
The Download: Claude’s inner workings, and the future of world models
Artificial Intelligence · July 14, 2026
Retrieval is critical in AI agents. To do any task correctly, the agent needs to be able to retrieve all the information that is relevant to the task from its memory.
Context graphs are all the rage right now, so I benchmarked them against the alternatives.
This post explains how each memory method works, what the benchmark asks, what the data is, and what each method got right and wrong.
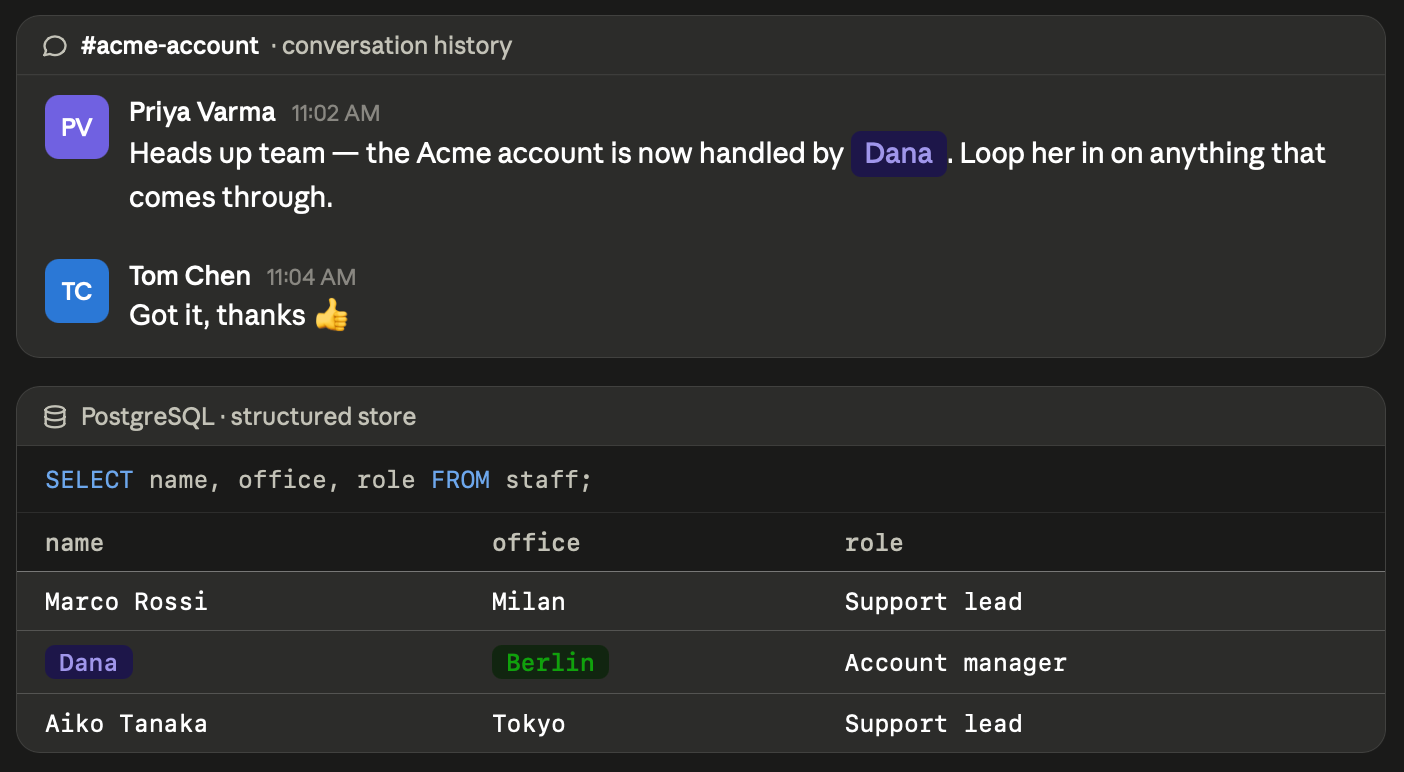
One of our clients came to us after their in-house agent kept dropping facts. A sales-support agent which needs to know "which office handles our Acme account?" to do a task. It couldn't answer this.
The agent had everything it needed for answering this in its memory. Full conversation histories, vector databases on top, the lot. Someone had already noted that the Acme account is handled by Dana. Somewhere else, a PostgreSQL row noted that Dana works out of the Berlin office.
Both facts were sitting right there but the agent failed to retrieve them and put two and two together.
To correctly retrieve and get the answer, the agent's retrieval method had to join two facts that were never said in the same breath, and nothing in the agent's standard memory setup did that on its own.
A context graph is built to fix these failures.
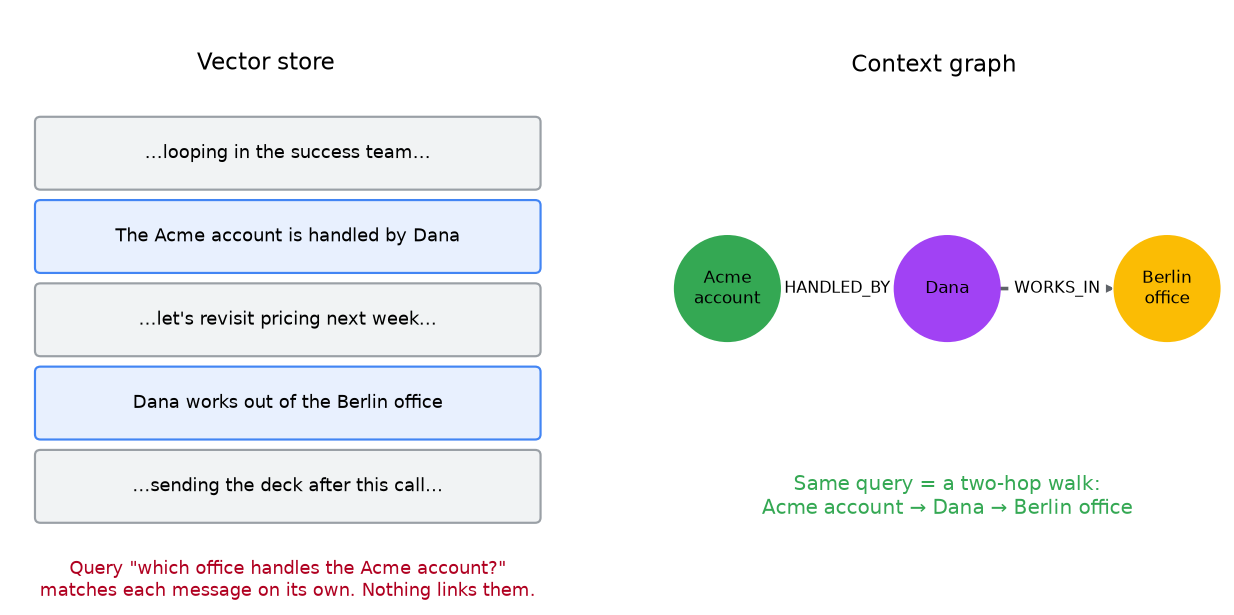
Here are two facts an agent might ingest in its memory, days apart:
The Acme account is handled by Dana.
Dana works out of the Berlin office.
Now the question is: "Which office handles the Acme account?"
No single message answers it. You have to chain two facts that were never said together. This is called a multi-hop question, because the answer is two hops away: the Acme account, to Dana, to the Berlin office.
I tested four ways to give an agent memory. Hold the above example in your head, I'll use it to walk through how each memory method works. When I get to the benchmark I'll switch to the data I actually run (software agents coordinating on work).
If you already know about these retrieval methods, skip to the benchmark.
The simplest possible memory where you dump everything, including the conversation histories and PostgreSQL dbs, in the memory. The model reads this text dump to answer the question.
Obvious issues with this method that don't need a benchmark to understand -
This is the standard production method today. "RAG" is retrieval-augmented generation: instead of sending everything, you try to retrieve only the relevant bits from the memory and send those to the LLM.
This is genuinely powerful. It shrugs off wording. Ask who "looks after" an account and it finds who it's "handled by." And the cost is flat: you always send the same small handful of messages, no matter how long the history gets.
But notice what it does for the account question. It scores each message against your question on its own.
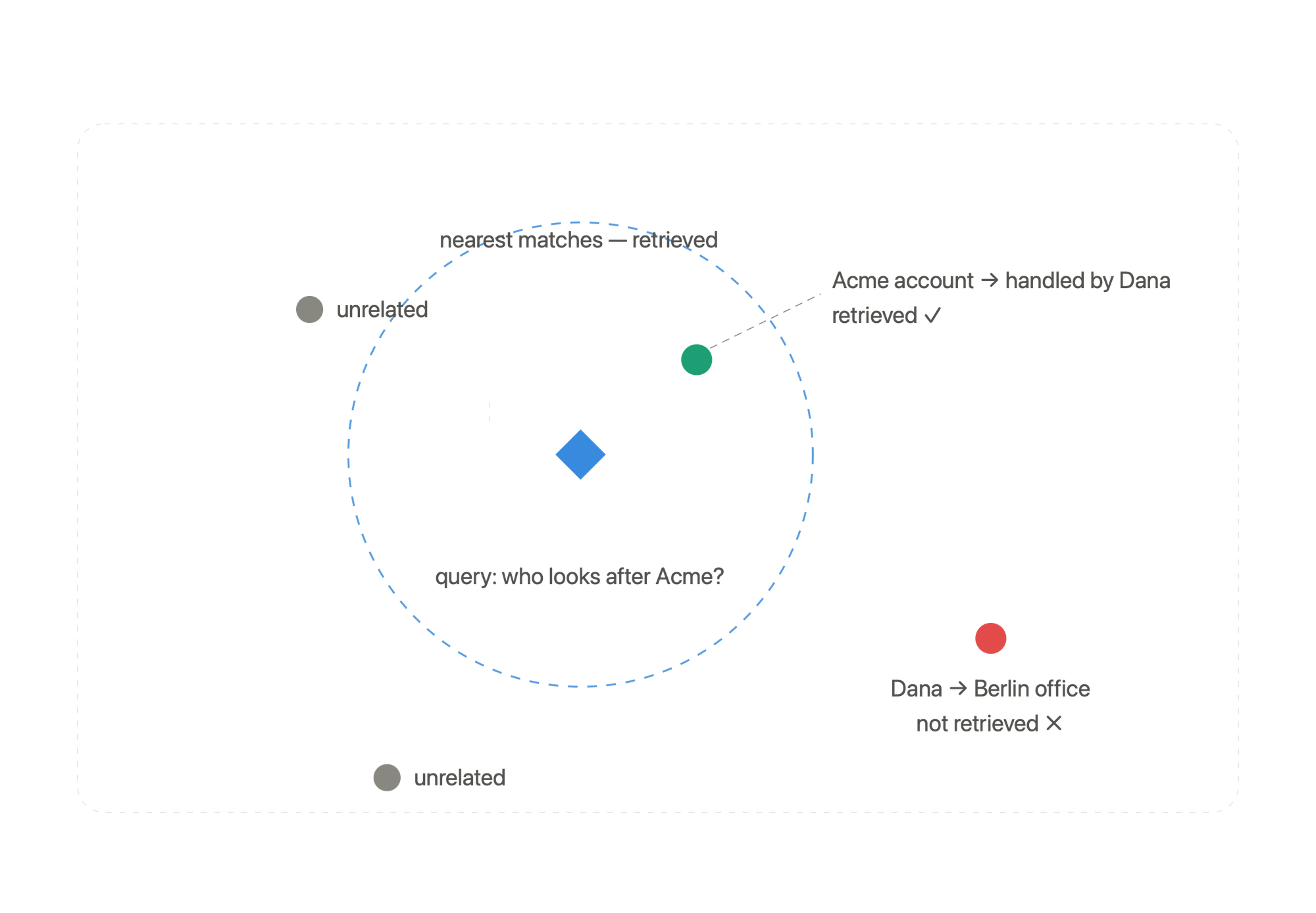
So the second fact, the one you actually need for the office, often doesn't get retrieved. Standard vector search ranks facts one at a time. It has no way to say "fetch this fact, then follow it to the next one." And better embeddings won't fix this.
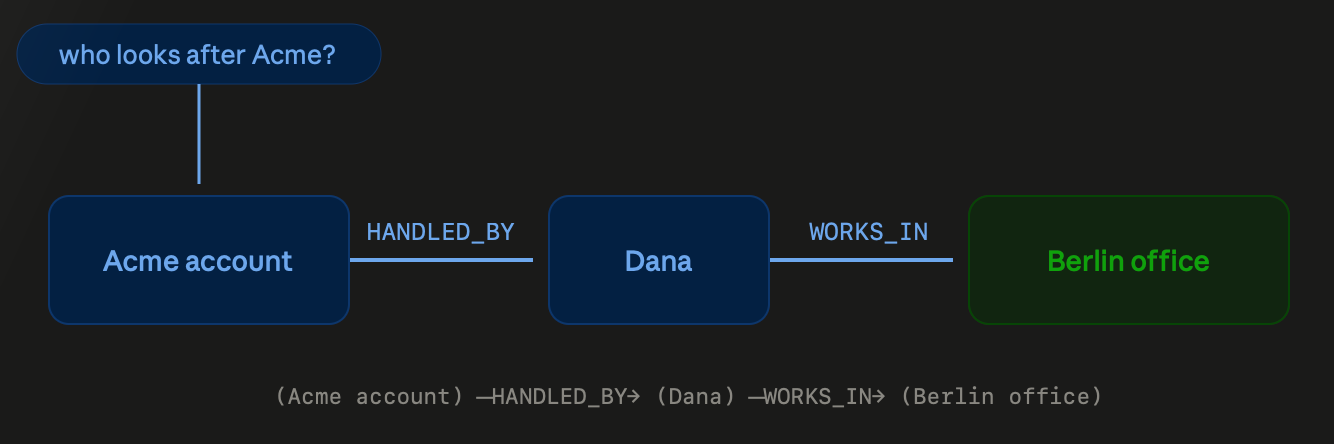
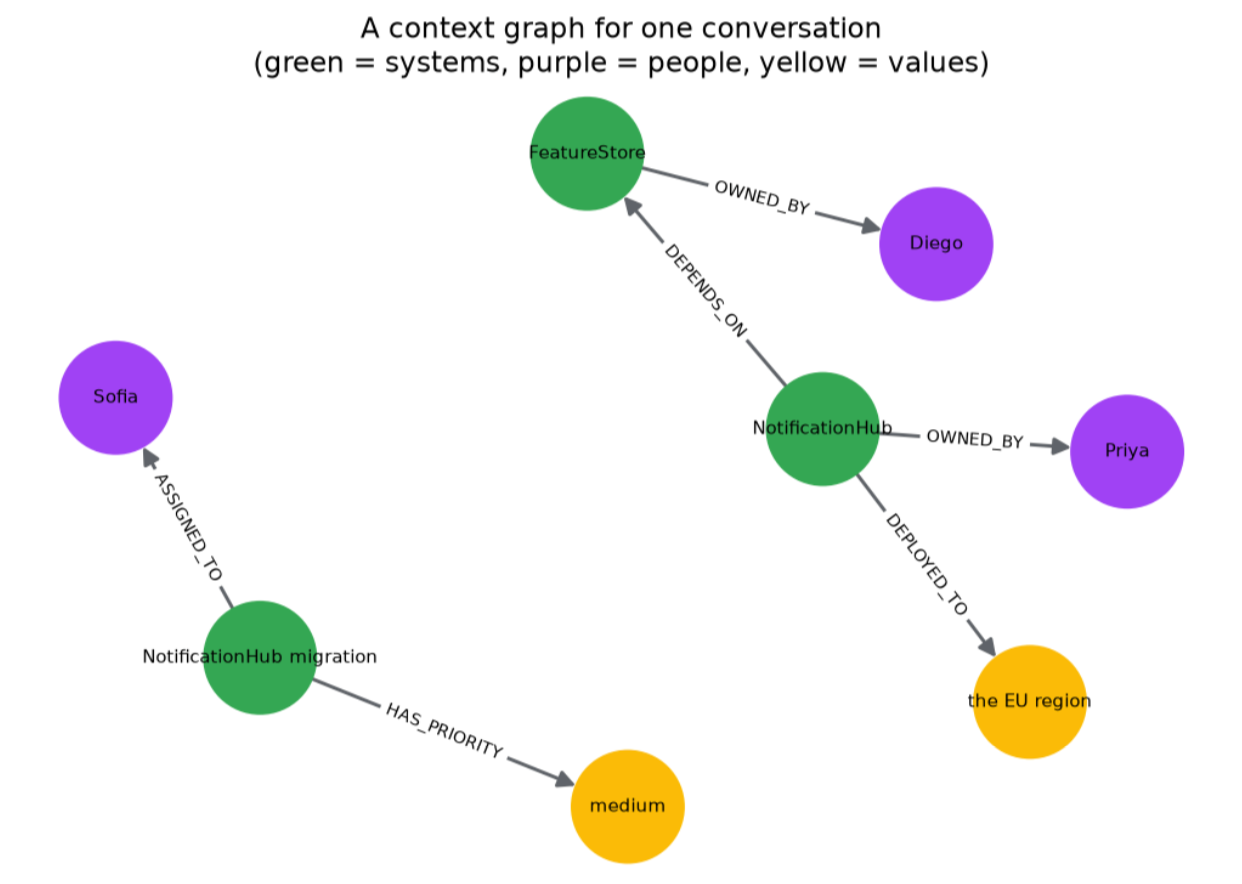
In a context graph, you stop storing the text directly, and instead store the facts extracted from the text as a graph.
A graph is nodes connected by edges. Each node becomes an entity, each edge becomes a relationship between entities. When the conversation histories and PostgresSQL dbs are ingested into a context graph memory, the two account facts would be saved as follows:
(Acme account) --HANDLED_BY--> (Dana)
(Dana) --WORKS_IN--> (Berlin office)
Now the multi-hop question is a walk in this graph. Start at the Acme account, follow the HANDLED_BY edge to Dana, follow the WORKS_IN edge to the Berlin office. Two hops to get the exact answer. The graph does natively what vector search can't: it follows one fact to the next.
Two more advantages here -
The difficult, as you may have already sensed, is that to build the graph you first have to turn messy sentences into clean triples, and you need to do this well.
I added a hybrid method that made sense, where I use the graph when it works, and fall back to vectors when it doesn't.
Let's leave our running example behind here.
I ran two benchmarks, one where I created a synthetic dataset myself, and another where I used the LoCoMo dataset.
I'll start with the synthetic dataset. Each test is on scripted conversations in one of three Slack channels: software, customer account management, ad hoc projects. A few real facts get scattered through dozens of filler messages ("sounds good, syncing after standup", "did the nightly build pass?"). Then the benchmark asks questions and checks the answer against the known truth.
3 Slack channel types × 12 scenarios/seed × 5 seeds = 60 conversations. 6 tests on each conversation = 360 tests (60 per test type).
Example conversation: infra_s0_0 (54 turns)
0 agent_b: Sprint planning moved to Thursday.
1 agent_c: The demo went fine, no blockers.
2 agent_b: FeatureStore is owned by Lena. <-- FACT
3 agent_a: Logs look clean on my end.
4 agent_c: The demo went fine, no blockers.
5 agent_b: Can someone re-run the flaky test?
6 agent_c: Grabbing coffee, back in five.
7 agent_c: Heads up, CI is slow today.
8 agent_b: Lena is on the Trust team. <-- FACT
9 agent_a: I'll open a ticket for that later.
10 agent_b: Heads up, CI is slow today.
11 agent_c: Sprint planning moved to Thursday.
12 agent_c: Cache hit rate looks healthy.
13 agent_b: Logs look clean on my end.
14 agent_a: Sounds good, I'll sync after standup.
15 agent_a: No update from the vendor yet.
16 agent_c: Sounds good, I'll sync after standup.
17 agent_b: ReportingAPI is set to high priority. <-- FACT
18 agent_a: Heads up, CI is slow today.
19 agent_c: Grabbing coffee, back in five.
20 agent_a: Thanks for the review earlier.
21 agent_a: The demo went fine, no blockers.
22 agent_c: Bumping the memory limit on that pod.
23 agent_a: Grabbing coffee, back in five.
24 agent_b: IngestWorker, which loads incoming events, depends on ConfigService. <-- FACT
25 agent_b: Can someone re-run the flaky test?
26 agent_b: Let's circle back next week.
27 agent_c: Can someone re-run the flaky test?
28 agent_c: Heads up, CI is slow today.
29 agent_c: Sprint planning moved to Thursday.
30 agent_c: Let's circle back next week.
31 agent_b: Grabbing coffee, back in five.
32 agent_c: No update from the vendor yet.
33 agent_b: ConfigService is owned by Sara. <-- FACT
34 agent_a: Let's circle back next week.
35 agent_a: Sprint planning moved to Thursday.
36 agent_a: Did the nightly build pass?
37 agent_c: Logs look clean on my end.
38 agent_b: Grabbing coffee, back in five.
39 agent_a: The demo went fine, no blockers.
40 agent_a: Did the nightly build pass?
41 agent_a: No update from the vendor yet.
42 agent_b: Update: ReportingAPI is now medium priority. <-- FACT (supersedes turn 17)
43 agent_a: Sprint planning moved to Thursday.
44 agent_c: Quick question about the staging config.
45 agent_c: Logs look clean on my end.
46 agent_b: Cache hit rate looks healthy.
47 agent_c: I'll open a ticket for that later.
48 agent_a: Heads up, CI is slow today.
49 agent_c: Can someone re-run the flaky test?
50 agent_b: Heads up, CI is slow today.
51 agent_a: Decision: ReportingAPI, which serves usage reports, depends on FeatureStore. <-- FACT
52 agent_a: Sounds good, I'll sync after standup.
53 agent_c: Logs look clean on my end.All code, data, results are in this repository.
I built six question types -
Accuracy by question type:
| Method | Direct | Distant | Join | Multi-hop | Update | Paraphrase | Overall |
|---|---|---|---|---|---|---|---|
| Raw dump | 100% | 100% | 33% | 33% | 100% | 0% | 61% |
| Vector RAG | 100% | 100% | 7% | 0% | 63% | 100% | 62% |
| Context graph | 100% | 100% | 100% | 100% | 100% | 0% | 83% |
| Hybrid | 100% | 100% | 100% | 100% | 100% | 100% | 100% |
Note: The hybrid's perfect 100% here is a ceiling and not a production number. It assumes perfect fact extraction which is what this synthetic benchmark hands every method.
| Question | Raw | Vector | Graph | Hybrid | Gold |
|---|---|---|---|---|---|
| Who owns FeatureStore? (direct) | Diego ✓ | Diego ✓ | Diego ✓ | Diego ✓ | Diego |
| Who owns NotificationHub? (distant) | Priya ✓ | Priya ✓ | Priya ✓ | Priya ✓ | Priya |
These are single facts, stated once. A real embedder finds them whether they were said one message ago or fifty. Distance alone is not the problem.
| Question: who owns the component NotificationHub depends on? | Answer | |
|---|---|---|
| Raw dump | Priya | ✗ |
| Vector RAG | Priya | ✗ |
| Context graph | Diego | ✓ |
| Hybrid | Diego | ✓ |
The trap here is that NotificationHub's own owner is Priya, so a method that can't do the second hop tends to answer Priya.
Look at the wrong answers. Raw dump and vector both said Priya, and that's revealing. Priya owns NotificationHub. They retrieved the fact about NotificationHub's owner and stopped. They couldn't take the second hop, from NotificationHub to its dependency FeatureStore to that component's owner.
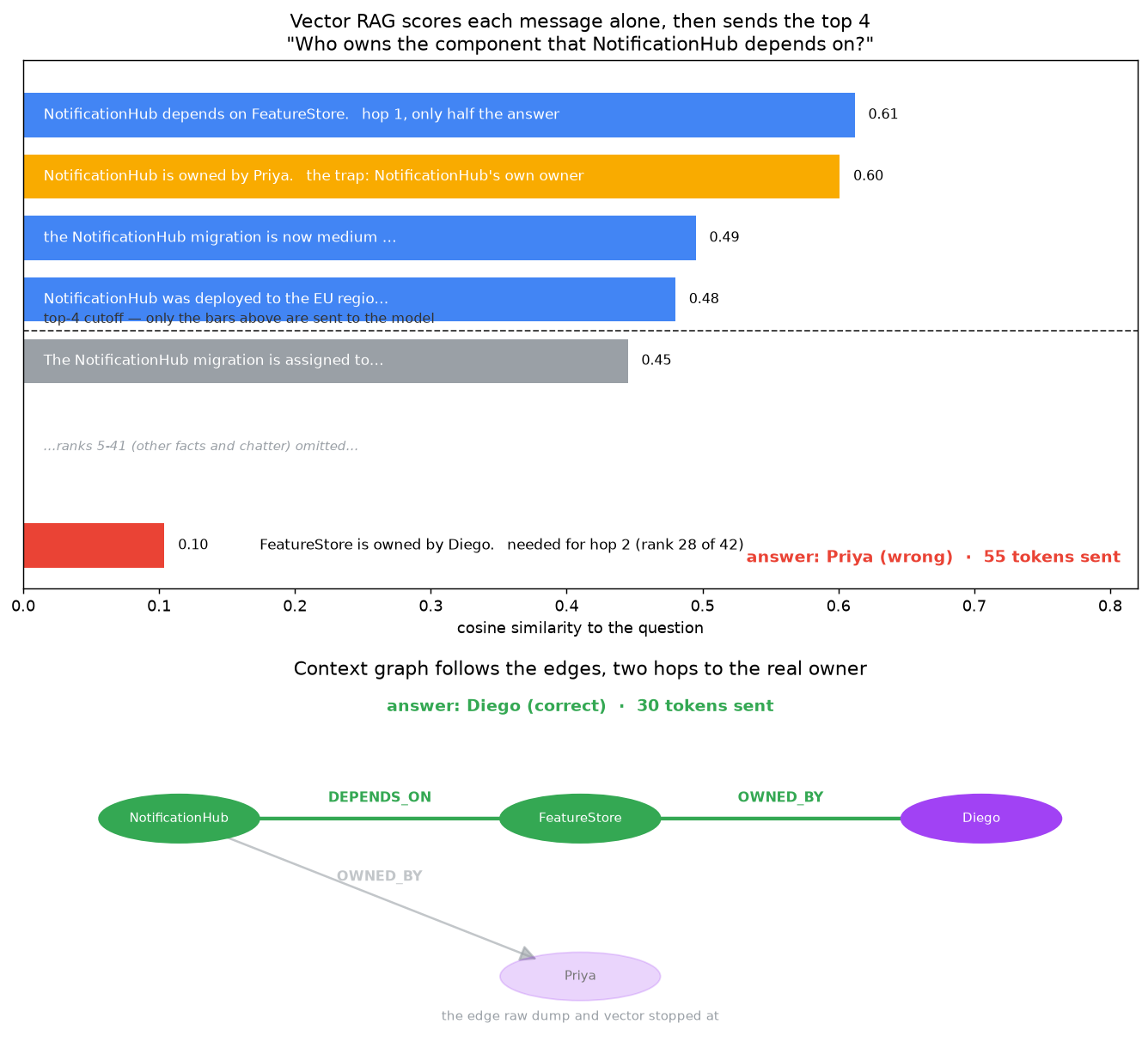
The needed fact, "FeatureStore is owned by Diego", doesn't mention NotificationHub, so vector RAG scores it low against a question about NotificationHub and never retrieves it.
The graph simply walked it: NotificationHub, DEPENDS_ON, FeatureStore, OWNED_BY, Diego.
| Question: which team owns the component ReportingAPI depends on? | Answer | |
|---|---|---|
| Raw dump | couldn't answer | ✗ |
| Vector RAG | couldn't answer | ✗ |
| Context graph | Trust | ✓ |
| Hybrid | Trust | ✓ |
Adding a third hop widens the gap. The answer needs three specific fact chains, ReportingAPI to FeatureStore, FeatureStore to Lena, Lena to Trust team. Only the first fact names ReportingAPI explicitly. Vector RAG manages 0% here, slightly worse than its 7% on the two-hop join. The graph just needs to take one more step along the edges, and thus scores 100%.
| Question: what priority is SearchIndexer now? | Answer | |
|---|---|---|
| Raw dump | critical | ✓ |
| Vector RAG | low | ✗ |
| Context graph | critical | ✓ |
| Hybrid | critical | ✓ |
SearchIndexer was set to low priority, then escalated to critical. Vector RAG returned low, the stale value. Both turns look almost identical to the question "what priority is it now".
Vector search has no sense of time, so can randomly pull the older message and answer with a fact that's no longer true. It scores 63% across the tests, right when retrieval happens to surface the newer turn, wrong when it grabs the stale one.
The graph gets it right by design. When the new priority arrived, it deleted the old edge before adding the new one, so the stale value is simply gone.
Raw dump got it right too, but by luck, not design. It always sees the most recent messages and recency happened to save it.
| Question: who is responsible for the alerts system? | Answer | |
|---|---|---|
| Raw dump | the EU region | ✗ |
| Vector RAG | Priya | ✓ |
| Context graph | (nothing) | ✗ |
| Hybrid | Priya | ✓ |
The graph returned nothing at all. "The alerts system" is NotificationHub, but the graph stores a node literally named "NotificationHub". It tried to match the words, found no node called "alerts system", and the walk never started. The context graph scores zero percent on paraphrase and this is its blind spot.
Vector search doesn't care what you call things. "Alerts system" and "NotificationHub, which handles outbound notifications" are close in meaning, so it found the right message and read off the owner.
Raw dump gave the funniest wrong answer: the EU region. It grabbed a recent NotificationHub fact, i.e. something about the deployment region, and returned that.
Here's what each method spends to answer one question, measured in tokens with the GPT-4 tokenizer:
| Method | Avg tokens per query | Overall accuracy |
|---|---|---|
| Raw dump | 477 | 60.0% |
| Vector RAG | 56 | 52.3% |
| Context graph | 15 | 80.0% |
| Hybrid | 26 | 92.3% |
Also, the raw dump's cost grows with the memory size, while the others stay flat. I held the facts fixed and padded the conversation with filler. At 800 turns the raw dump sends 13,623 tokens to answer one question. The graph sends 17, the same as it did at turn one and answers correctly:
| Conversation length | Raw dump | Vector RAG | Context graph | Hybrid |
|---|---|---|---|---|
| 2 turns | 23 | 23 | 17 | 17 |
| 50 turns | 873 | 57 | 17 | 17 |
| 200 turns | 3,423 | 57 | 17 | 17 |
| 400 turns | 6,823 | 57 | 17 | 17 |
| 800 turns | 13,623 | 57 | 17 | 17 |
Retrieval speed tells the same story. These are in-memory times in milliseconds, median per query:
| Method | Median retrieval latency (ms) |
|---|---|
| Raw dump | 0.038 |
| Vector RAG | 0.046 |
| Context graph | 0.005 |
| Hybrid | 0.004 |
The graph walks two edges while vector search embeds the question and scores it against every message, so traversal is the cheap operation. The hybrid's median is lowest because the graph answers most questions, and only the paraphrase misses pay the embedding cost.
Plain top-k is the naive baseline is vector RAG. Theoretically, you can also go for iterative / recursive retrieval. Take the test we say earlier where we asked "Who owns the component that ReportingAPI depends on?"
But this is inefficient. Why?
If implemented on the above benchmark, my guess is that recursive RAG closes some of the 2-hop join gap, costs noticeably more tokens, and still trails on the multi-hop case.
The graph owns joins and updates, and vectors own paraphrase, so one can just use both.
The hybrid asks the graph first and takes the answer if the walk succeeds. If the graph draws a blank, which on this benchmark means a paraphrased question, it falls back to vector search.
That one rule keeps every join and update the graph got right and recovers the paraphrases it dropped. It lands at 92.3% overall, for 26 tokens a query.
The pure graph, for all its multi-hop strength, sits at 80% because paraphrase drags it down. The lesson here was to bolt your context graph memory with methods that can answer paraphrase questions.
LoCoMo is a public dataset of ten very long conversations, ~600 turns each, with 1,982 human-written tests.
| Property | Value |
|---|---|
| Conversations | 10 |
| Messages total | 5,882 |
| Messages per conversation (avg) | 588 |
| Tests (with evidence) | 1,982 |
| Single-hop tests | 1,559 |
| Multi-hop tests | 423 |
In LoCoMo, each conversation is a long relationship between two people, split into multiple chat sessions (multiple chat sessions in a conversation happened days/weeks apart). Each chat session is a list of messages. For example, conversation_0 had 19 chat sessions with 419 total messages. The dia_id encodes it: D1:3 = chat session 1, message 3.
Single-hop (one evidence turn):
Q: "What was Melanie's favorite book from her childhood?" Answer: "Charlotte's Web" Evidence D6:10, Melanie: "I loved reading 'Charlotte's Web' as a kid. It was so cool seeing how friendship and compassion can make a difference."
Multi-hop (multiple evidence turns in multiple chat sessions):
Q: "What do Melanie's kids like?" Answer: dinosaurs, nature Evidence D6:6, Melanie: "They were stoked for the dinosaur exhibit! They love learning about animals..." Evidence D4:8, Melanie: "It was an awesome time! They love exploring nature, and they also roasted marshmallows around the campfire..."
The good thing was the dataset gave evidence labels in the test answers, which let me test this with no LLM at all.
Everything so far hands each method perfect, pre-extracted facts. That isolates retrieval, which is what I wanted to measure. But in production, an LLM has to read each memory ingestion request and pull out the triples.
The graph needs triples, so Claude Haiku reads the dialogue in batches and extracts them in a context graph.
def batch_extract(turns, batch=12):
triples = []
for chunk in batches(turns, batch):
text = "\n".join(f"[{t.speaker}] {t.text}" for t in chunk)
# "Extract relationships as JSON: [{subject, predicate, object}]"
triples += parse_json(claude(EXTRACT_PROMPT + text))
return triples # ~1 triple per turn on LoCoMo
Then I used the context graph to decide which messages to read (take the top triples, follow their entities one hop to the connected facts, map those facts back to the messages they came from), and hand the model those messages:
top = argsort(-(triple_vectors @ embed(question)))[:k] # top triples
seed = {s for s,p,o in top} | {o for s,p,o in top}
hood = rank_by_similarity(t for t in triples if t.subject in seed or t.object in seed)[:k]
turns = {provenance[t] for t in top + hood} # back to source messages
ctx = facts(top + hood) + "\n" + "\n".join(turn_text[i] for i in sorted(turns))
graph_answer = claude(f"Answer using only:\n{ctx}\n\nQ: {question}")Vector RAG embeds every raw turn and, per question, sends the top-k turns to Haiku to answer:
qv = embed(question)
top = argsort(-(turn_vectors @ qv))[:k] # top-k turns by cosine
ctx = "\n".join(turn_text[i] for i in top)
vector_answer = claude(f"Answer using only:\n{ctx}\n\nQ: {question}")A separate Claude Haiku call judges each answer against the truth. Here's how they landed:
| Question type | Vector RAG | Context graph |
|---|---|---|
| Single-hop (20 Q) | 20.0% | 45.0% |
| Multi-hop (6 Q) | 16.7% | 33.3% |
| All (26 Q) | 19.2% | 42.3% |
| Question Examples | Context graph | Vector RAG | Truth |
|---|---|---|---|
| When did Gina get her tattoo? | "A few years ago" ✓ | "Unknown" ✗ | A few years ago |
| For how long has Nate had his turtles? | "3 years" ✓ | "Unknown" ✗ | 3 years |
| What items did John mention having as a child? | "film camera and a little doll" ✓ | "Unknown" ✗ | a doll, a film camera |
| What do Jon and Gina have in common? | "lost their jobs, started a business" ✓ | "passion for dancing" ✗ | lost jobs, started own business |
In most of these tests, the answer lived in a turn that never made vector's top-25, but the context graph triples for it sat relatively closer to the question in the graph.
My point was to show the advantages that context graphs bring when used in AI agents. This is by no means a production grade implementation of context graphs, which tends to be a lot more technically rigorous.
What would move the context graph score above 42.3%?
There are many optimizations that production teams use to improve how they employ context graphs -
My context graph answers in two distinct steps:
The paraphrase failures happen entirely in step 1, before any traversal happens. In my benchmark the resolver (ContextGraphMemory._resolve) matches the mention to a node by lexical token overlap:
"the analytics endpoint" vs node "ReportingAPI" -> shared tokens: 0 -> no match
The graph isn't bad at the question; it just never gets to ask it.
But production systems make step 1 semantic, where you embed the node labels (or ask an LLM) and match "analytics endpoint" → "ReportingAPI, which serves usage reports" by meaning.
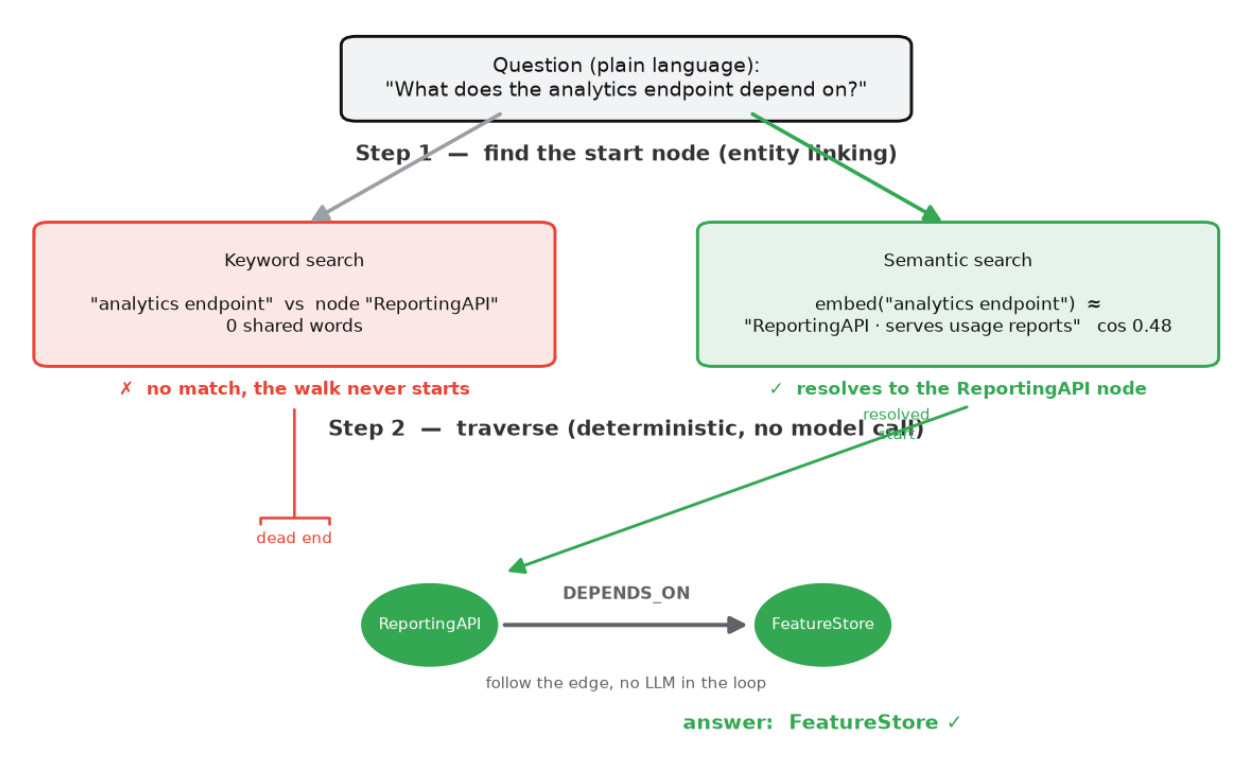
Instead of keyword search, we can use semantic search on the context graph to completely solve for the paraphrase tests and also do better on the LoCoMo dataset.
The graph is only ever as good as the triples you pull out of the text.
All of this costs model calls at ingestion. That is a cheap trade where you pay once per message, up front, so every later query stays cheap and correct. For an agent that answers many questions over a long history, that trade usually pays for itself.
A stronger model helps in two places, and they are not equally important.
At extraction, which is where it matters most. A more careful model reads a rambling message and pulls out more of the facts, with cleaner entities and fewer inventions. Extraction caps the whole score, so the model you extract with matters more than the one you answer with. Spend your budget upstream.
At answering, for the questions that aren't lookups. "Would Caroline pursue writing?" isn't stored anywhere. The model has to reason from what was. A stronger reader turns "here are the facts" into the right inference more often, and that is most of what's left once retrieval is solved.
Build a context graph when your agents run long, decisions made early have to survive many turns, and questions chain facts together. That's most multi-agent work.
Enterprises and startups use our agentic harnesses and context graphs to automate various processes, including ones with -
Procurement, finance, claims, deal desk, underwriting, escalation management are few examples.
Read more here.
You can skip it when conversations are short, or when questions are fuzzy and open-ended, the kind where you want semantic recall more than an exact walk. Note that graph adds an extraction cost you'll have incur and a vocabulary problem you'll need to fix.
The code, data, and every table here are reproducible from the repository.


