
Hugging Face has simply launched AI Sheets, a free, open-source, and local-first no-code instrument designed to radically simplify dataset creation and enrichment with AI. AI Sheets goals to democratize entry to AI-powered knowledge dealing with by merging the intuitive spreadsheet interface with direct entry to main open-source Giant Language Fashions (LLMs) like Qwen, Kimi, Llama 3, and lots of others, together with customized fashions, all with out writing a line of code.
What’s AI Sheets?
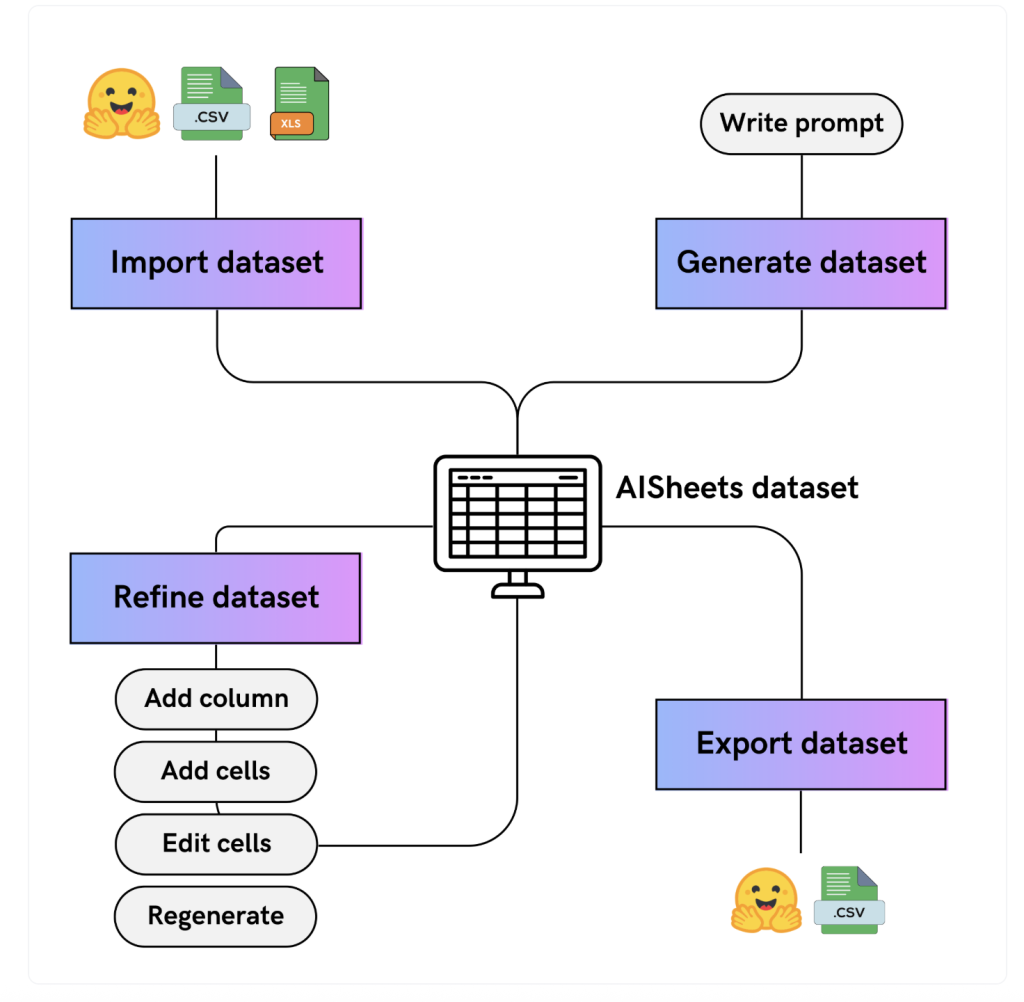
AI Sheets is a spreadsheet-style knowledge instrument purpose-built for working with datasets and leveraging AI fashions. Not like conventional spreadsheets, every cell or column in AI Sheets will be powered and enriched by pure language prompts utilizing built-in AI fashions. Customers can:dev+3
- Construct, clear, rework, and enrich datasets immediately within the browser or through native deployment.
- Apply open-source fashions from Hugging Face Hub, or run their very own native customized fashions (so long as they help OpenAI API spec).
- Collaboratively experiment with speedy knowledge prototyping, fine-tune AI outputs by enhancing and validating cells, and run large-scale knowledge era pipelines.
Key Options
- No-Code Workflow: Customers work together with an intuitive spreadsheet UI, making use of AI transformations utilizing prompts—no Python or coding required.
- Mannequin Integration: Immediately entry hundreds of fashions, together with in style LLMs (Qwen, Kimi, Llama 3, and so on.). Helps native deployment through servers like Ollama, empowering you to make use of fine-tuned or domain-specific fashions with zero cloud dependency.
- Information Privateness: When run domestically, all knowledge stays in your machine, assembly safety and compliance wants.
- Open-Supply & Free: Each hosted and native variations can be found with zero value, supporting the open AI group and customization.
- Versatile Deployment: Runs fully in-browser (through Hugging Face Areas), or domestically for max privateness, efficiency, and infrastructure management.
How It Works
- Immediate-Pushed Columns: Create new columns by getting into plain textual content prompts, permitting the mannequin to generate or enrich knowledge.
- Native Mannequin Assist: Set surroundings variables (
MODEL_ENDPOINT_URLandMODEL_ENDPOINT_NAME) to seamlessly join AI Sheets along with your native inference server (e.g., Ollama with Llama 3 loaded)—absolutely OpenAI API appropriate. - Use Instances: AI Sheets helps duties like sentiment evaluation, knowledge classification, textual content era, fast dataset enrichment, even batch processing throughout large datasets—all in a collaborative, visible surroundings.
Affect
AI Sheets dramatically lowers the technical barrier for superior dataset preparation and enrichment. Information scientists can experiment sooner, analysts get highly effective automation, and non-technical customers can leverage AI with none coding. By combining the Hugging Face open-source mannequin ecosystem with a no-code interface, AI Sheets is positioned to grow to be an important instrument for practitioners, researchers, and groups searching for versatile, non-public, and scalable AI knowledge options.
Supported LLMs
- Qwen
- Kimi
- Llama 3
- OpenAI’s gpt-oss (through Inference Suppliers)
- Any customized mannequin supporting the OpenAI API spec
Getting Began
- Attempt in-browser: Hugging Face Areas hosts AI Sheets for fast use.
- Deploy domestically: Clone from GitHub (
huggingface/aisheets), arrange your inference endpoint, and run in your infrastructure for privateness and velocity. - Documentation: The GitHub README and Hugging Face weblog present step-by-step setup directions and instance workflows for each cloud and native deployments.
In Abstract
Hugging Face AI Sheets is a free, open-source, and local-first no-code answer that empowers anybody to construct, enrich, and rework datasets utilizing main open-source AI fashions, with seamless help for customized native deployments, making superior AI accessible and collaborative for all.
Try the GitHub Repo, Attempt it right here and Technical particulars. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter.

Michal Sutter is a knowledge science skilled with a Grasp of Science in Information Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at remodeling advanced datasets into actionable insights.

