
Picture by Editor
In recent times, Generative AI analysis has advanced in a manner that has modified how we work. From growing content material, planning our work, and discovering solutions to creating paintings, it’s all potential now with Generative AI. Nevertheless, every mannequin often works for sure use instances, e.g., GPT for text-to-text, Steady Diffusion for text-to-image, and plenty of others.
The mannequin able to performing a number of duties is known as the multimodal mannequin. A lot state-of-the-art analysis is transferring within the multimodal path because it’s confirmed helpful in lots of circumstances. For this reason one of many thrilling analysis concerning multimodal folks have to know is the NExT-GPT.
NExT-GPT is a multimodal mannequin that might remodel something into something. So, how does it work? Let’s discover it additional.
NExT-GPT is an any-to-any multimodal LLM that may deal with 4 completely different sorts of enter and output: textual content, pictures, movies, and audio. The analysis was initiated by the analysis group known as NExT++ of the Nationwide College of Singapore.
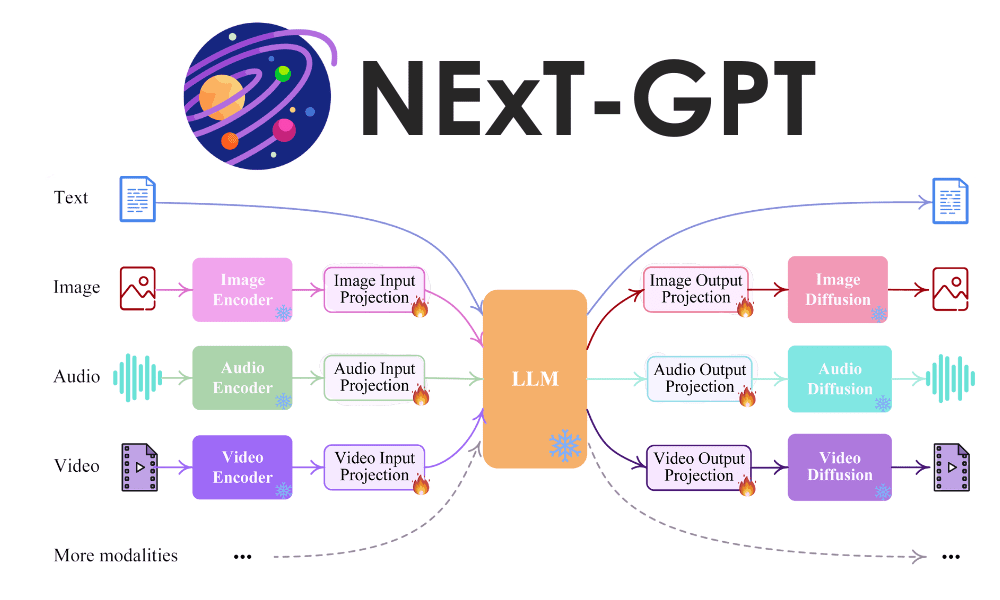
The general illustration of the NExT-GPT mannequin is proven within the picture under.
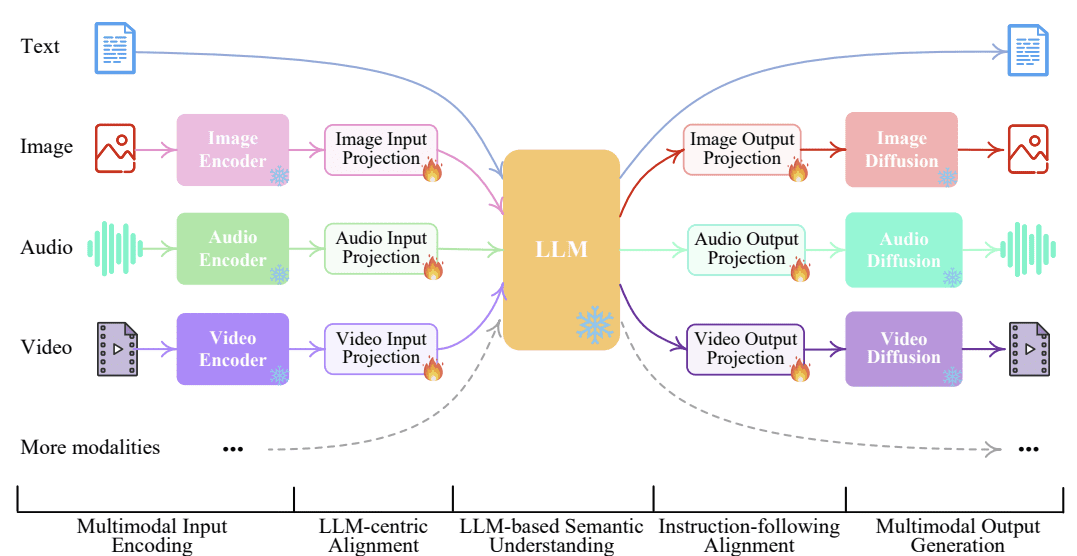
NExT-GPT LLM Mannequin (Wu et al. (2023))
NExT-GPT mannequin consists of three elements of works:
- Set up encoders for enter from varied modalities and signify them right into a language-like enter that LLM might settle for,
- Using the open-source LLM because the core to course of the enter for each semantic understanding and reasoning with further distinctive modality sign,
- Present multimodal sign into completely different encoders and generate the end result to the suitable modalities.
An instance of the NExT-GPT inferences course of may be seen within the picture under.
NExT-GPT inference Course of (Wu et al. (2023))
We are able to see within the picture above that relying on the duties that we would like, the encoder and decoder would swap to the suitable modalities. This course of can solely occur as a result of NExT-GPT makes use of an idea known as modality-switching instruction tuning so the mannequin can conform with the consumer’s intention.
The researchers have tried to experiment with varied combos of modalities. Total, the NExT-GPT efficiency may be summarized within the graph under.
NExT-GPT Total Efficiency Consequence (Wu et al. (2023))
NExT-GPT’s greatest efficiency is the Textual content and Audio enter to provide Pictures, adopted by the Textual content, Audio, and Picture enter to provide Picture outcomes. The least performing motion is the Textual content and Video enter to provide Video output.
An instance of the NExT-GPT functionality is proven within the picture under.
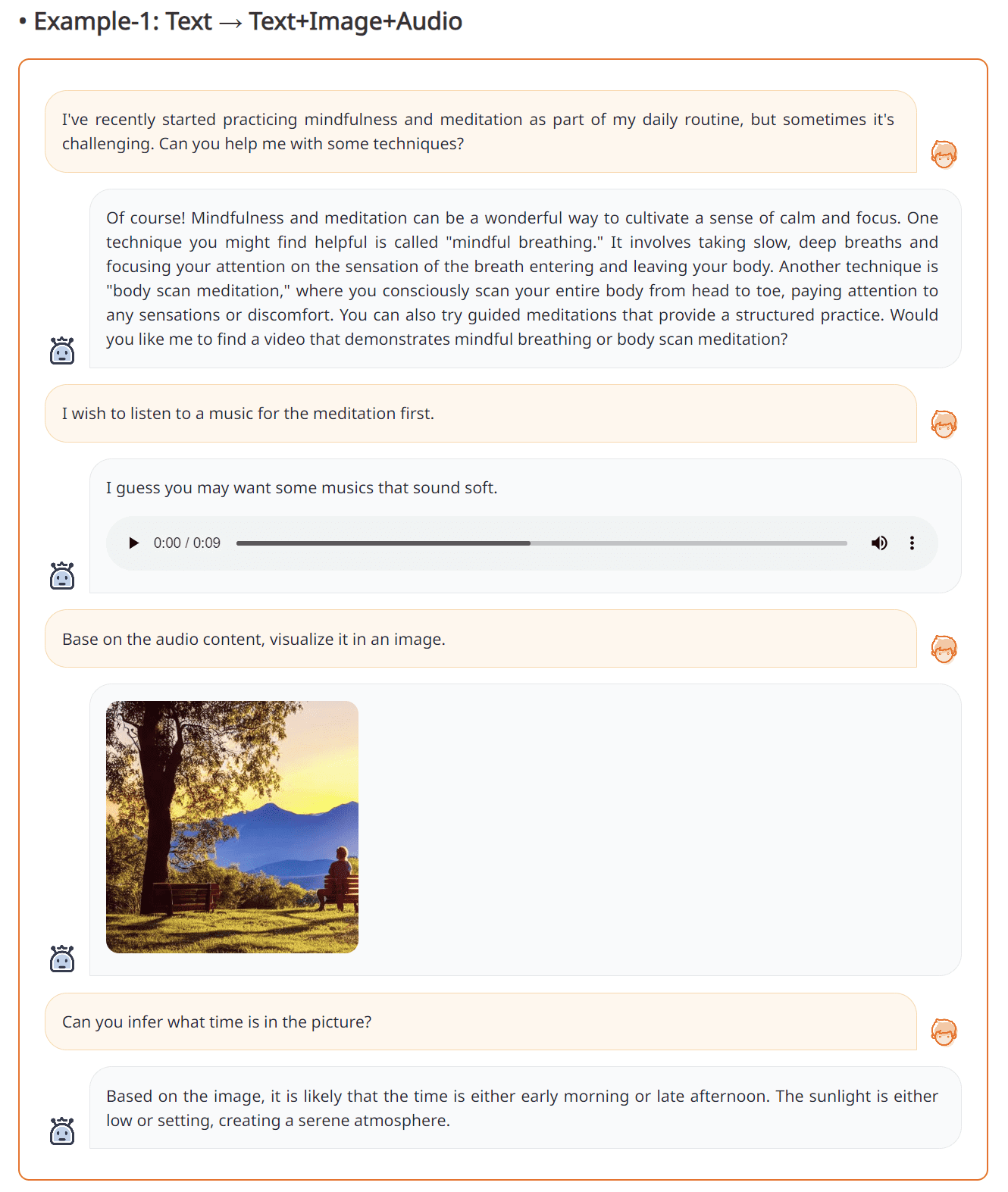
Textual content-to-Textual content+Picture+Audio from NExT-GPT (Supply: NExT-GPT internet)
The end result above exhibits that interacting with the NExT-GPT can produce Audio, Textual content, and Pictures acceptable to the consumer’s intention. It’s proven that NExT-GPT can act fairly properly and is fairly dependable.
One other instance of NExT-GPT is proven within the picture under.
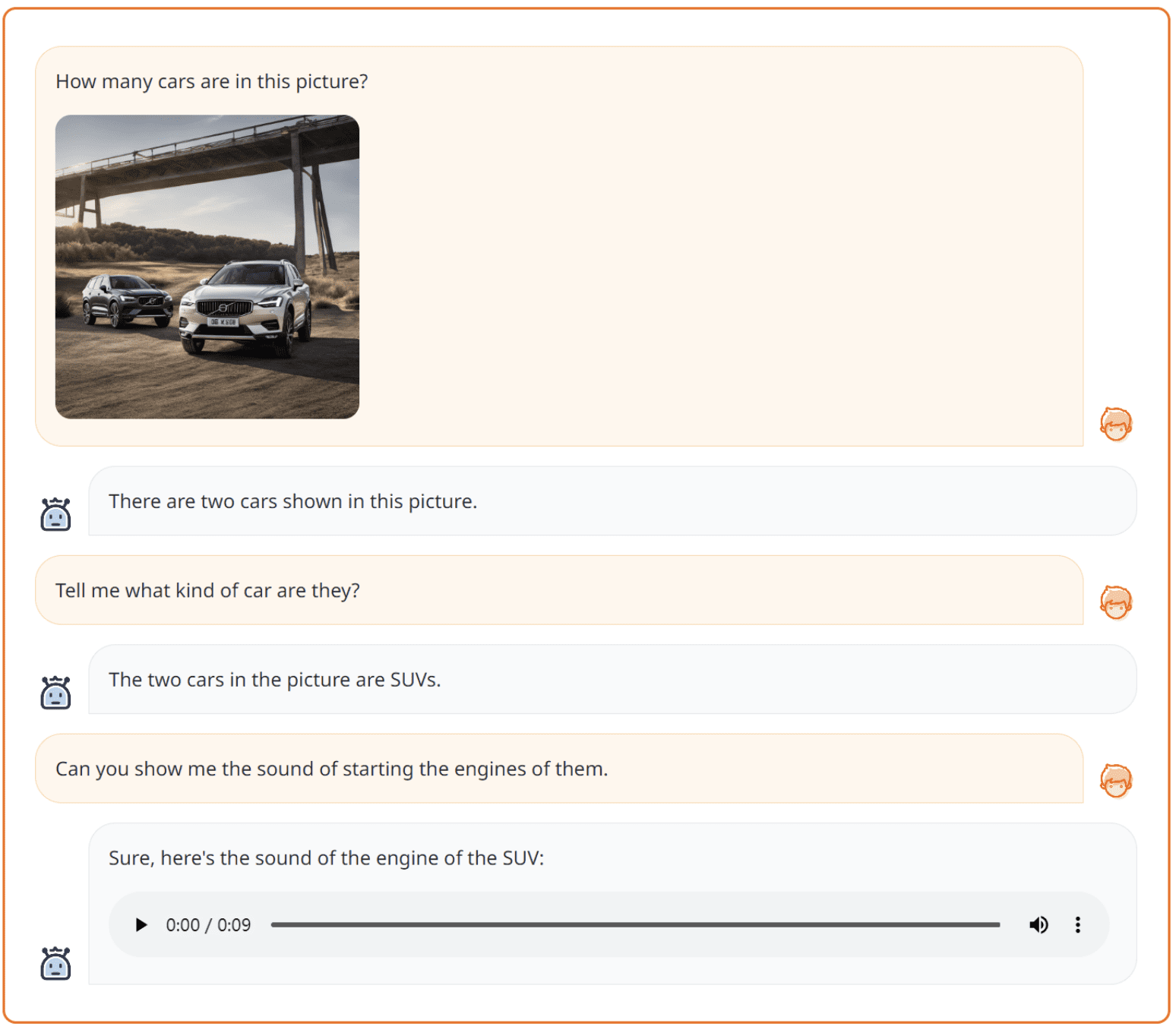
Textual content+Imaget-to-Textual content+Audio from NExT-GPT (Supply: NExT-GPT internet)
The picture above exhibits that NExT-GPT can deal with two sorts of modalities to provide Textual content and Audio output. It’s proven how the mannequin is flexible sufficient.
If you wish to strive the mannequin, you’ll be able to arrange the mannequin and atmosphere from their GitHub web page. Moreover, you’ll be able to check out the demo on the next web page.
NExT-GPT is a multimodal mannequin that accepts enter knowledge and produces output in textual content, picture, audio, and video. This mannequin works by using a particular encoder for the modalities and switching to acceptable modalities in accordance with the consumer’s intention. The efficiency experiment end result exhibits a great end result and promising work that can be utilized in lots of functions.
Cornellius Yudha Wijaya is an information science assistant supervisor and knowledge author. Whereas working full-time at Allianz Indonesia, he likes to share Python and Knowledge suggestions by way of social media and writing media.

