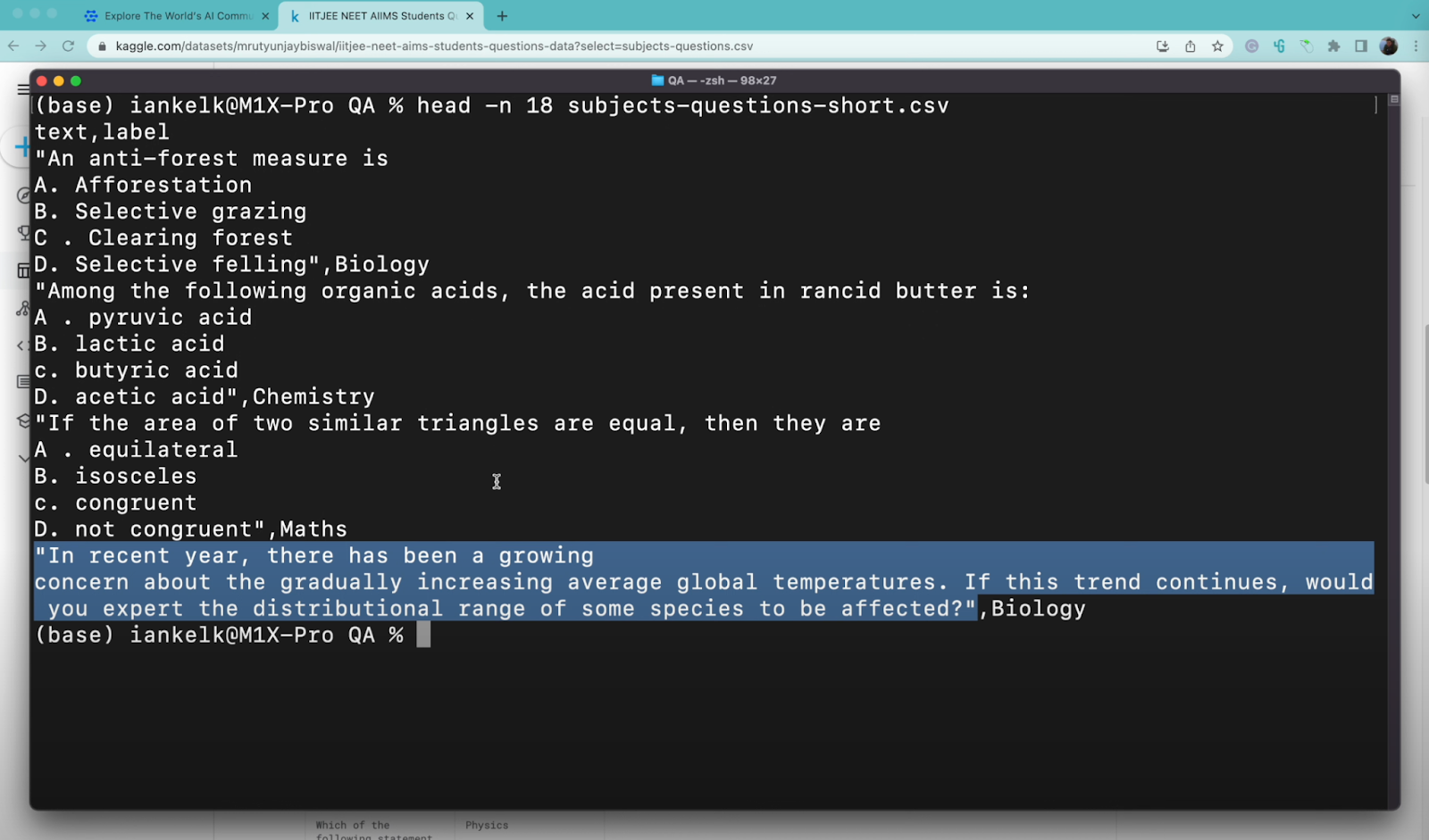
Let’s begin by looking on the dataset we’re working with. We’ll be utilizing the scholar questions dataset which incorporates roughly 120,000 check questions. Nevertheless, to optimize the educational expertise, we’ll slim them right down to about 5,000 check questions.

The dataset is a structured CSV file with two columns: ‘textual content’ and ‘label.’ The ‘textual content’ column incorporates the query textual content, and the ‘label’ column incorporates the class of the query, which could be considered one of 4 topics: physics, chemistry, biology, or math.
Information Preprocessing:
Let’s Begin with a Information Conversion utilizing the Python script to transform and put together our dataset for classification. This script additionally helps us break up the information into coaching and testing units.
First we have to specify if there are columns with a number of values. In our situation, they do not, so our response will likely be a ‘no’.

Subsequent, the script seems for the column with the textual content, which on this case is the primary column. It could actually additionally acknowledge a number of classes within the second column, equivalent to chemistry, math, biology, and physics. Additionally, it determines that there’s just one extra column in addition to the ‘textual content’ column, so it robotically selects ‘labels’ because the column for labels.

The Python software then asks if we need to divide our dataset right into a coaching set and a testing set. We agree with this and select ‘sure.’ We make this selection as a result of we need to see how effectively our mannequin performs on new and unseen information.
Additionally, there is not any must shuffle the information for this specific challenge, we’ll reply with a ‘no’ when requested to take action. Additionally for splitting the dataset we’re dividing the information into coaching and testing units, eliminating the necessity for a validation set.
Now with all these responses, 80% of the dataset is devoted to coaching and relaxation for testing. Now the information is neatly organized into two distinct recordsdata: a coaching set and a testing set.
Coaching the Textual content Classification Mannequin:
First let’s create a brand new utility. Signup to Clarifai right here and create a brand new App by specifying the App ID, Quick Description and choosing the Base Workflow.
Right here we’ve set the bottom workflow as Textual content which is a single-model workflow of textual content embedding mannequin for normal english textual content.

Now we’ve to vary this to Cohere Textual content Workflow. So go the workflow part and duplicate the bottom workflow which is Textual content and rename it as ‘Textual content-Cohere’ and in addition by altering the Textual content Embedder from multilingual-text-embedding to cohere-text-to-embeddings mannequin.

Now save the workflow and go to the App settings to vary the bottom workflow from Textual content to Textual content-Cohere.

Information Add
Now let’s add the Coaching and Take a look at information. Go to the Inputs part within the Sidebar and click on on add to add the coaching and testing information.
It takes some time to add the information since each textual content enter you add will likely be handed by the Cohere embedding mannequin to course of them.

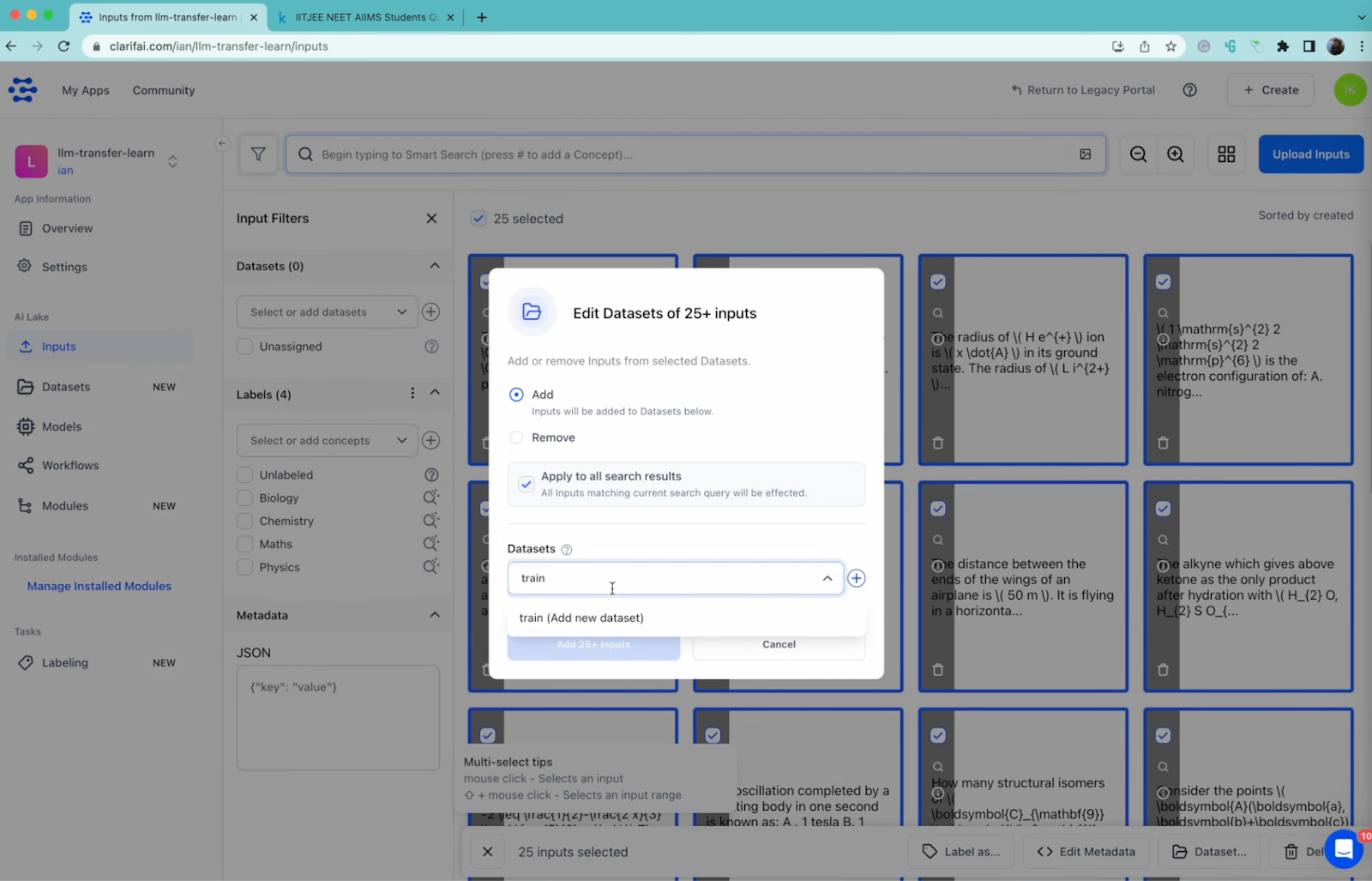
As soon as the information is uploaded, choose all the information and add them to the coaching dataset.

Choose all of the search outcomes, add a brand new dataset prepare after which click on on Add inputs. This may be sure that all of the uploaded information is beneath the dataset named prepare. Comply with the same steps to add the Take a look at Dataset.
Coaching the Classifier utilizing Switch Studying
Now, let’s prepare our textual content classification mannequin. First, go to Fashions Part in your Utility and choose the Create Mannequin choice on the High Proper Nook

Now choose the choice Switch Studying Classifier

Now specify the Mannequin Id, select the ‘prepare’ dataset, and select ALL the ideas within the coaching dataset with labels and hit Prepare.

Evaluating the Mannequin Outcomes:
As soon as the Coaching is finished, we consider the mannequin’s efficiency on each the Coaching and testing datasets. This is the outcomes on the Coaching Dataset.
Because the mannequin is already educated on this dataset it achieves excessive scores for ROC/AUC, Precision, Recall, and F1 Rating.

On the check information, which incorporates the examples it hasn’t seen earlier than, it nonetheless performs effectively, given the restricted subset used for coaching.

And that is how you can use Clarifai’s platform to coach a textual content classification mannequin with Cohere AI’s embedding mannequin on a textual content dataset. We have proven information preprocessing, mannequin creation, coaching, and efficiency analysis. Thanks for studying!

