

What number of occasions have you ever spent months evaluating automation initiatives – enduring a number of vendor assessments, navigating prolonged RFPs, and managing advanced procurement cycles – solely to face underwhelming outcomes or outright failure? You’re not alone.
Many enterprises battle to scale automation, not resulting from an absence of instruments, however as a result of their information isn’t prepared. In principle, AI brokers and RPA bots may deal with numerous duties; in follow, they fail when fed messy or unstructured inputs. Research present that 80%-90% of all enterprise information is unstructured – consider emails, PDFs, invoices, photographs, audio, and many others. This pervasive unstructured information is the actual bottleneck. Irrespective of how superior your automation platform, it will possibly’t reliably course of what it can’t correctly learn or perceive. In brief, low automation ranges are normally a knowledge downside, not a device downside.
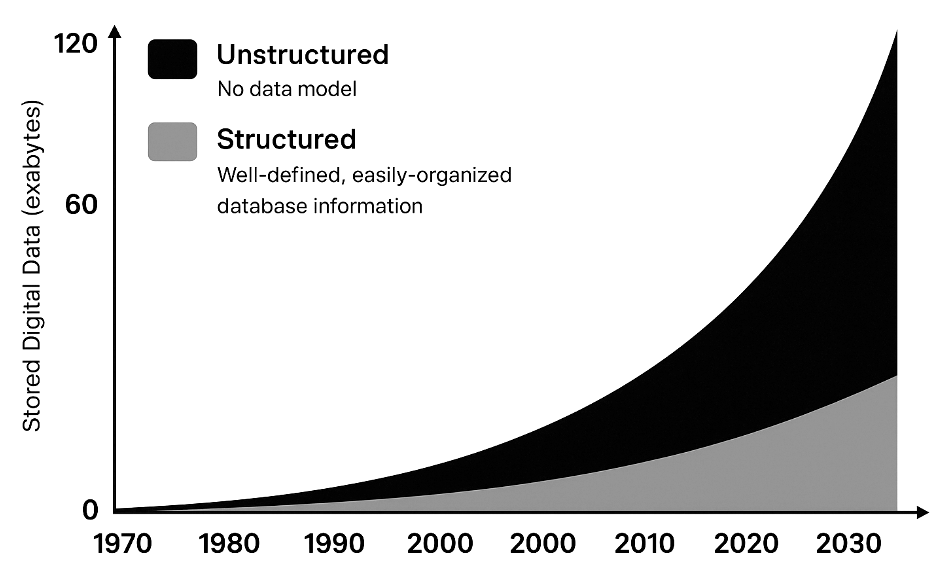
Why Brokers and RPA Require Structured Information
Automation instruments like Robotic Course of Automation (RPA) excel with structured, predictable information – neatly organized in databases, spreadsheets, or standardized kinds. They falter with unstructured inputs. A typical RPA bot is basically a rules-based engine (“digital employee”) that follows express directions. If the enter is a scanned doc or a free-form textual content subject, the bot doesn’t inherently know interpret it. RPA is unable to immediately handle unstructured datasets; the information should first be transformed into structured kind utilizing further strategies. In different phrases, an RPA bot wants a clear desk of information, not a pile of paperwork.
“RPA is handiest when processes contain structured, predictable information. In follow, many enterprise paperwork corresponding to invoices are unstructured or semi-structured, making automated processing troublesome”. Unstructured information now accounts for ~80% of enterprise information, underscoring why many RPA initiatives stall.
The identical holds true for AI brokers and workflow automation: they solely carry out in addition to the information they obtain. If an AI customer support agent is drawing solutions from disorganized logs and unlabeled information, it’ll seemingly give fallacious solutions. The inspiration of any profitable automation or AI agent is “AI-ready” information that’s clear, well-organized, and ideally structured. Because of this organizations that make investments closely in instruments however neglect information preparation typically see disappointing automation ROI.
Challenges with Conventional Information Structuring Strategies
If unstructured information is the difficulty, why not simply convert it to structured kind? That is simpler stated than executed. Conventional strategies to construction information like OCR, ICR, and ETL have vital challenges:
- OCR and ICR: OCR and ICR have lengthy been used to digitize paperwork, however they crumble in real-world situations. Basic OCR is simply pattern-matching, it struggles with diverse fonts, layouts, tables, photographs, or signatures. Even high engines hit solely 80 – 90% accuracy on semi-structured docs, creating 1,000 – 2,000 errors per 10,000 paperwork and forcing handbook overview on 60%+ of information. Handwriting makes it worse, ICR barely manages 65 – 75% accuracy on cursive. Most programs are additionally template-based, demanding countless rule updates for each new bill or kind format.OCR/ICR can pull textual content, nevertheless it can’t perceive context or construction at scale, making them unreliable for enterprise automation.
- Standard ETL Pipelines: ETL works nice for structured databases however falls aside with unstructured information. No fastened schema, excessive variability, and messy inputs imply conventional ETL instruments want heavy customized scripting to parse pure language or photographs. The consequence? Errors, duplicates, and inconsistencies pile up, forcing information engineers to spend 80% of their time cleansing and prepping information—leaving solely 20% for precise evaluation or AI modeling. ETL was constructed for rows and columns, not for at the moment’s messy, unstructured information lakes—slowing automation and AI adoption considerably.
- Rule-Based mostly Approaches: Older automation options typically tried to deal with unstructured information with brute-force guidelines, e.g. utilizing regex patterns to seek out key phrases in textual content, or establishing determination guidelines for sure doc layouts. These approaches are extraordinarily brittle. The second the enter varies from what was anticipated, the principles fail. Consequently, firms find yourself with fragile pipelines that break every time a vendor modifications an bill format or a brand new textual content sample seems. Upkeep of those rule programs turns into a heavy burden.
All these elements contribute to why so many organizations nonetheless depend on armies of information entry workers or handbook overview. McKinsey observes that present doc extraction instruments are sometimes “cumbersome to arrange” and fail to yield excessive accuracy over time, forcing firms to take a position closely in handbook exception dealing with. In different phrases, regardless of utilizing OCR or ETL, you find yourself with folks within the loop to repair all of the issues the automation couldn’t determine. This not solely cuts into the effectivity beneficial properties but additionally dampens worker enthusiasm (since employees are caught correcting machine errors or doing low-value information clean-up). It’s a irritating establishment: automation tech exists, however with out clear, structured information, its potential is rarely realized.
Foundational LLMs Are Not a Silver Bullet for Unstructured Information
With the rise of huge language fashions, one would possibly hope that they might merely “learn” all of the unstructured information and magically output structured information. Certainly, fashionable basis fashions (like GPT-4) are excellent at understanding language and even deciphering photographs. Nonetheless, general-purpose LLMs are usually not purpose-built to resolve the enterprise unstructured information downside of scale, accuracy, and integration. There are a number of causes for this:
- Scale Limitations: Out-of-the-box LLMs can’t ingest tens of millions of paperwork or complete information lakes in a single go. Enterprise information typically spans terabytes, far past an LLM’s capability at any given time. Chunking the information into smaller items helps, however then the mannequin loses the “large image” and might simply combine up or miss particulars. LLMs are additionally comparatively gradual and computationally costly for processing very massive volumes of textual content. Utilizing them naively to parse each doc can develop into cost-prohibitive and latency-prone.
- Lack of Reliability and Construction: LLMs generate outputs probabilistically, which suggests they might “hallucinate” info or fill in gaps with plausible-sounding however incorrect information. For essential fields (like an bill whole or a date), you want 100% precision, a made-up worth is unacceptable. Foundational LLMs don’t assure constant, structured output except closely constrained. They don’t inherently know which elements of a doc are essential or correspond to which subject labels (except educated or prompted in a really particular means). As one analysis research famous, “sole reliance on LLMs will not be viable for a lot of RPA use instances” as a result of they’re costly to coach, require a number of information, and are susceptible to errors/hallucinations with out human oversight. In essence, a chatty basic AI would possibly summarize an electronic mail for you, however trusting it to extract each bill line merchandise with excellent accuracy, each time, is dangerous.
- Not Skilled on Your Information: By default, basis fashions be taught from internet-scale textual content (books, internet pages, and many others.), not out of your firm’s proprietary kinds and vocabulary. They might not perceive particular jargon on a kind, or the structure conventions of your trade’s paperwork. Advantageous-tuning them in your information is feasible however expensive and complicated, and even then, they continue to be generalists, not specialists in doc processing. As a Forbes Tech Council perception put it, an LLM by itself “doesn’t know your organization’s information” and lacks the context of inner data. You typically want further programs (like retrieval-augmented era, information graphs, and many others.) to floor the LLM in your precise information, successfully including again a structured layer.
In abstract, basis fashions are highly effective, however they don’t seem to be a plug-and-play answer for parsing all enterprise unstructured information into neat rows and columns. They increase however don’t exchange the necessity for clever information pipelines. Gartner analysts have additionally cautioned that many organizations aren’t even able to leverage GenAI on their unstructured information resulting from governance and high quality points, utilizing LLMs with out fixing the underlying information is placing the cart earlier than the horse.
Structuring Unstructured Information, Why Function-Constructed Fashions are the reply
Right this moment, Gartner and different main analysts point out a transparent shift: conventional IDP, OCR, and ICR options have gotten out of date, changed by superior massive language fashions (LLMs) which might be fine-tuned particularly for information extraction duties. In contrast to their predecessors, these purpose-built LLMs excel at deciphering the context of various and complicated paperwork with out the constraints of static templates or restricted sample matching.
Advantageous-tuned, data-extraction-focused LLMs leverage deep studying to grasp doc context, acknowledge refined variations in construction, and constantly output high-quality, structured information. They will classify paperwork, extract particular fields—corresponding to contract numbers, buyer names, coverage particulars, dates, and transaction quantities—and validate extracted information with excessive accuracy, even from handwriting, low-quality scans, or unfamiliar layouts. Crucially, these fashions regularly be taught and enhance via processing extra examples, considerably lowering the necessity for ongoing human intervention.
McKinsey notes that organizations adopting these LLM-driven options see substantial enhancements in accuracy, scalability, and operational effectivity in comparison with conventional OCR/ICR strategies. By integrating seamlessly into enterprise workflows, these superior LLM-based extraction programs permit RPA bots, AI brokers, and automation pipelines to perform successfully on the beforehand inaccessible 80% of unstructured enterprise information.
Consequently, trade leaders emphasize that enterprises should pivot towards fine-tuned, extraction-optimized LLMs as a central pillar of their information technique. Treating unstructured information with the identical rigor as structured information via these superior fashions unlocks vital worth, lastly enabling true end-to-end automation and realizing the complete potential of GenAI applied sciences.
Actual-World Examples: Enterprises Tackling Unstructured Information with Nanonets
How are main enterprises fixing their unstructured information challenges at the moment? Various forward-thinking firms have deployed AI-driven doc processing platforms like Nanonets to nice success. These examples illustrate that with the proper instruments (and information mindset), even legacy, paper-heavy processes can develop into streamlined and autonomous:
- Asian Paints (Manufacturing): One of many largest paint firms on the planet, Asian Paints handled hundreds of vendor invoices and buy orders. They used Nanonets to automate their bill processing workflow, reaching a 90% discount in processing time for Accounts Payable. This translated to releasing up about 192 hours of handbook work per 30 days for his or her finance group. The AI mannequin extracts all key fields from invoices and integrates with their ERP, so workers now not spend time typing in particulars or correcting errors.
- JTI (Japan Tobacco Worldwide) – Ukraine operations: JTI’s regional group confronted a really lengthy tax refund declare course of that concerned shuffling massive quantities of paperwork between departments and authorities portals. After implementing Nanonets, they introduced the turnaround time down from 24 weeks to simply 1 week, a 96% enchancment in effectivity. What was a multi-month ordeal of information entry and verification turned a largely automated pipeline, dramatically dashing up money circulation from tax refunds.
- Suzano (Pulp & Paper Trade): Suzano, a world pulp and paper producer, processes buy orders from numerous worldwide purchasers. By integrating Nanonets into their order administration, they diminished the time taken per buy order from about 8 minutes to 48 seconds, roughly a 90% time discount in dealing with every order. This was achieved by mechanically studying incoming buy paperwork (which arrive in several codecs) and populating their system with the wanted information. The result’s sooner order achievement and fewer handbook workload.
- SaltPay (Fintech): SaltPay wanted to handle an enormous community of 100,000+ distributors, every submitting invoices in several codecs. Nanonets allowed SaltPay to simplify vendor bill administration, reportedly saving 99% of the time beforehand spent on this course of. What was as soon as an amazing, error-prone job is now dealt with by AI with minimal oversight.
These instances underscore a typical theme: organizations that leverage AI-driven information extraction can supercharge their automation efforts. They not solely save time and labor prices but additionally enhance accuracy (e.g. one case famous 99% accuracy achieved in information extraction) and scalability. Staff will be redeployed to extra strategic work as an alternative of typing or verifying information all day. The expertise (instruments) wasn’t the differentiator right here, the important thing was getting the information pipeline so as with the assistance of specialised AI fashions. As soon as the information turned accessible and clear, the prevailing automation instruments (workflows, RPA bots, analytics, and many others.) may lastly ship full worth.
Clear Information Pipelines: The Basis of the Autonomous Enterprise
Within the pursuit of a “actually autonomous enterprise”, the place processes run with minimal human intervention – having a clear, well-structured information pipeline is completely essential. A “actually autonomous enterprise” doesn’t simply want higher instruments—it wants higher information. Automation and AI are solely pretty much as good as the data they devour, and when that gasoline is messy or unstructured, the engine sputters. Rubbish in, rubbish out is the only greatest motive automation initiatives underdeliver.
Ahead-thinking leaders now deal with information readiness as a prerequisite, not an afterthought. Many enterprises spend 2 – 3 months upfront cleansing and organizing information earlier than AI initiatives as a result of skipping this step results in poor outcomes. A clear information pipeline—the place uncooked inputs like paperwork, sensor feeds, and buyer queries are systematically collected, cleansed, and reworked right into a single supply of fact—is the inspiration that permits automation to scale seamlessly. As soon as that is in place, new use instances can plug into current information streams with out reinventing the wheel.
In distinction, organizations with siloed, inconsistent information stay trapped in partial automation, continually counting on people to patch gaps and repair errors. True autonomy requires clear, constant, and accessible information throughout the enterprise—very similar to self-driving vehicles want correct roads earlier than they will function at scale.
The takeaway: The instruments for automation are extra highly effective than ever, nevertheless it’s the information that determines success. AI and RPA don’t fail resulting from lack of functionality; they fail resulting from lack of fresh, structured information. Resolve that, and the trail to the autonomous enterprise—and the subsequent wave of productiveness—opens up.
Sources:

