

Writing a analysis paper is brutal. Even after the experiments are carried out, a researcher nonetheless faces weeks of translating messy lab notes, scattered outcomes tables, and half-formed concepts into a sophisticated, logically coherent manuscript formatted exactly to a convention’s specs. For a lot of recent researchers, that translation work is the place papers go to die.
A crew at Google Cloud AI Analysis suggest ‘PaperOrchestra‘, a multi-agent system that autonomously converts unstructured pre-writing supplies — a tough concept abstract and uncooked experimental logs — right into a submission-ready LaTeX manuscript, full with a literature evaluate, generated figures, and API-verified citations.

The Core Drawback It’s Fixing
Earlier automated writing programs, like PaperRobot, may generate incremental textual content sequences however couldn’t deal with the total complexity of a data-driven scientific narrative. More moderen end-to-end autonomous analysis frameworks like AI Scientist-v1 (which launched automated experimentation and drafting by way of code templates) and its successor AI Scientist-v2 (which will increase autonomy utilizing agentic tree-search) automate your complete analysis loop — however their writing modules are tightly coupled to their very own inner experimental pipelines. You may’t simply hand them your knowledge and anticipate a paper. They’re not standalone writers.
In the meantime, programs specialised in literature opinions, similar to AutoSurvey2 and LiRA, produce complete surveys however lack the contextual consciousness to write down a focused Associated Work part that clearly positions a selected new technique in opposition to prior artwork. CycleResearcher requires a pre-existing structured BibTeX reference record as enter — an artifact hardly ever accessible at first of writing — and fails totally on unstructured inputs.
The result’s a spot: no current software may take unconstrained human-provided supplies — the type of factor an actual researcher would possibly even have after ending experiments — and produce a whole, rigorous manuscript by itself. PaperOrchestra is constructed particularly to fill that hole.
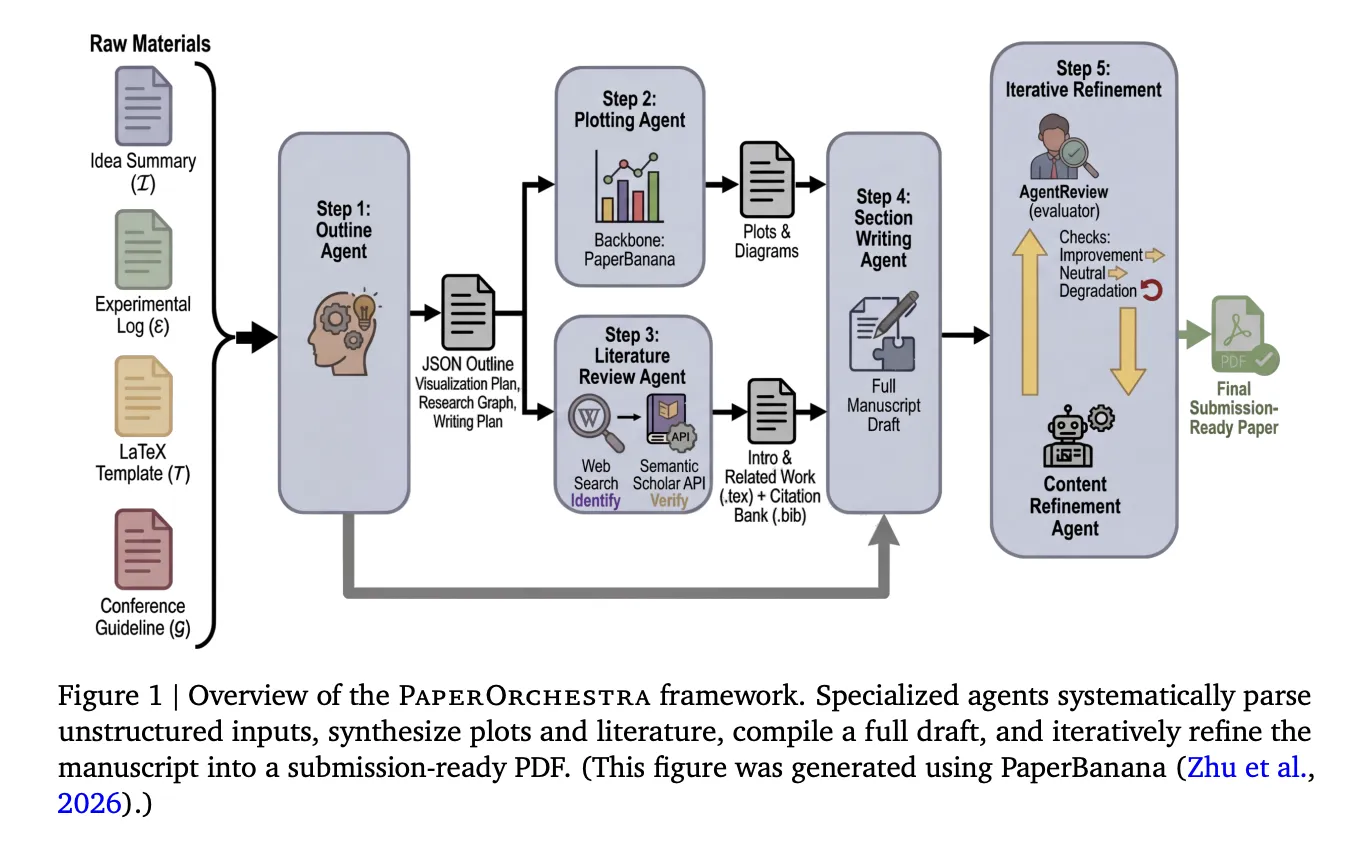
How the Pipeline Works
PaperOrchestra orchestrates 5 specialised brokers that work in sequence, with two working in parallel:
Step 1 — Define Agent: This agent reads the concept abstract, experimental log, LaTeX convention template, and convention tips, then produces a structured JSON define. This define features a visualization plan (specifying what plots and diagrams to generate), a focused literature search technique separating macro-level context for the Introduction from micro-level methodology clusters for the Associated Work, and a section-level writing plan with quotation hints for each dataset, optimizer, metric, and baseline technique talked about within the supplies.
Steps 2 & 3 — Plotting Agent and Literature Evaluate Agent (parallel): The Plotting Agent executes the visualization plan utilizing PaperBanana, a tutorial illustration software that makes use of a Imaginative and prescient-Language Mannequin (VLM) critic to guage generated photos in opposition to design targets and iteratively revise them. Concurrently, the Literature Evaluate Agent conducts a two-phase quotation pipeline: it makes use of an LLM outfitted with internet search to establish candidate papers, then verifies each by the Semantic Scholar API, checking for a legitimate fuzzy title match utilizing Levenshtein distance, retrieving the summary and metadata, and imposing a temporal cutoff tied to the convention’s submission deadline. Hallucinated or unverifiable references are discarded. The verified citations are compiled right into a BibTeX file, and the agent makes use of them to draft the Introduction and Associated Work sections — with a tough constraint that no less than 90% of the gathered literature pool should be actively cited.
Step 4 — Part Writing Agent: This agent takes every thing generated to date — the define, the verified citations, the generated figures — and authors the remaining sections: summary, methodology, experiments, and conclusion. It extracts numeric values straight from the experimental log to assemble tables and integrates the generated figures into the LaTeX supply.
Step 5 — Content material Refinement Agent: Utilizing AgentReview, a simulated peer-review system, this agent iteratively optimizes the manuscript. After every revision, the manuscript is accepted provided that the general AgentReview rating will increase, or ties with internet non-negative sub-axis positive aspects. Any total rating lower triggers a direct revert and halt. Ablation outcomes present this step is essential: refined manuscripts dominate unrefined drafts with 79%–81% win charges in automated side-by-side comparisons, and ship absolute acceptance fee positive aspects of +19% on CVPR and +22% on ICLR in AgentReview simulations.
The complete pipeline makes roughly 60–70 LLM API calls and completes in a imply of 39.6 minutes per paper — solely about 4.5 minutes greater than AI Scientist-v2’s 35.1 minutes, regardless of working considerably extra LLM calls (40–45 for AI Scientist-v2 vs. 60–70 for PaperOrchestra).
The Benchmark: PaperWritingBench
The analysis crew additionally introduce PaperWritingBench, described as the primary standardized benchmark particularly for AI analysis paper writing. It comprises 200 accepted papers from CVPR 2025 and ICLR 2025 (100 from every venue), chosen to check adaptation to completely different convention codecs — double-column for CVPR versus single-column for ICLR.
For every paper, an LLM was used to reverse-engineer two inputs from the revealed PDF: a Sparse Thought Abstract (high-level conceptual description, no math or LaTeX) and a Dense Thought Abstract (retaining formal definitions, loss features, and LaTeX equations), alongside an Experimental Log derived by extracting all numeric knowledge and changing determine insights into standalone factual observations. All supplies have been absolutely anonymized, stripping writer names, titles, citations, and determine references.
This design isolates the writing activity from any particular experimental pipeline, utilizing actual accepted papers as floor fact — and it reveals one thing vital. For Total Paper High quality, the Dense concept setting considerably outperforms Sparse (43%–56% win charges vs. 18%–24%), since extra exact methodology descriptions allow extra rigorous part writing. However for Literature Evaluate High quality, the 2 settings are almost equal (Sparse: 32%–40%, Dense: 28%–39%), which means the Literature Evaluate Agent can autonomously establish analysis gaps and related citations with out counting on detail-heavy human inputs.
The Outcomes
In automated side-by-side (SxS) evaluations utilizing each Gemini-3.1-Professional and GPT-5 as choose fashions, PaperOrchestra dominated on literature evaluate high quality, reaching absolute win margins of 88%–99% over AI baselines. For total paper high quality, it outperformed AI Scientist-v2 by 39%–86% and the Single Agent by 52%–88% throughout all settings.
Human analysis — performed with 11 AI researchers throughout 180 paired manuscript comparisons — confirmed the automated outcomes. PaperOrchestra achieved absolute win fee margins of 50%–68% over AI baselines in literature evaluate high quality, and 14%–38% in total manuscript high quality. It additionally achieved a 43% tie/win fee in opposition to the human-written floor fact in literature synthesis — a notable outcome for a totally automated system.
The quotation protection numbers inform a very clear story. AI baselines averaged solely 9.75–14.18 citations per paper, inflating their F1 scores on the must-cite (P0) reference class whereas leaving “good-to-cite” (P1) recall close to zero. PaperOrchestra generated a mean of 45.73–47.98 citations, intently mirroring the ~59 citations present in human-written papers, and improved P1 Recall by 12.59%–13.75% over the strongest baselines.
Beneath the ScholarPeer analysis framework, PaperOrchestra achieved simulated acceptance charges of 84% on CVPR and 81% on ICLR, in comparison with human-authored floor fact charges of 86% and 94% respectively. It outperformed the strongest autonomous baseline by absolute acceptance positive aspects of 13% on CVPR and 9% on ICLR.
Notably, even when PaperOrchestra generates its personal figures autonomously from scratch (PlotOn mode) quite than utilizing human-authored figures (PlotOff mode), it achieves ties or wins in 51%–66% of side-by-side matchups — regardless of PlotOff having an inherent data benefit since human-authored figures typically embed supplementary outcomes not current within the uncooked experimental logs.
Key Takeaways
- It’s a standalone author, not a analysis bot. PaperOrchestra is particularly designed to work with your supplies — a tough concept abstract and uncooked experimental logs — without having to run experiments itself. It is a direct repair to the most important limitation of current programs like AI Scientist-v2, which solely write papers as a part of their very own inner analysis loops.
- Quotation high quality, not simply quotation rely, is the true differentiator. Competing programs averaged 9–14 citations per paper, which sounds acceptable till you notice they have been virtually totally “must-cite” apparent references. PaperOrchestra averaged 45–48 citations per paper, matching human-written papers (~59), and dramatically improved protection of the broader tutorial panorama — the “good-to-cite” references that sign real scholarly depth.
- Multi-agent specialization persistently beats single-agent prompting. The Single Agent baseline — one monolithic LLM name given all the identical uncooked supplies — was outperformed by PaperOrchestra by 52%–88% in total paper high quality. The framework’s 5 specialised brokers, parallel execution, and iterative refinement loop are doing work that no single immediate, no matter high quality, can replicate.
- The Content material Refinement Agent will not be elective. Ablations present that eradicating the iterative peer-review loop causes a dramatic high quality drop. Refined manuscripts beat unrefined drafts 79%–81% of the time in side-by-side comparisons, with simulated acceptance charges leaping +19% on CVPR and +22% on ICLR. This step alone is chargeable for elevating a purposeful draft into one thing submission-ready.
- Human researchers are nonetheless within the loop — and should be. The system explicitly can’t fabricate new experimental outcomes, and its refinement agent is instructed to disregard reviewer requests for knowledge that doesn’t exist within the experimental log. The authors place PaperOrchestra as a complicated assistive software, with human researchers retaining full accountability for accuracy, originality, and validity of the ultimate manuscript.
Try the Paper and Challenge Web page. Additionally, be happy to observe us on Twitter and don’t neglect to hitch our 120k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as nicely.
Must accomplice with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and so on.? Join with us

