

Google has launched Gemini 3.1 Flash-Lite, essentially the most cost-efficient entry within the Gemini 3 mannequin sequence. Designed for ‘intelligence at scale,’ this mannequin is optimized for high-volume duties the place low latency and cost-per-token are the first engineering constraints. It’s presently accessible in Public Preview by way of the Gemini API (Google AI Studio) and Vertex AI.
Core Function: Variable ‘Considering Ranges’
A major architectural replace within the 3.1 sequence is the introduction of Considering Ranges. This characteristic permits builders to programmatically regulate the mannequin’s reasoning depth primarily based on the particular complexity of a request.
By deciding on between Minimal, Low, Medium, or Excessive pondering ranges, you may optimize the trade-off between latency and logical accuracy.
- Minimal/Low: Superb for high-throughput, low-latency duties akin to classification, primary sentiment evaluation, or easy information extraction.
- Medium/Excessive: Makes use of Deep Suppose Mini logic to deal with advanced instruction-following, multi-step reasoning, and structured information technology.
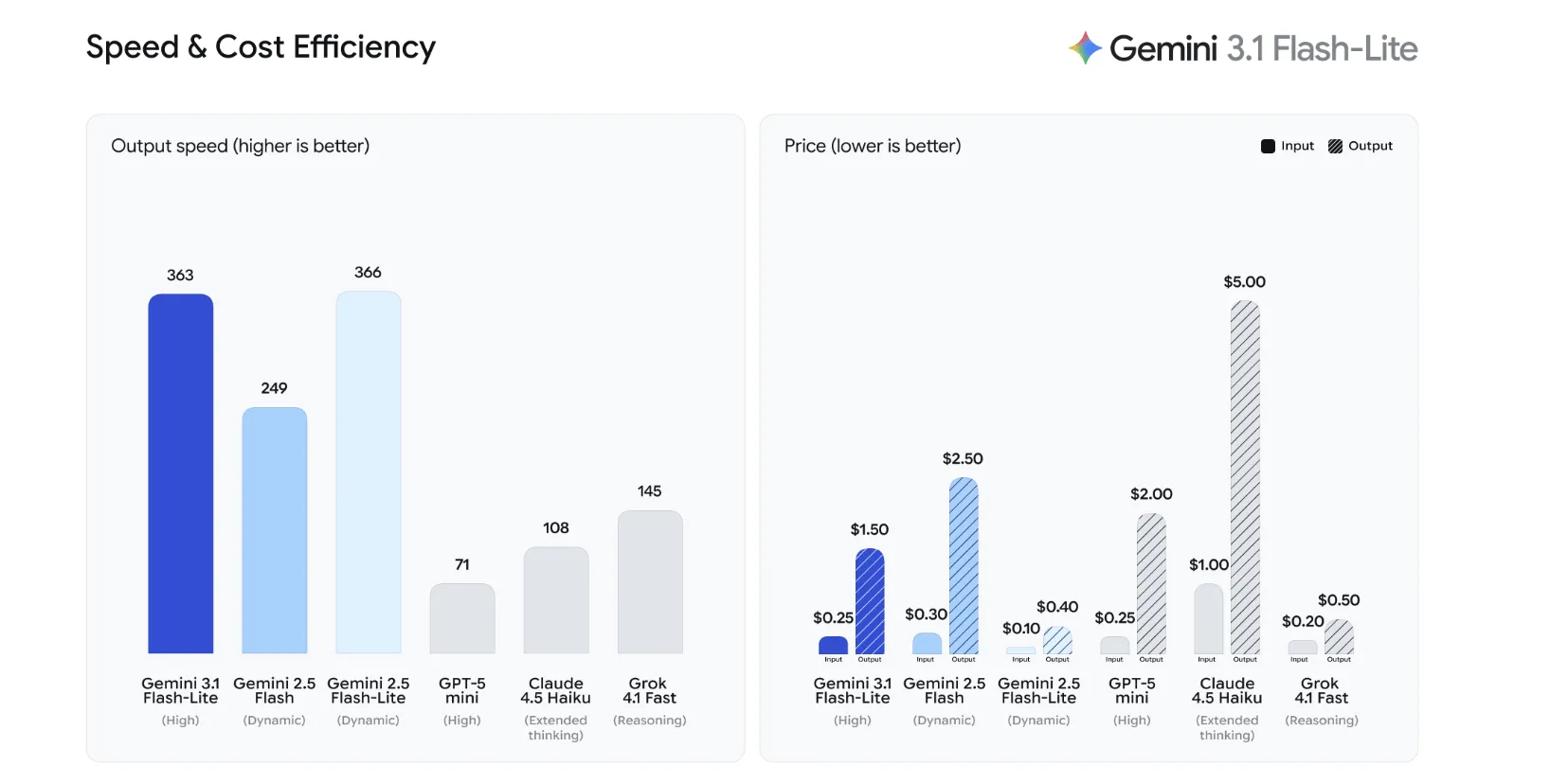
Efficiency and Effectivity Benchmarks
Gemini 3.1 Flash-Lite is designed to interchange Gemini 2.5 Flash for manufacturing workloads that require sooner inference with out sacrificing output high quality. The mannequin achieves a 2.5x sooner Time to First Token (TTFT) and a 45% enhance in total output velocity in comparison with its predecessor.
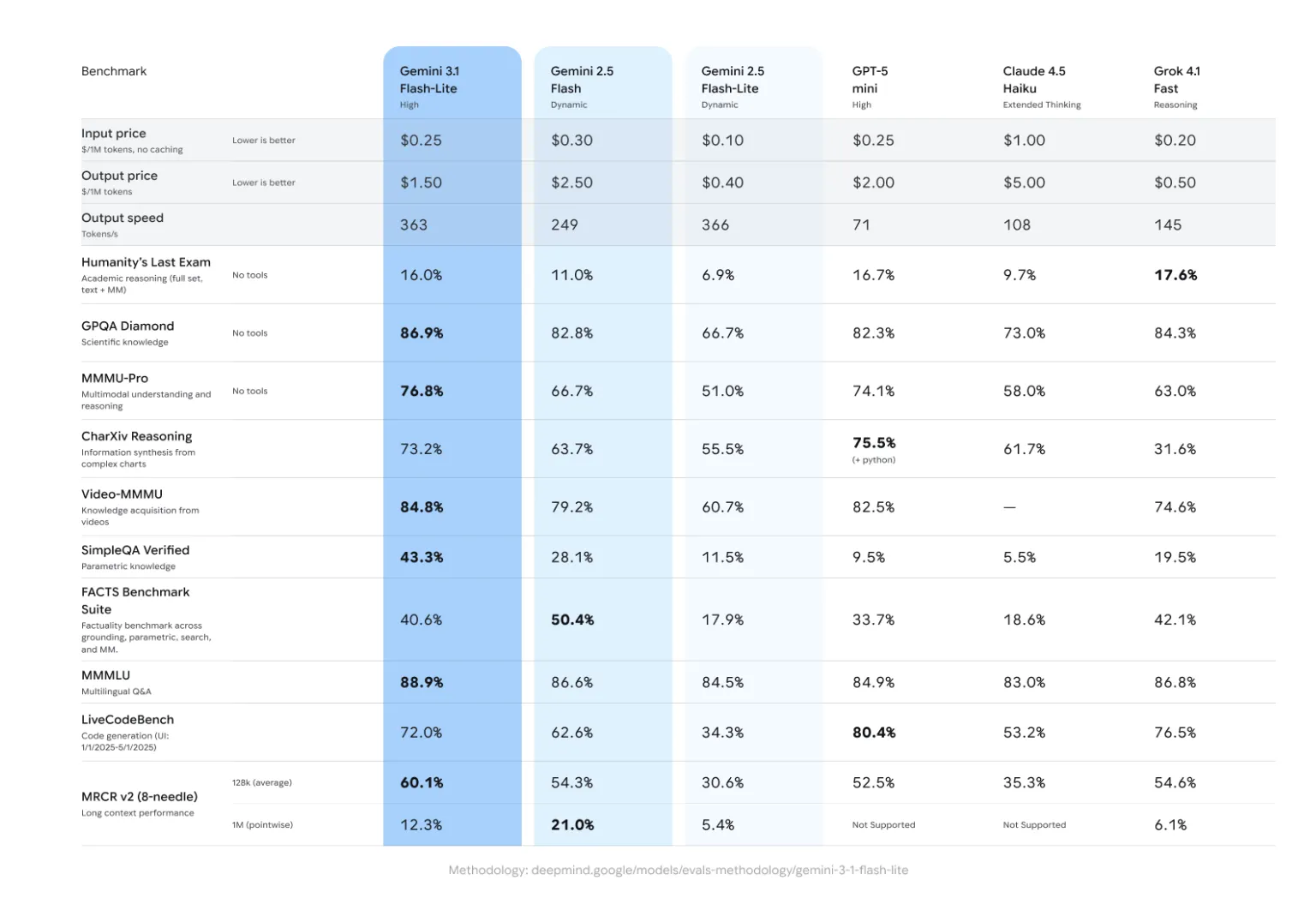
On the GPQA Diamond benchmark—a measure of expert-level reasoning—Gemini 3.1 Flash-Lite scored 86.9%, matching or exceeding the standard of bigger fashions within the earlier technology whereas working at a considerably decrease computational value.
Comparability Desk: Gemini 3.1 Flash-Lite vs. Gemini 2.5 Flash
| Metric | Gemini 2.5 Flash | Gemini 3.1 Flash-Lite |
| Enter Price (per 1M tokens) | Larger | $0.25 |
| Output Price (per 1M tokens) | Larger | $1.50 |
| TTFT Pace | Baseline | 2.5x Sooner |
| Output Throughput | Baseline | 45% Sooner |
| Reasoning (GPQA Diamond) | Aggressive | 86.9% |
Technical Use Circumstances for Manufacturing
The three.1 Flash-Lite mannequin is particularly tuned for workloads that contain advanced buildings and long-sequence logic:
- UI and Dashboard Technology: The mannequin is optimized for producing hierarchical code (HTML/CSS, React elements) and structured JSON required to render advanced information visualizations.
- System Simulations: It maintains logical consistency over lengthy contexts, making it appropriate for creating setting simulations or agentic workflows that require state-tracking.
- Artificial Information Technology: As a result of low enter value ($0.25/1M tokens), it serves as an environment friendly engine for distilling data from bigger fashions like Gemini 3.1 Extremely into smaller, domain-specific datasets.
Key Takeaways
- Superior Value-to-Efficiency Ratio: Gemini 3.1 Flash-Lite is essentially the most cost-efficient mannequin within the Gemini 3 sequence, priced at $0.25 per 1M enter tokens and $1.50 per 1M output tokens. It outperforms Gemini 2.5 Flash with a 2.5x sooner Time to First Token (TTFT) and 45% increased output velocity.
- Introduction of ‘Considering Ranges’: A brand new architectural characteristic permits builders to programmatically toggle between Minimal, Low, Medium, and Excessive reasoning intensities. This supplies granular management to stability latency towards reasoning depth relying on the duty’s complexity.
- Excessive Reasoning Benchmark: Regardless of its ‘Lite’ designation, the mannequin maintains high-tier logic, scoring 86.9% on the GPQA Diamond benchmark. This makes it appropriate for expert-level reasoning duties that beforehand required bigger, costlier fashions.
- Optimized for Structured Workloads: The mannequin is particularly tuned for ‘intelligence at scale,’ excelling at producing advanced UI/dashboards, creating system simulations, and sustaining logical consistency throughout long-sequence code technology.
- Seamless API Integration: Presently accessible in Public Preview, the mannequin makes use of the
gemini-3.1-flash-lite-previewendpoint by way of the Gemini API and Vertex AI. It helps multimodal inputs (textual content, picture, video) whereas sustaining a regular 128k context window.
Take a look at the Public Preview by way of the Gemini API (Google AI Studio) and Vertex AI. Additionally, be happy to comply with us on Twitter and don’t neglect to affix our 120k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you may be a part of us on telegram as properly.

