
Was this response higher or worse?BetterWorseSame
It has been mentioned that info principle and machine studying are “two sides of the identical coin” due to their shut relationship. One beautiful relationship is the basic similarity between probabilistic information fashions and lossless compression. The important principle defining this idea is the supply coding theorem, which states that the expected message size in bits of an excellent entropy encoder equals the unfavourable log2 likelihood of the statistical mannequin. In different phrases, lowering the quantity of bits wanted for every message is akin to growing the log2 -likelihood. Completely different methods to realize lossless compression with a probabilistic mannequin embody Huffman coding, arithmetic coding, and uneven numeral programs.
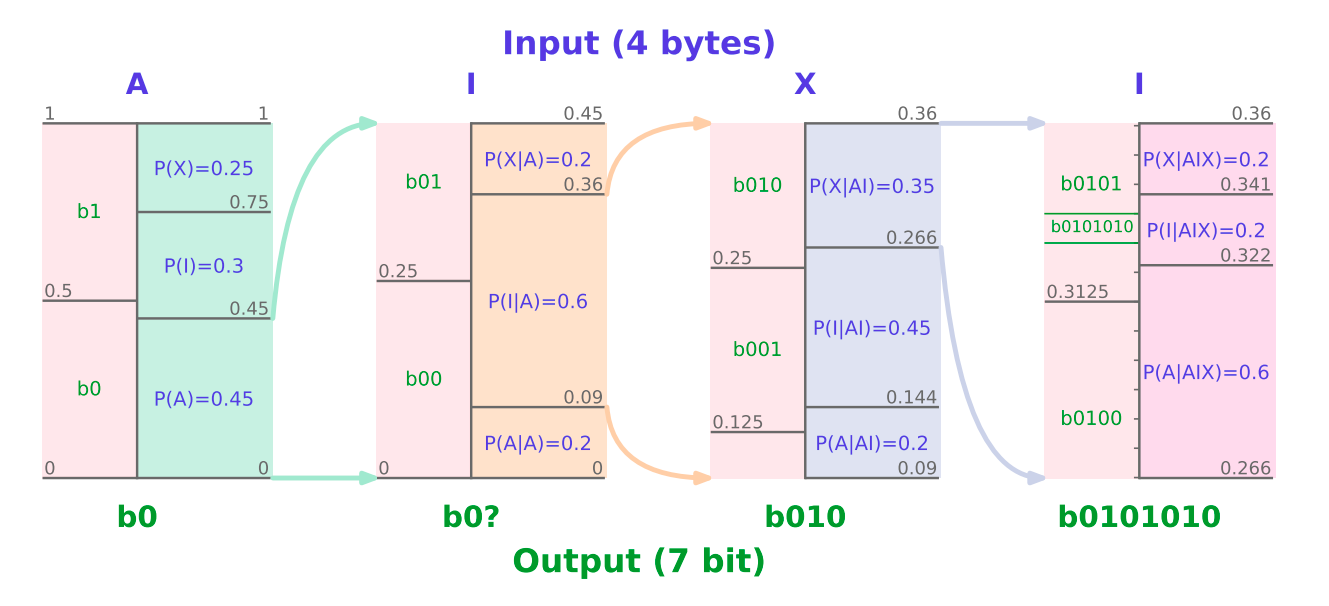
Determine 1 | Arithmetic encoding of the sequence ‘AIXI’ with a probabilistic (language) mannequin P (each in blue) yields the binary code ‘0101001’ (in inexperienced). Information is compressed through arithmetic coding by giving symbols sure intervals relying on the likelihood given by P. It step by step smoothes out these pauses to supply compressed bits that stand in for the unique message. Based mostly on the incoming compressed bits, arithmetic coding initializes an interval throughout decoding. To rebuild the unique message, it iteratively matches intervals with symbols utilizing the possibilities supplied by P.
The overall compression effectivity depends on the capabilities of the probabilistic mannequin since arithmetic coding is understood to be optimum by way of coding size (Fig. 1). Moreover, large pre-trained Transformers, often known as basis fashions, have lately demonstrated glorious efficiency throughout quite a lot of prediction duties and are thus engaging candidates to be used with arithmetic coding. Transformer-based compression with arithmetic coding has generated cutting-edge leads to on-line and offline environments. The offline possibility they take into account of their work entails coaching the mannequin on an exterior dataset earlier than utilizing it to compress a (maybe totally different) information stream. Within the on-line context, a pseudo-randomly initialized mannequin is instantly skilled on the stream of knowledge that’s to be compressed. Consequently, offline compression makes use of a hard and fast set of mannequin parameters and is finished in context.
Transformers are completely suited to offline discount since they’ve proven excellent in-context studying capabilities. Transformers are taught to compress successfully, as they are going to describe on this process. Due to this fact, they should have sturdy contextual studying expertise. The context size, a vital offline compression limiting issue, determines the utmost variety of bytes a mannequin can squeeze concurrently. Transformers are computationally intensive and might solely compress a small quantity of knowledge (a “token” is programmed with 2 or 3 bytes). Since many tough predicting duties (corresponding to algorithmic reasoning or long-term reminiscence) want prolonged contexts, extending the context lengths of those fashions is a major situation that’s receiving extra consideration. The in-context compression view sheds mild on how the current basis fashions fail. Researchers from Google DeepMind and Meta AI & Inria promote utilizing compression to discover the prediction downside and assess how effectively large (basis) fashions compress information.
They make the next contributions:
• They do empirical analysis on the inspiration fashions’ capability for lossless compression. To that goal, they discover arithmetic coding’s position in predictive mannequin compression and draw consideration to the connection between the 2 fields of research.
• They display that basis fashions with in-context studying capabilities, skilled totally on textual content, are general-purpose compressors. As an example, Chinchilla 70B outperforms domain-specific compressors like PNG (58.5%) or FLAC (30.3%), reaching compression charges of 43.4% on ImageNet patches and 16.4% on LibriSpeech samples.
• They current a contemporary perspective on scaling legal guidelines by demonstrating that scaling shouldn’t be a magic repair and that the dimensions of the dataset units a strict higher restrict on mannequin dimension by way of compression efficiency.
• They use compressors as generative fashions and use the compression-prediction equivalence to symbolize the underlying compressor’s efficiency graphically.
• They present that tokenization, which may be considered a pre-compression, doesn’t, on common, enhance compression efficiency. As a substitute, it permits fashions to extend the knowledge content material of their atmosphere and is usually used to reinforce prediction efficiency.
Take a look at the Paper. All Credit score For This Analysis Goes To the Researchers on This Undertaking. Additionally, don’t overlook to hitch our 30k+ ML SubReddit, 40k+ Fb Neighborhood, Discord Channel, and E-mail E-newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
Should you like our work, you’ll love our e-newsletter..
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at the moment pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on initiatives geared toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is obsessed with constructing options round it. He loves to attach with individuals and collaborate on fascinating initiatives.

