
This text discusses a brand new launch of a multimodal Hunyuan Video world mannequin referred to as ‘HunyuanCustom’. The brand new paper’s breadth of protection, mixed with a number of points in most of the equipped instance movies on the undertaking web page*, constrains us to extra normal protection than standard, and to restricted copy of the massive quantity of video materials accompanying this launch (since most of the movies require important re-editing and processing in an effort to enhance the readability of the format).
Please word moreover that the paper refers back to the API-based generative system Kling as ‘Keling’. For readability, I seek advice from ‘Kling’ as a substitute all through.
Tencent is within the strategy of releasing a brand new model of its Hunyuan Video mannequin, titled HunyuanCustom. The brand new launch is outwardly able to making Hunyuan LoRA fashions redundant, by permitting the consumer to create ‘deepfake’-style video customization by way of a single picture:
Click on to play. Immediate: ‘A person is listening to music and cooking snail noodles within the kitchen’. The brand new methodology in comparison with each close-source and open-source strategies, together with Kling, which is a major opponent on this house. Supply: https://hunyuancustom.github.io/ (warning: CPU/memory-intensive website!)
Within the left-most column of the video above, we see the only supply picture equipped to HunyuanCustom, adopted by the brand new system’s interpretation of the immediate within the second column, subsequent to it. The remaining columns present the outcomes from numerous proprietary and FOSS techniques: Kling; Vidu; Pika; Hailuo; and the Wan-based SkyReels-A2.
Within the video beneath, we see renders of three eventualities important to this launch: respectively, individual + object; single-character emulation; and digital try-on (individual + garments):
Click on to play. Three examples edited from the fabric on the supporting website for Hunyuan Video.
We are able to discover just a few issues from these examples, principally associated to the system counting on a single supply picture, as a substitute of a number of photos of the identical topic.
Within the first clip, the person is basically nonetheless dealing with the digital camera. He dips his head down and sideways at not way more than 20-25 levels of rotation, however, at an inclination in extra of that, the system would actually have to begin guessing what he seems like in profile. That is arduous, most likely inconceivable to gauge precisely from a sole frontal picture.
Within the second instance, we see that the little lady is smiling within the rendered video as she is within the single static supply picture. Once more, with this sole picture as reference, the HunyuanCustom must make a comparatively uninformed guess about what her ‘resting face’ seems like. Moreover, her face doesn’t deviate from camera-facing stance by greater than the prior instance (‘man consuming crisps’).
Within the final instance, we see that because the supply materials – the lady and the garments she is prompted into carrying – usually are not full photos, the render has cropped the state of affairs to suit – which is definitely quite resolution to an information difficulty!
The purpose is that although the brand new system can deal with a number of photos (comparable to individual + crisps, or individual + garments), it doesn’t apparently permit for a number of angles or various views of a single character, in order that numerous expressions or uncommon angles could possibly be accommodated. To this extent, the system might subsequently battle to switch the rising ecosystem of LoRA fashions which have sprung up round HunyuanVideo since its launch final December, since these will help HunyuanVideo to provide constant characters from any angle and with any facial features represented within the coaching dataset (20-60 photos is typical).
Wired for Sound
For audio, HunyuanCustom leverages the LatentSync system (notoriously arduous for hobbyists to arrange and get good outcomes from) for acquiring lip actions which can be matched to audio and textual content that the consumer provides:
Options audio. Click on to play. Varied examples of lip-sync from the HunyuanCustom supplementary website, edited collectively.
On the time of writing, there are not any English-language examples, however these look like quite good – the extra so if the tactic of making them is easily-installable and accessible.
Enhancing Present Video
The brand new system gives what look like very spectacular outcomes for video-to-video (V2V, or Vid2Vid) modifying, whereby a phase of an present (actual) video is masked off and intelligently changed by a topic given in a single reference picture. Beneath is an instance from the supplementary supplies website:
Click on to play. Solely the central object is focused, however what stays round it additionally will get altered in a HunyuanCustom vid2vid go.
As we are able to see, and as is customary in a vid2vid state of affairs, the whole video is to some extent altered by the method, although most altered within the focused area, i.e., the plush toy. Presumably pipelines could possibly be developed to create such transformations below a rubbish matte strategy that leaves the vast majority of the video content material an identical to the unique. That is what Adobe Firefly does below the hood, and does fairly effectively – however it’s an under-studied course of within the FOSS generative scene.
That mentioned, a lot of the various examples supplied do a greater job of focusing on these integrations, as we are able to see within the assembled compilation beneath:
Click on to play. Numerous examples of interjected content material utilizing vid2vid in HunyuanCustom, exhibiting notable respect for the untargeted materials.
A New Begin?
This initiative is a improvement of the Hunyuan Video undertaking, not a tough pivot away from that improvement stream. The undertaking’s enhancements are launched as discrete architectural insertions quite than sweeping structural adjustments, aiming to permit the mannequin to take care of id constancy throughout frames with out counting on subject-specific fine-tuning, as with LoRA or textual inversion approaches.
To be clear, subsequently, HunyuanCustom isn’t educated from scratch, however quite is a fine-tuning of the December 2024 HunyuanVideo basis mannequin.
Those that have developed HunyuanVideo LoRAs might marvel if they’ll nonetheless work with this re-creation, or whether or not they should reinvent the LoRA wheel but once more if they need extra customization capabilities than are constructed into this new launch.
Generally, a closely fine-tuned launch of a hyperscale mannequin alters the mannequin weights sufficient that LoRAs made for the sooner mannequin is not going to work correctly, or in any respect, with the newly-refined mannequin.
Generally, nevertheless, a fine-tune’s reputation can problem its origins: one instance of a fine-tune changing into an efficient fork, with a devoted ecosystem and followers of its personal, is the Pony Diffusion tuning of Secure Diffusion XL (SDXL). Pony presently has 592,000+ downloads on the ever-changing CivitAI area, with an enormous vary of LoRAs which have used Pony (and never SDXL) as the bottom mannequin, and which require Pony at inference time.
Releasing
The undertaking web page for the new paper (which is titled HunyuanCustom: A Multimodal-Pushed Structure for Personalized Video Era) options hyperlinks to a GitHub website that, as I write, simply grew to become practical, and seems to comprise all code and essential weights for native implementation, along with a proposed timeline (the place the one necessary factor but to come back is ComfyUI integration).
On the time of writing, the undertaking’s Hugging Face presence continues to be a 404. There may be, nevertheless, an API-based model of the place one can apparently demo the system, as long as you may present a WeChat scan code.
I’ve hardly ever seen such an elaborate and intensive utilization of such all kinds of initiatives in a single meeting, as is obvious in HunyuanCustom – and presumably among the licenses would in any case oblige a full launch.
Two fashions are introduced on the GitHub web page: a 720px1280px model requiring 8)GB of GPU Peak Reminiscence, and a 512px896px model requiring 60GB of GPU Peak Reminiscence.
The repository states ‘The minimal GPU reminiscence required is 24GB for 720px1280px129f however very sluggish…We advocate utilizing a GPU with 80GB of reminiscence for higher era high quality’ – and iterates that the system has solely been examined thus far on Linux.
The sooner Hunyuan Video mannequin has, since official launch, been quantized right down to sizes the place it may be run on lower than 24GB of VRAM, and it appears cheap to imagine that the brand new mannequin will likewise be tailored into extra consumer-friendly varieties by the neighborhood, and that it’ll rapidly be tailored to be used on Home windows techniques too.
Resulting from time constraints and the overwhelming quantity of data accompanying this launch, we are able to solely take a broader, quite than in-depth take a look at this launch. Nonetheless, let’s pop the hood on HunyuanCustom slightly.
A Take a look at the Paper
The information pipeline for HunyuanCustom, apparently compliant with the GDPR framework, incorporates each synthesized and open-source video datasets, together with OpenHumanVid, with eight core classes represented: people, animals, crops, landscapes, automobiles, objects, structure, and anime.

From the discharge paper, an summary of the varied contributing packages within the HunyuanCustom knowledge building pipeline. Supply: https://arxiv.org/pdf/2505.04512
Preliminary filtering begins with PySceneDetect, which segments movies into single-shot clips. TextBPN-Plus-Plus is then used to take away movies containing extreme on-screen textual content, subtitles, watermarks, or logos.
To handle inconsistencies in decision and period, clips are standardized to 5 seconds in size and resized to 512 or 720 pixels on the brief facet. Aesthetic filtering is dealt with utilizing Koala-36M, with a customized threshold of 0.06 utilized for the customized dataset curated by the brand new paper’s researchers.
The topic extraction course of combines the Qwen7B Giant Language Mannequin (LLM), the YOLO11X object recognition framework, and the favored InsightFace structure, to establish and validate human identities.
For non-human topics, QwenVL and Grounded SAM 2 are used to extract related bounding bins, that are discarded if too small.

Examples of semantic segmentation with Grounded SAM 2, used within the Hunyuan Management undertaking. Supply: https://github.com/IDEA-Analysis/Grounded-SAM-2
Multi-subject extraction makes use of Florence2 for bounding field annotation, and Grounded SAM 2 for segmentation, adopted by clustering and temporal segmentation of coaching frames.
The processed clips are additional enhanced through annotation, utilizing a proprietary structured-labeling system developed by the Hunyuan workforce, and which furnishes layered metadata comparable to descriptions and digital camera movement cues.
Masks augmentation methods, together with conversion to bounding bins, had been utilized throughout coaching to cut back overfitting and make sure the mannequin adapts to numerous object shapes.
Audio knowledge was synchronized utilizing the aforementioned LatentSync, and clips discarded if synchronization scores fall beneath a minimal threshold.
The blind picture high quality evaluation framework HyperIQA was used to exclude movies scoring below 40 (on HyperIQA’s bespoke scale). Legitimate audio tracks had been then processed with Whisper to extract options for downstream duties.
The authors incorporate the LLaVA language assistant mannequin throughout the annotation section, they usually emphasize the central place that this framework has in HunyuanCustom. LLaVA is used to generate picture captions and help in aligning visible content material with textual content prompts, supporting the development of a coherent coaching sign throughout modalities:
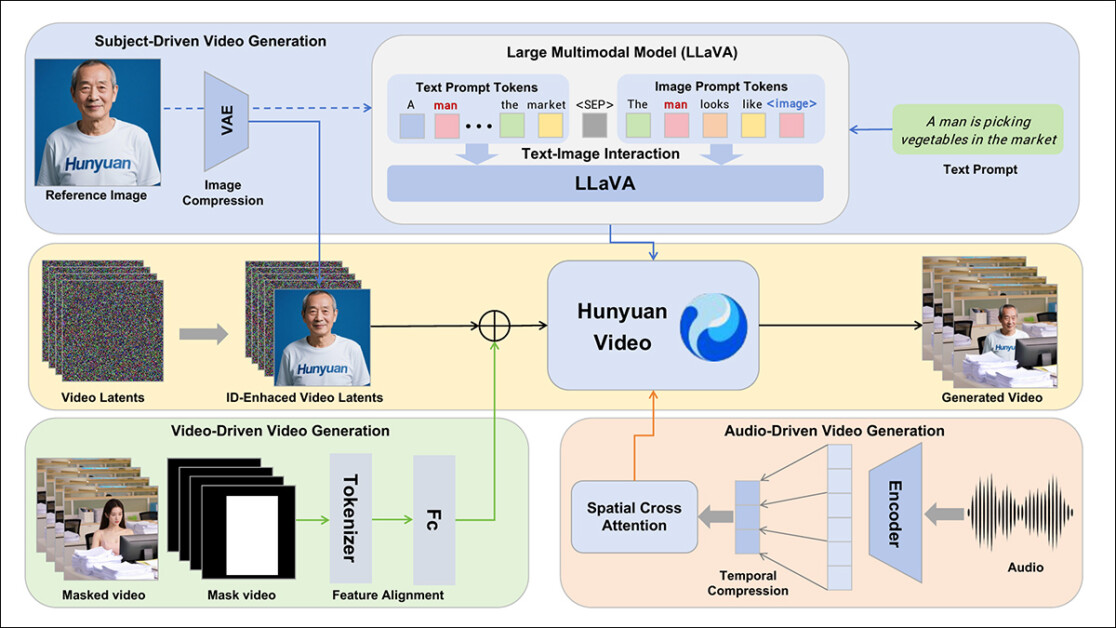
The HunyuanCustom framework helps identity-consistent video era conditioned on textual content, picture, audio, and video inputs.
By leveraging LLaVA’s vision-language alignment capabilities, the pipeline beneficial properties a further layer of semantic consistency between visible components and their textual descriptions – particularly helpful in multi-subject or complex-scene eventualities.
Customized Video
To permit video era based mostly on a reference picture and a immediate, the 2 modules centered round LLaVA had been created, first adapting the enter construction of HunyuanVideo in order that it may settle for a picture together with textual content.
This concerned formatting the immediate in a manner that embeds the picture straight or tags it with a brief id description. A separator token was used to cease the picture embedding from overwhelming the immediate content material.
Since LLaVA’s visible encoder tends to compress or discard fine-grained spatial particulars throughout the alignment of picture and textual content options (significantly when translating a single reference picture right into a normal semantic embedding), an id enhancement module was integrated. Since almost all video latent diffusion fashions have some issue sustaining an id with out an LoRA, even in a five-second clip, the efficiency of this module in neighborhood testing might show important.
In any case, the reference picture is then resized and encoded utilizing the causal 3D-VAE from the unique HunyuanVideo mannequin, and its latent inserted into the video latent throughout the temporal axis, with a spatial offset utilized to stop the picture from being straight reproduced within the output, whereas nonetheless guiding era.
The mannequin was educated utilizing Circulate Matching, with noise samples drawn from a logit-normal distribution – and the community was educated to recuperate the right video from these noisy latents. LLaVA and the video generator had been each fine-tuned collectively in order that the picture and immediate may information the output extra fluently and hold the topic id constant.
For multi-subject prompts, every image-text pair was embedded individually and assigned a definite temporal place, permitting identities to be distinguished, and supporting the era of scenes involving a number of interacting topics.
Sound and Imaginative and prescient
HunyuanCustom situations audio/speech era utilizing each user-input audio and a textual content immediate, permitting characters to talk inside scenes that mirror the described setting.
To help this, an Id-disentangled AudioNet module introduces audio options with out disrupting the id alerts embedded from the reference picture and immediate. These options are aligned with the compressed video timeline, divided into frame-level segments, and injected utilizing a spatial cross-attention mechanism that retains every body remoted, preserving topic consistency and avoiding temporal interference.
A second temporal injection module offers finer management over timing and movement, working in tandem with AudioNet, mapping audio options to particular areas of the latent sequence, and utilizing a Multi-Layer Perceptron (MLP) to transform them into token-wise movement offsets. This enables gestures and facial motion to comply with the rhythm and emphasis of the spoken enter with larger precision.
HunyuanCustom permits topics in present movies to be edited straight, changing or inserting folks or objects right into a scene while not having to rebuild the complete clip from scratch. This makes it helpful for duties that contain altering look or movement in a focused manner.
Click on to play. An extra instance from the supplementary website.
To facilitate environment friendly subject-replacement in present movies, the brand new system avoids the resource-intensive strategy of latest strategies such because the currently-popular VACE, or people who merge whole video sequences collectively, favoring as a substitute the compression of a reference video utilizing the pretrained causal 3D-VAE – aligning it with the era pipeline’s inside video latents, after which including the 2 collectively. This retains the method comparatively light-weight, whereas nonetheless permitting exterior video content material to information the output.
A small neural community handles the alignment between the clear enter video and the noisy latents utilized in era. The system checks two methods of injecting this data: merging the 2 units of options earlier than compressing them once more; and including the options body by body. The second methodology works higher, the authors discovered, and avoids high quality loss whereas protecting the computational load unchanged.
Knowledge and Exams
In checks, the metrics used had been: the id consistency module in ArcFace, which extracts facial embeddings from each the reference picture and every body of the generated video, after which calculates the common cosine similarity between them; topic similarity, through sending YOLO11x segments to Dino 2 for comparability; CLIP-B, text-video alignment, which measures similarity between the immediate and the generated video; CLIP-B once more, to calculate similarity between every body and each its neighboring frames and the primary body, in addition to temporal consistency; and dynamic diploma, as outlined by VBench.
As indicated earlier, the baseline closed supply rivals had been Hailuo; Vidu 2.0; Kling (1.6); and Pika. The competing FOSS frameworks had been VACE and SkyReels-A2.
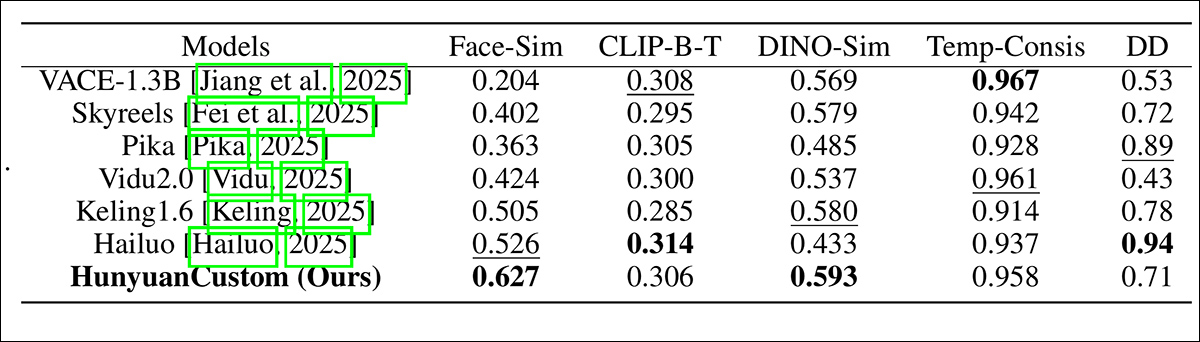
Mannequin efficiency analysis evaluating HunyuanCustom with main video customization strategies throughout ID consistency (Face-Sim), topic similarity (DINO-Sim), text-video alignment (CLIP-B-T), temporal consistency (Temp-Consis), and movement depth (DD). Optimum and sub-optimal outcomes are proven in daring and underlined, respectively.
Of those outcomes, the authors state:
‘Our [HunyuanCustom] achieves the perfect ID consistency and topic consistency. It additionally achieves comparable ends in immediate following and temporal consistency. [Hailuo] has the perfect clip rating as a result of it could actually comply with textual content directions effectively with solely ID consistency, sacrificing the consistency of non-human topics (the worst DINO-Sim). By way of Dynamic-degree, [Vidu] and [VACE] carry out poorly, which can be because of the small dimension of the mannequin.’
Although the undertaking website is saturated with comparability movies (the format of which appears to have been designed for web site aesthetics quite than straightforward comparability), it doesn’t presently characteristic a video equal of the static outcomes crammed collectively within the PDF, in regard to the preliminary qualitative checks. Although I embody it right here, I encourage the reader to make an in depth examination of the movies on the undertaking website, as they offer a greater impression of the outcomes:
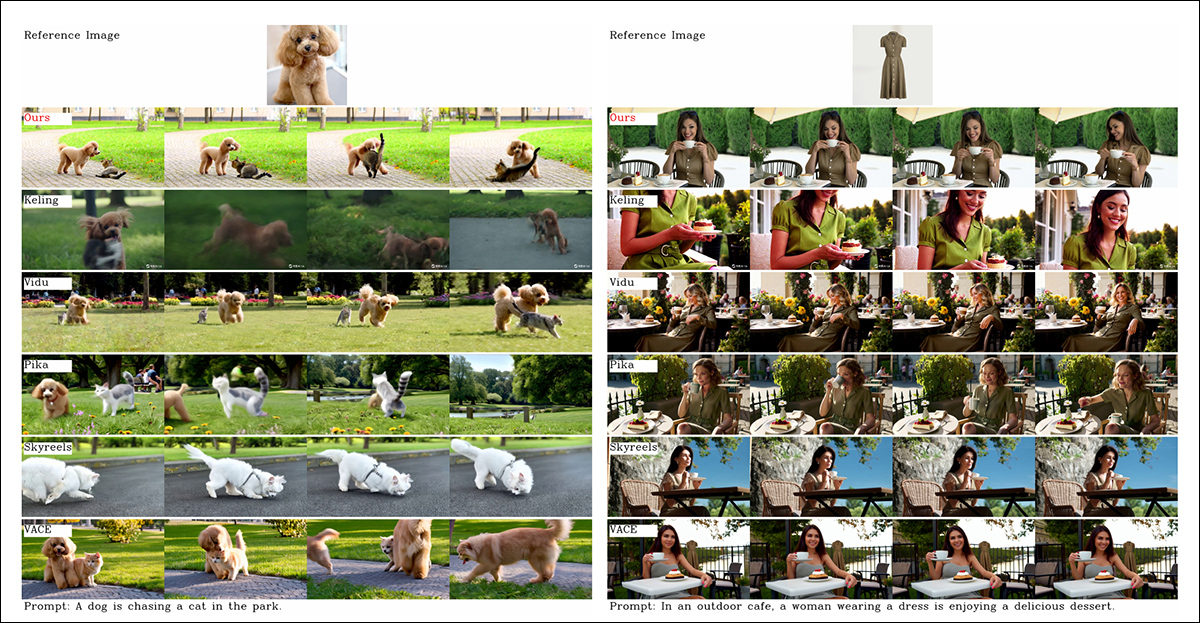
From the paper, a comparability on object-centered video customization. Although the viewer ought to (as all the time) seek advice from the supply PDF for higher decision, the movies on the undertaking website is likely to be a extra illuminating useful resource on this case.
The authors remark right here:
‘It may be seen that [Vidu], [Skyreels A2] and our methodology obtain comparatively good ends in immediate alignment and topic consistency, however our video high quality is healthier than Vidu and Skyreels, because of the nice video era efficiency of our base mannequin, i.e., [Hunyuanvideo-13B].
‘Amongst business merchandise, though [Kling] has video high quality, the primary body of the video has a copy-paste [problem], and generally the topic strikes too quick and [blurs], main a poor viewing expertise.’
The authors additional remark that Pika performs poorly by way of temporal consistency, introducing subtitle artifacts (results from poor knowledge curation, the place textual content components in video clips have been allowed to pollute the core ideas).
Hailuo maintains facial id, they state, however fails to protect full-body consistency. Amongst open-source strategies, VACE, the researchers assert, is unable to take care of id consistency, whereas they contend that HunyuanCustom produces movies with robust id preservation, whereas retaining high quality and variety.
Subsequent, checks had been carried out for multi-subject video customization, in opposition to the identical contenders. As within the earlier instance, the flattened PDF outcomes usually are not print equivalents of movies accessible on the undertaking website, however are distinctive among the many outcomes introduced:

Comparisons utilizing multi-subject video customizations. Please see PDF for higher element and backbone.
The paper states:
‘[Pika] can generate the required topics however reveals instability in video frames, with cases of a person disappearing in a single state of affairs and a girl failing to open a door as prompted. [Vidu] and [VACE] partially seize human id however lose important particulars of non-human objects, indicating a limitation in representing non-human topics.
‘[SkyReels A2] experiences extreme body instability, with noticeable adjustments in chips and quite a few artifacts in the correct state of affairs.
‘In distinction, our HunyuanCustom successfully captures each human and non-human topic identities, generates movies that adhere to the given prompts, and maintains excessive visible high quality and stability.’
An extra experiment was ‘digital human commercial’, whereby the frameworks had been tasked to combine a product with an individual:

From the qualitative testing spherical, examples of neural ‘product placement’. Please see PDF for higher element and backbone.
For this spherical, the authors state:
‘The [results] exhibit that HunyuanCustom successfully maintains the id of the human whereas preserving the main points of the goal product, together with the textual content on it.
‘Moreover, the interplay between the human and the product seems pure, and the video adheres carefully to the given immediate, highlighting the substantial potential of HunyuanCustom in producing commercial movies.’
One space the place video outcomes would have been very helpful was the qualitative spherical for audio-driven topic customization, the place the character speaks the corresponding audio from a text-described scene and posture.
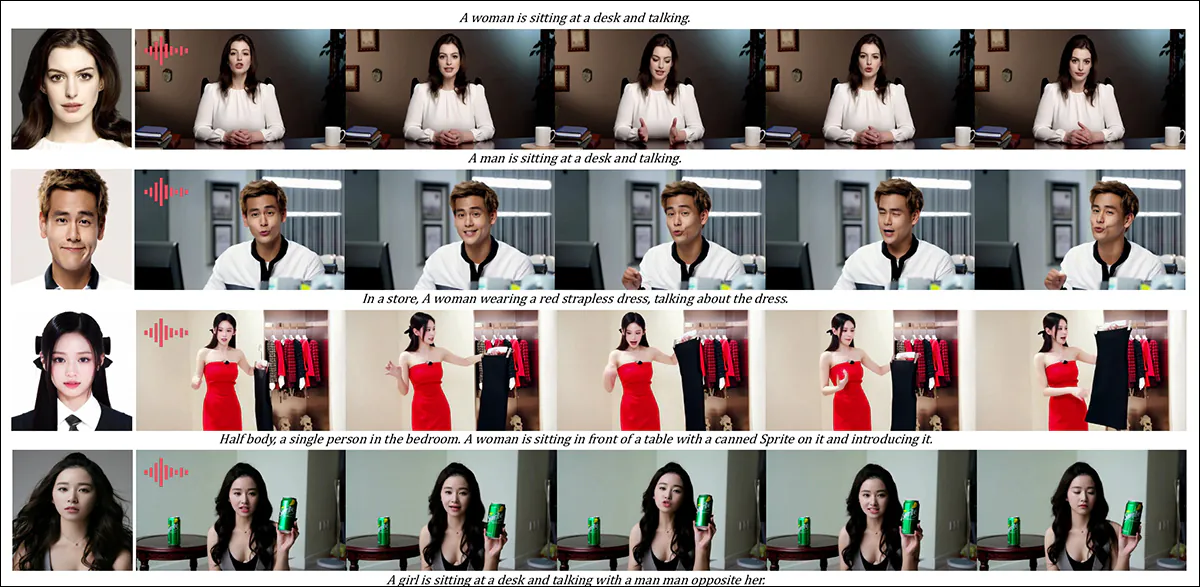
Partial outcomes given for the audio spherical – although video outcomes might need been preferable on this case. Solely the highest half of the PDF determine is reproduced right here, as it’s massive and arduous to accommodate on this article. Please seek advice from supply PDF for higher element and backbone.
The authors assert:
‘Earlier audio-driven human animation strategies enter a human picture and an audio, the place the human posture, apparel, and surroundings stay according to the given picture and can’t generate movies in different gesture and surroundings, which can [restrict] their software.
‘…[Our] HunyuanCustom permits audio-driven human customization, the place the character speaks the corresponding audio in a text-described scene and posture, permitting for extra versatile and controllable audio-driven human animation.’
Additional checks (please see PDF for all particulars) included a spherical pitting the brand new system in opposition to VACE and Kling 1.6 for video topic substitute:

Testing topic substitute in video-to-video mode. Please seek advice from supply PDF for higher element and backbone.
Of those, the final checks introduced within the new paper, the researchers opine:
‘VACE suffers from boundary artifacts as a result of strict adherence to the enter masks, leading to unnatural topic shapes and disrupted movement continuity. [Kling], in distinction, reveals a copy-paste impact, the place topics are straight overlaid onto the video, resulting in poor integration with the background.
‘As compared, HunyuanCustom successfully avoids boundary artifacts, achieves seamless integration with the video background, and maintains robust id preservation—demonstrating its superior efficiency in video modifying duties.’
Conclusion
This can be a fascinating launch, not least as a result of it addresses one thing that the ever-discontent hobbyist scene has been complaining about extra recently – the dearth of lip-sync, in order that the elevated realism succesful in techniques comparable to Hunyuan Video and Wan 2.1 is likely to be given a brand new dimension of authenticity.
Although the format of almost all of the comparative video examples on the undertaking website makes it quite tough to match HunyuanCustom’s capabilities in opposition to prior contenders, it have to be famous that very, only a few initiatives within the video synthesis house have the braveness to pit themselves in checks in opposition to Kling, the business video diffusion API which is all the time hovering at or close to the highest of the leader-boards; Tencent seems to have made headway in opposition to this incumbent in a quite spectacular method.
* The difficulty being that among the movies are so extensive, brief, and high-resolution that they won’t play in customary video gamers comparable to VLC or Home windows Media Participant, displaying black screens.
First revealed Thursday, Might 8, 2025

