
AI establishments develop heterogeneous fashions for particular duties however face knowledge shortage challenges throughout coaching. Conventional Federated Studying (FL) helps solely homogeneous mannequin collaboration, which wants an identical architectures throughout all purchasers. Nonetheless, purchasers develop mannequin architectures for his or her distinctive necessities. Furthermore, sharing effort-intensive domestically educated fashions incorporates mental property and reduces members’ curiosity in partaking in collaborations. Heterogeneous Federated Studying (HtFL) addresses these limitations, however the literature lacks a unified benchmark for evaluating HtFL throughout varied domains and facets.
Background and Classes of HtFL Strategies
Present FL benchmarks concentrate on knowledge heterogeneity utilizing homogeneous consumer fashions however neglect actual eventualities that contain mannequin heterogeneity. Consultant HtFL strategies fall into three most important classes addressing these limitations. Partial parameter sharing strategies equivalent to LG-FedAvg, FedGen, and FedGH preserve heterogeneous function extractors whereas assuming homogeneous classifier heads for information switch. Mutual distillation, equivalent to FML, FedKD, and FedMRL, trains and shares small auxiliary fashions by means of distillation methods. Prototype sharing strategies switch light-weight class-wise prototypes as international information, gathering native prototypes from purchasers, and gathering them on servers to information native coaching. Nonetheless, it stays unclear whether or not current HtFL strategies carry out constantly throughout various eventualities.
Introducing HtFLlib: A Unified Benchmark
Researchers from Shanghai Jiao Tong College, Beihang College, Chongqing College, Tongji College, Hong Kong Polytechnic College, and The Queen’s College of Belfast have proposed the primary Heterogeneous Federated Studying Library (HtFLlib), a simple and extensible methodology for integrating a number of datasets and mannequin heterogeneity eventualities. This methodology integrates:
- 12 datasets throughout varied domains, modalities, and knowledge heterogeneity eventualities
- 40 mannequin architectures starting from small to massive, throughout three modalities.
- A modularized and easy-to-extend HtFL codebase with implementations of 10 consultant HtFL strategies.
- Systematic evaluations overlaying accuracy, convergence, computation prices, and communication prices.
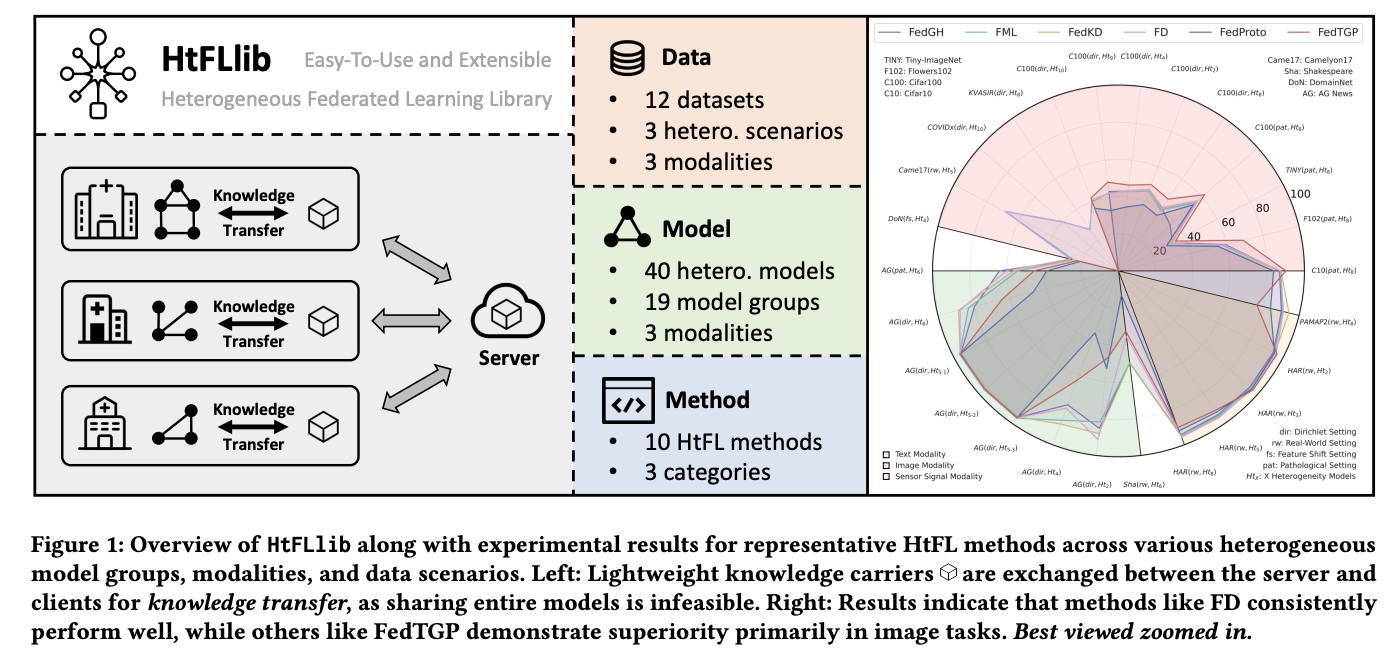
Datasets and Modalities in HtFLlib
HtFLlib incorporates detailed knowledge heterogeneity eventualities divided into three settings: Label Skew with Pathological and Dirichlet as subsettings, Characteristic Shift, and Actual-World. It integrates 12 datasets, together with Cifar10, Cifar100, Flowers102, Tiny-ImageNet, KVASIR, COVIDx, DomainNet, Camelyon17, AG Information, Shakespeare, HAR, and PAMAP2. These datasets fluctuate considerably in area, knowledge quantity, and sophistication numbers, demonstrating HtFLlib’s complete and versatile nature. Furthermore, researchers’ most important focus is on picture knowledge, particularly the label skew setting, as picture duties are probably the most generally used duties throughout varied fields. The HtFL strategies are evaluated throughout picture, textual content, and sensor sign duties to guage their respective strengths and weaknesses.
Efficiency Evaluation: Picture Modality
For picture knowledge, most HtFL strategies present decreased accuracy as mannequin heterogeneity will increase. The FedMRL exhibits superior energy by means of its mixture of auxiliary international and native fashions. When introducing heterogeneous classifiers that make partial parameter sharing strategies inapplicable, FedTGP maintains superiority throughout various settings because of its adaptive prototype refinement capability. Medical dataset experiments with black-boxed pre-trained heterogeneous fashions exhibit that HtFL enhances mannequin high quality in comparison with pre-trained fashions and achieves larger enhancements than auxiliary fashions, equivalent to FML. For textual content knowledge, FedMRL’s benefits in label skew settings diminish in real-world settings, whereas FedProto and FedTGP carry out comparatively poorly in comparison with picture duties.
Conclusion
In conclusion, researchers launched HtFLlib, a framework that addresses the essential hole in HtFL benchmarking by offering unified analysis requirements throughout various domains and eventualities. HtFLlib’s modular design and extensible structure present an in depth benchmark for each analysis and sensible functions in HtFL. Furthermore, its capability to help heterogeneous fashions in collaborative studying opens the best way for future analysis into using complicated pre-trained massive fashions, black-box methods, and diverse architectures throughout completely different duties and modalities.
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, be happy to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our Publication.

Sajjad Ansari is a remaining yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a concentrate on understanding the impression of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.


