

Picture by Creator
# Introduction
The world of information engineering is stuffed with buzzwords. For a newbie knowledge scientist, listening to phrases like “knowledge lake,” “knowledge warehouse,” “lakehouse,” and “knowledge mesh” in the identical dialog could be complicated. Are they the identical factor? Do they compete with one another? Which one do you really want?
Figuring out these ideas is essential as a result of the construction you select determines the way you retailer, entry, and analyze your knowledge. It impacts every thing from the velocity of your machine studying fashions to the way you depend on your online business reviews.
On this article, I clarify these 4 approaches to knowledge administration in easy phrases. By the top, you’ll perceive the variations, strengths, and weaknesses of every structure and know when to make use of them. On the finish of the article, you’ll have a transparent roadmap to get by means of the trendy knowledge panorama.
# Understanding the Information Warehouse
Let’s begin with the oldest and most established idea: the information warehouse. Think about a clear, organized library. Each guide (piece of information) is in its right place, cataloged, and formatted to be simply learn.
An information warehouse is precisely the clear, organized library for structured knowledge. An information warehouse is a single central location that shops structured, processed knowledge optimized for evaluation and reporting. It follows the “schema-on-write” precept. What this implies is that earlier than knowledge is even loaded into the warehouse, it have to be cleaned, reworked, and structured into a particular format — often tables with rows and columns.
// Key Traits
- It primarily shops structured knowledge from transactional programs, operational databases, and line-of-business purposes.
- It depends closely on extract, remodel, load (ETL). Information is extracted from sources, reworked (cleaned, aggregated), after which loaded into the warehouse.
- As a result of the information is preprocessed and structured, querying is extremely quick and environment friendly. It’s optimized for enterprise intelligence (BI) instruments like Tableau or Energy BI.
- Enterprise analysts can simply question the information utilizing SQL with no need deep technical experience.
// Figuring out the 4 Elements of a Information Warehouse
Each knowledge warehouse consists of 4 important elements, that are:
- Centralized database: The core storage system
- ETL instruments: Extract, remodel, load instruments that course of knowledge
- Metadata: Information in regards to the knowledge (descriptions, context)
- Entry instruments: Interfaces for querying and reporting
# Defining the Load Supervisor in a Information Warehouse
A load supervisor is a part that handles the ETL course of. It extracts knowledge from sources, transforms it in response to enterprise guidelines, and hundreds it into the warehouse. Consider it because the loading dock employees who obtain shipments, test stock, and place objects of their right places.
# Reviewing Frequent Instruments
In style knowledge warehouse options embody Snowflake, Amazon Redshift, Google BigQuery, and Microsoft Azure Synapse. Is Snowflake an information warehouse? Sure, Snowflake is a cloud-based knowledge warehouse that separates storage from compute, permitting unbiased scaling of every.
// Figuring out When to Use a Information Warehouse
Use an information warehouse if you want:
- Quick question efficiency on structured knowledge
- Enterprise intelligence and reporting
- A single supply of fact for enterprise metrics
- Information consistency and excessive knowledge high quality
- Supporting enterprise selections primarily based on historic, dependable knowledge

Conventional knowledge warehouse structure displaying ETL pipeline from sources to central warehouse to BI instruments | Picture by Creator
# Understanding the Information Lake
As knowledge begins to extend in quantity and selection, like social media posts, photos, and web of issues (IoT) sensor knowledge, the inflexible construction of the information warehouse turns into an issue. That is the place it’s essential to use the information lake.
If an information warehouse is a library, an information lake is a reservoir. It follows the “schema-on-read” precept. You retailer knowledge in its uncooked, native format first and solely apply construction when you’re able to learn and analyze it.
// Key Traits
Information lakes use schema-on-read, which means you outline the construction if you learn the information, not if you retailer it. They’ll deal with all knowledge varieties:
- Structured knowledge (tables, CSV information)
- Semi-structured knowledge (JSON, XML, logs)
- Unstructured knowledge (photos, movies, audio information)
// Figuring out Information Lake Workloads
Information lakes primarily assist on-line analytical processing (OLAP) workloads for analytics and massive knowledge processing. Nonetheless, they will additionally ingest knowledge from on-line transaction processing (OLTP) programs by means of change knowledge seize (CDC) processes.
// Clarifying Apache Kafka and Information Lakes
No, Apache Kafka just isn’t an information lake. Kafka is a distributed occasion streaming platform used for real-time knowledge insertion. Nonetheless, Kafka typically feeds knowledge into knowledge lakes, performing because the pipeline that strikes streaming knowledge into storage.
// Reviewing Frequent Instruments
In style knowledge lake options embody Amazon S3, Azure Information Lake Storage (ADLS), Google Cloud Storage, and Hadoop HDFS.
// Figuring out When to Use a Information Lake
Use an information lake if you want:
- Storing huge quantities of IoT sensor knowledge for future machine studying tasks
- Holding person clickstream logs for behavioral evaluation
- Archiving uncooked knowledge for regulatory compliance
- Flexibility to retailer any knowledge kind
- Information science and machine studying use circumstances
- Price-effective storage (knowledge lakes are cheaper than warehouses)

Information lake structure displaying various knowledge sources flowing into uncooked storage with varied shoppers accessing knowledge | Picture by Creator
// Additional Key Traits
- It shops all knowledge varieties, each structured and semi-structured (JSON, XML, logs) and unstructured knowledge (photos, movies, audio).
- It makes use of extract, load, remodel (ELT). Information is extracted and loaded in its uncooked kind first. The transformation occurs later when the information is learn for evaluation.
- It’s constructed on high of low cost, scalable object storage (like Amazon S3 or Azure Blob Storage); it’s cost-effective storage; it’s less expensive to retailer petabytes of information right here than in a warehouse.
- Information scientists love knowledge lakes as a result of they will discover uncooked knowledge, experiment, and construct fashions with out being restricted by predefined schemas.
Nonetheless, this flexibility comes at a price. With out correct administration, an information lake can shortly flip right into a “knowledge swamp,” a chaotic mess of unusable, uncataloged knowledge.
A large reservoir with a number of pipes flowing in (Logs, Photos, Databases, JSON) | Picture by Creator
# Understanding the Lakehouse
Now you will have the low-cost, versatile knowledge lake and the high-performance, dependable knowledge warehouse. For years, organizations had to decide on one or keep two separate programs (a pricey “two-tier” structure), resulting in inconsistency and delays.
The lakehouse is the answer to this downside. It’s a new, open structure that mixes the most effective of each worlds. Consider a lakehouse as a library constructed straight on high of that uncooked water reservoir. It provides warehouse-like construction and administration options like atomicity, consistency, isolation, sturdiness (ACID) transactions and knowledge versioning straight onto the low-cost storage of an information lake.
// Key Traits
- Information Lake Storage makes use of a budget, scalable object storage of an information lake for all of your knowledge varieties.
- One of many warehouse options is that it provides a administration layer on high that gives options historically solely present in knowledge warehouses, comparable to:
- ACID Transactions: Making certain knowledge consistency, even with a number of customers studying and writing concurrently.
- Schema Enforcement: The power to outline and implement knowledge buildings when wanted.
- Efficiency Optimization: Methods like caching and indexing to make querying quick, just like a warehouse.
- There’s direct entry; knowledge scientists and engineers can work straight with the uncooked knowledge information for machine studying, whereas enterprise analysts can question the identical knowledge utilizing BI instruments by way of the optimized layer.
This eliminates the necessity to keep a separate warehouse and a separate lake. It creates a single supply of fact for all of your knowledge wants.
// Reviewing Use Instances
- Working each BI reviews and superior machine studying fashions on the identical, constant dataset
- Constructing real-time dashboards on streaming knowledge that can be saved for historic evaluation
- Simplifying knowledge structure by changing a posh ETL pipeline that strikes knowledge between a lake and a warehouse
# Understanding the Information Mesh
Now we have mentioned knowledge lake, knowledge warehouse, and lakehouse; they’re all primarily technological architectures. They reply the query, “How do I retailer and course of my knowledge?”
Information mesh is completely different. It’s a socio-technical structure. It solutions the query, “How do I arrange my groups and my knowledge to scale successfully in a big group?”
Think about an enormous, monolithic software constructed by one big crew. It turns into sluggish, unstable, and onerous to handle. The answer was to interrupt the appliance into smaller, unbiased microservices owned by completely different groups. Information mesh applies this similar precept to knowledge.
As a substitute of getting one central knowledge crew answerable for all the information within the firm (a central knowledge lake or warehouse), knowledge mesh distributes the possession of information to the area groups that understand it finest.
// Figuring out the 4 Pillars of Information Mesh
Information mesh rests on 4 elementary rules, that are:
- Enterprise domains (advertising and marketing, gross sales, finance) personal their knowledge end-to-end.
- Datasets are handled as merchandise with clear documentation and high quality requirements.
- A self-serve knowledge platform the place infrastructure makes it straightforward for domains to handle and share knowledge.
- It turns into a centralized coverage with decentralized execution.
// Inspecting an Instance of a Information Mesh
Contemplate a big e-commerce firm. As a substitute of 1 central knowledge crew dealing with all knowledge:
- The advertising and marketing area owns buyer interplay knowledge, offering clear, documented datasets.
- The stock area owns product and inventory knowledge as a dependable product.
- The success area owns delivery and logistics knowledge.
- All domains use a shared self-service platform however keep their very own knowledge pipelines.
// Evaluating Information Mesh and Information Warehouse
Information mesh and knowledge warehouse serve completely different functions. An information warehouse is a know-how; an information mesh is an organizational framework. They aren’t primarily separate; you’ll be able to implement knowledge mesh rules whereas utilizing knowledge warehouses, knowledge lakes, or lakehouses as underlying applied sciences.
Information mesh is healthier when:
- Your group has a number of unbiased enterprise domains
- Central knowledge groups turn into issues
- You must scale knowledge initiatives throughout a big group
- Area consultants perceive their knowledge finest
Information warehouses stay higher for:
- Centralized reporting and analytics
- Organizations with sturdy central knowledge governance
- Smaller organizations with out a number of distinct domains
// Reviewing Frequent Instruments
Information mesh platforms embody instruments for knowledge discovery, sharing, and governance: Apache Atlas, DataHub, Amundsen, and cloud suppliers’ knowledge mesh options.
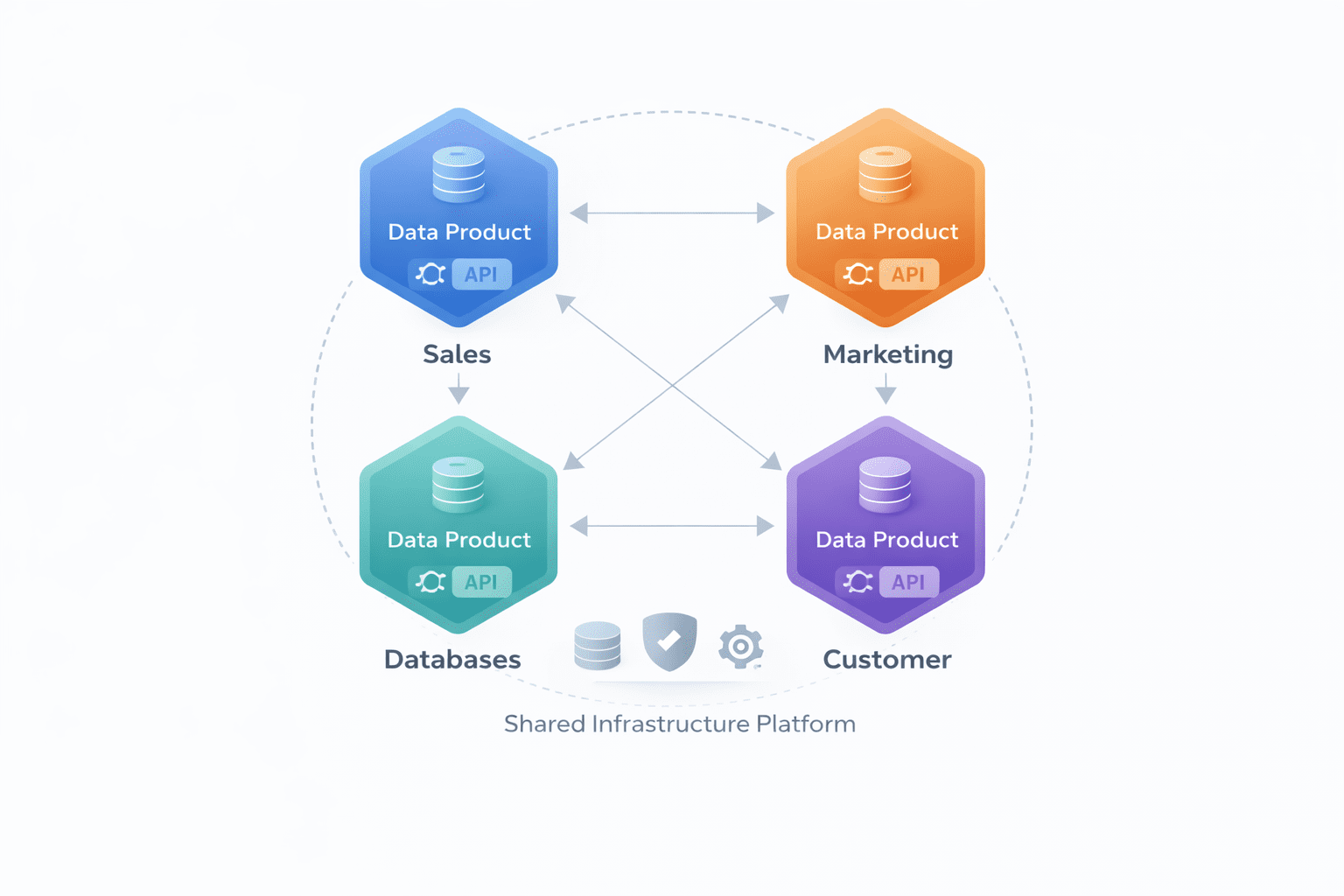
Information mesh structure displaying interconnected domains every proudly owning their knowledge merchandise with a shared infrastructure platform | Picture by Creator
// Key Ideas of Information Mesh
- Information is owned by the useful enterprise area that generates it (e.g., the gross sales crew owns gross sales knowledge, and the advertising and marketing crew owns advertising and marketing knowledge). They’re answerable for serving their knowledge as a “knowledge product.”
- Every area crew treats their datasets as a product for which it’s the steward. This implies the information have to be clear, well-documented, safe, and accessible by way of an outlined interface (like an API).
- A central platform crew offers the instruments and infrastructure, for instance, the “knowledge aircraft” that makes it straightforward for area groups to create, keep, and share their knowledge merchandise. That is typically constructed on a lakehouse structure.
- Governance just isn’t a top-down central mandate. As a substitute, a federated crew of leaders from completely different domains agrees on international requirements (for safety, interoperability, and many others.) that each one knowledge merchandise should comply with.
Consider it this fashion: you’ll be able to construct an information lakehouse (the know-how), however to handle it throughout an enormous firm with out chaos, you want an information mesh (the organizational mannequin).
// Reviewing Use Instances
- Massive enterprises with a whole lot of groups are struggling to seek out and belief knowledge from a central knowledge lake
- Organizations that wish to scale back the bottleneck of a central knowledge engineering crew
- Firms want to foster a tradition of information possession and collaboration throughout enterprise items
A diagram displaying a number of domains | Picture by Creator
To summarize the variations between these architectures, right here is a straightforward comparability desk.
| Characteristic | Information Warehouse | Information Lake | Lakehouse | Information Mesh |
|---|---|---|---|---|
| Main Focus | Know-how (Storage) | Know-how (Storage) | Know-how (Storage + Administration) | Group (Individuals + Course of) |
| Information Kind | Structured solely | Structured, semi-structured, unstructured | Structured, semi-structured, unstructured | All kinds, organized by area |
| Schema | Schema-on-write (enforced) | Schema-on-read (versatile) | Helps each | Outlined by area knowledge merchandise |
| Essential Customers | Enterprise analysts | Information scientists, engineers | Information scientists, analysts, and engineers | Everybody, throughout domains |
| Key Objective | Quick BI reporting & efficiency | Low-cost storage & flexibility | Single supply of fact, versatility | Decentralized possession & scale |
# Selecting the Proper Structure for Your Venture
So, as a newbie knowledge scientist, how do you determine what to make use of? The reply relies upon closely on the context of your group.
- If you happen to work at a small firm with conventional enterprise wants, you’ll doubtless work together with an information warehouse. Your focus will probably be on working SQL queries to generate reviews for stakeholders.
- If you happen to work at a tech firm coping with various knowledge, you’ll in all probability dwell in an information lake or a lakehouse. You’ll be pulling uncooked knowledge for testing and constructing options for fashions, and might have to make use of instruments like Spark or Python to course of it.
- If you happen to be a part of an enormous multinational company, you would possibly hear in regards to the knowledge mesh. As an information scientist in a mesh structure, you may be a shopper of information merchandise from different domains (like utilizing the clear customer_360 knowledge product from the gross sales area) and probably a producer of your personal knowledge merchandise (like a model_predictions knowledge product).
# Conclusion
On this article, you will have been in a position to perceive that the world of information structure just isn’t about selecting one winner. Every of those ideas solves a particular downside.
- Information warehouses supplied reliability and efficiency for enterprise reporting
- Information lakes embraced the range and quantity of massive knowledge
- Lakehouses merged the 2, creating a versatile but highly effective basis for all knowledge workloads
- Information mesh addresses the human and organizational problem of scaling knowledge possession in massive corporations
As you start your knowledge science journey, understanding the strengths and weaknesses of every will make you a more practical and well-rounded practitioner. You’ll know not simply the way to construct a mannequin but additionally the place to seek out the fitting knowledge, the way to retailer your outputs, and the way to make sure your work suits into the broader knowledge technique of your group.
Shittu Olumide is a software program engineer and technical author captivated with leveraging cutting-edge applied sciences to craft compelling narratives, with a eager eye for element and a knack for simplifying complicated ideas. You can too discover Shittu on Twitter.

