


Picture by Writer | Canva
# Introduction
Knowledge evaluation issues aren’t actually distinctive. Nonetheless, “although your issues are non-unique, that doesn’t make them go away,” to paraphrase Neil Younger. What’s going to make them go away? Realizing that, beneath the floor, most of them depend on a handful of reusable patterns.
I’ll present you these patterns, so you may then reuse them in your work or job interview, regardless of the info or trade. Knowledge is at all times simply that — information. All of the patterns will probably be in PostgreSQL primarily based on the coding interview questions on StrataScratch. Then I’ll tie them to actual enterprise conditions.

# 1. Joins + Filters: Discovering the Proper Subset
Query: Film Period Match from Amazon
Job: Growing a function that implies particular person motion pictures from Amazon’s content material database that match inside a given flight’s period.
For flight 101, discover motion pictures whose runtime is lower than or equal to the flight’s period. The output ought to checklist prompt motion pictures for the flight, together with flight_id, movie_id, and movie_duration.
Resolution:
SELECT fs.flight_id,
ec.movie_id,
ec.period AS movie_duration
FROM flight_schedule fs
JOIN entertainment_catalog ec ON ec.period <= fs.flight_duration
WHERE fs.flight_id = 101
ORDER BY ec.period;
Output:
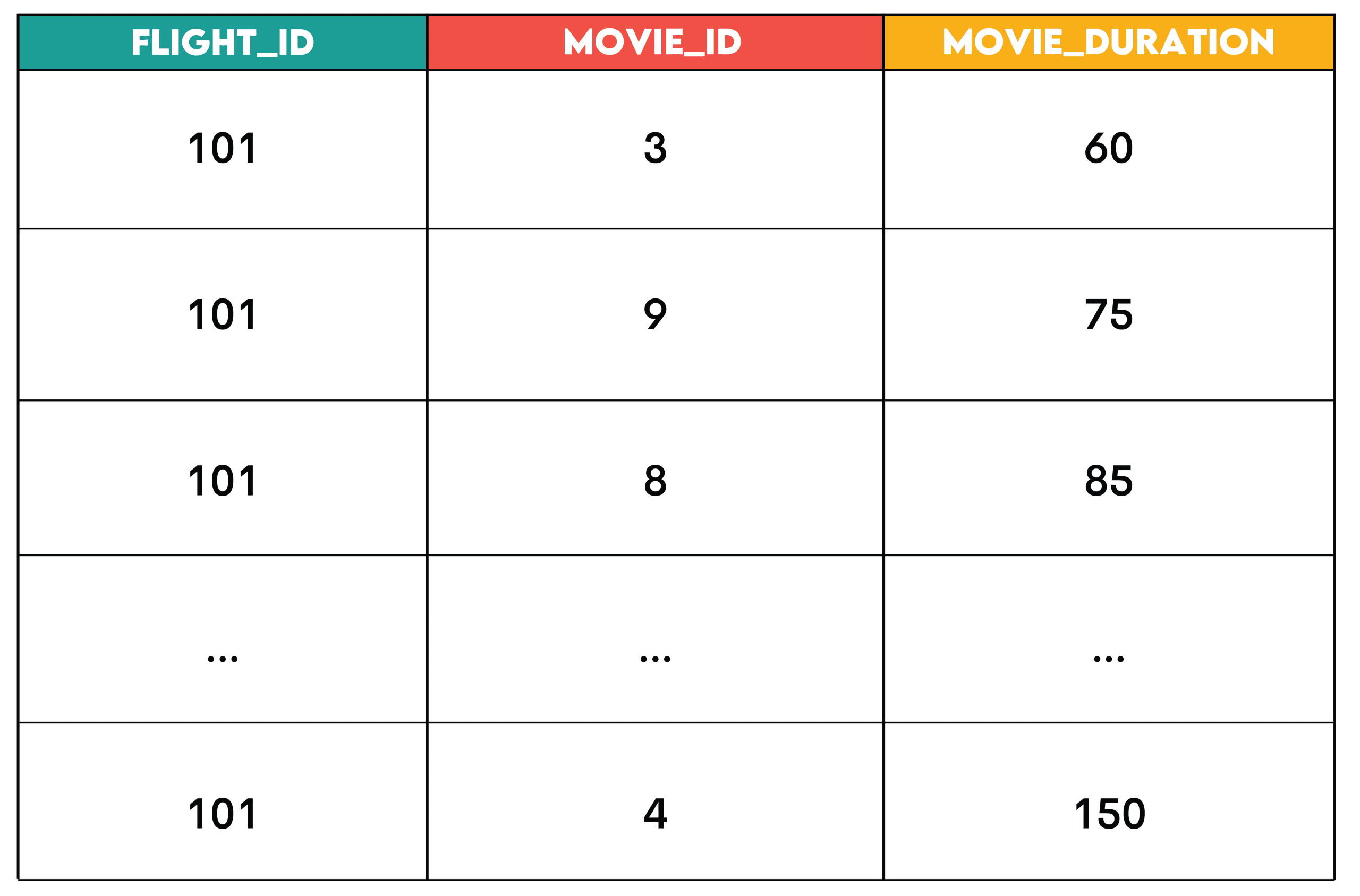
Sample: The be part of + filter is the sample the place you be part of two datasets and filter rows (in WHERE earlier than aggregation or in HAVING after aggregation) primarily based on situations.
That is the sequence.

- Establish the first desk: The dataset that defines what you’re analyzing (
flight_schedule) - Be part of supplementary information: The dataset(s) that add context or attributes (
entertainment_catalog) - Apply filters: Take away the rows you don’t want (
WHERE fs.flight_id = 101)
// Enterprise Makes use of
- HR: Becoming a member of staff with their working hours to determine additional time
- Retail: Becoming a member of orders with product particulars to research product class efficiency
- Streaming: Becoming a member of customers with their periods to search out energetic viewers
# 2. Window Capabilities: Rating & Ordering
Query: High Posts Per Channel from Meta
Job: Establish the highest 3 posts with the best like counts for every channel. Assign a rank to every publish primarily based on its like depend, permitting for gaps in rating when posts have the identical variety of likes.
The output ought to show the channel title, publish ID, publish creation date, and the like depend for every publish.
Resolution:
WITH ranked_posts AS
(SELECT post_id,
channel_id,
created_at,
likes,
RANK() OVER (PARTITION BY channel_id ORDER BY likes DESC) AS post_rank
FROM posts
WHERE likes > 0)
SELECT c.channel_name,
r.post_id,
r.created_at,
r.likes
FROM ranked_posts AS r
JOIN channels AS c ON r.channel_id = c.channel_id
WHERE r.post_rank <= 3;
Output:
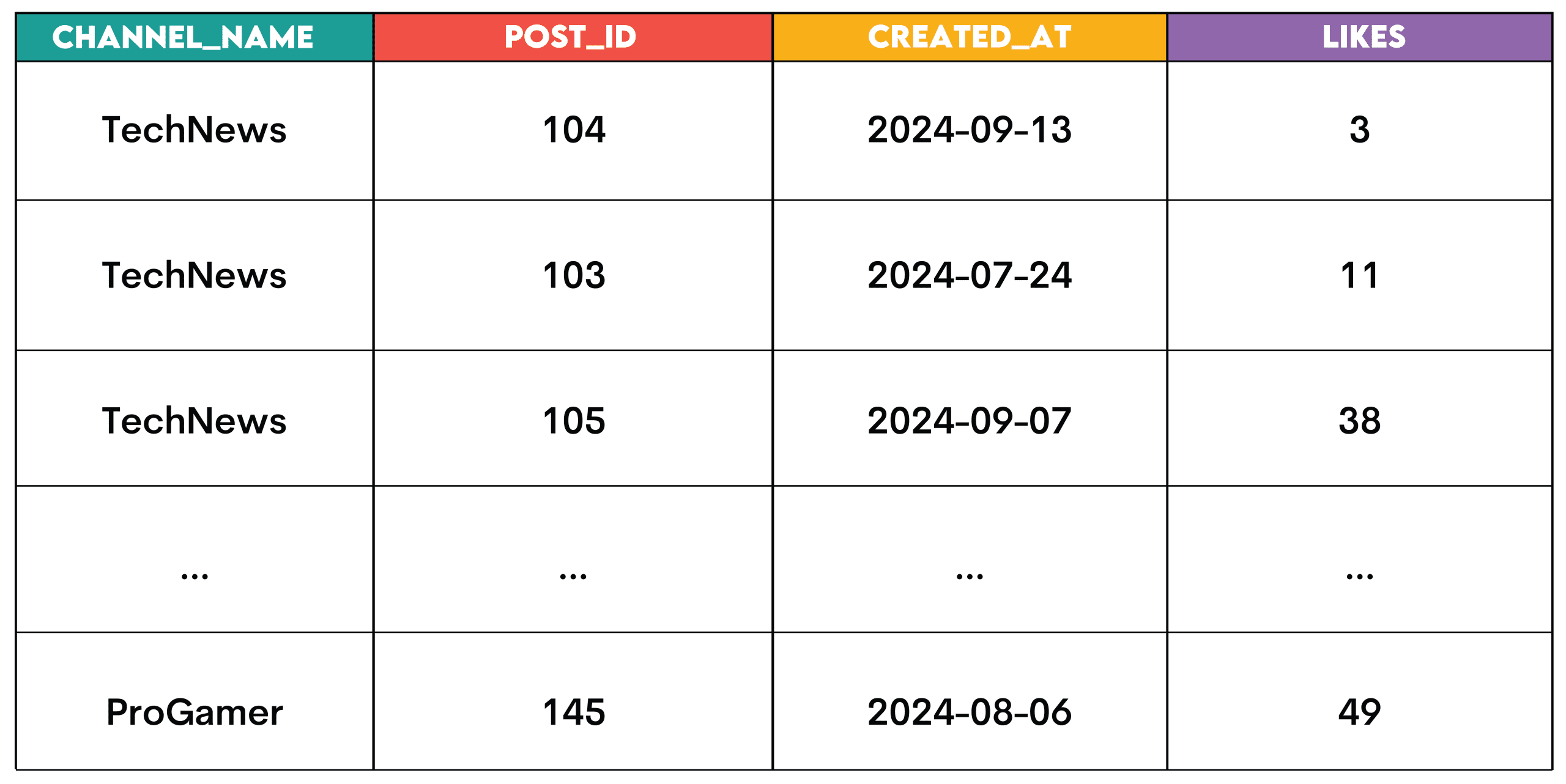
Sample: These are the window features used for rating.
RANK(): Rating with gapsDENSE_RANK(): Rating with out gapsROW_NUMBER(): Distinctive ordering with no ties
When rating, observe this sample.
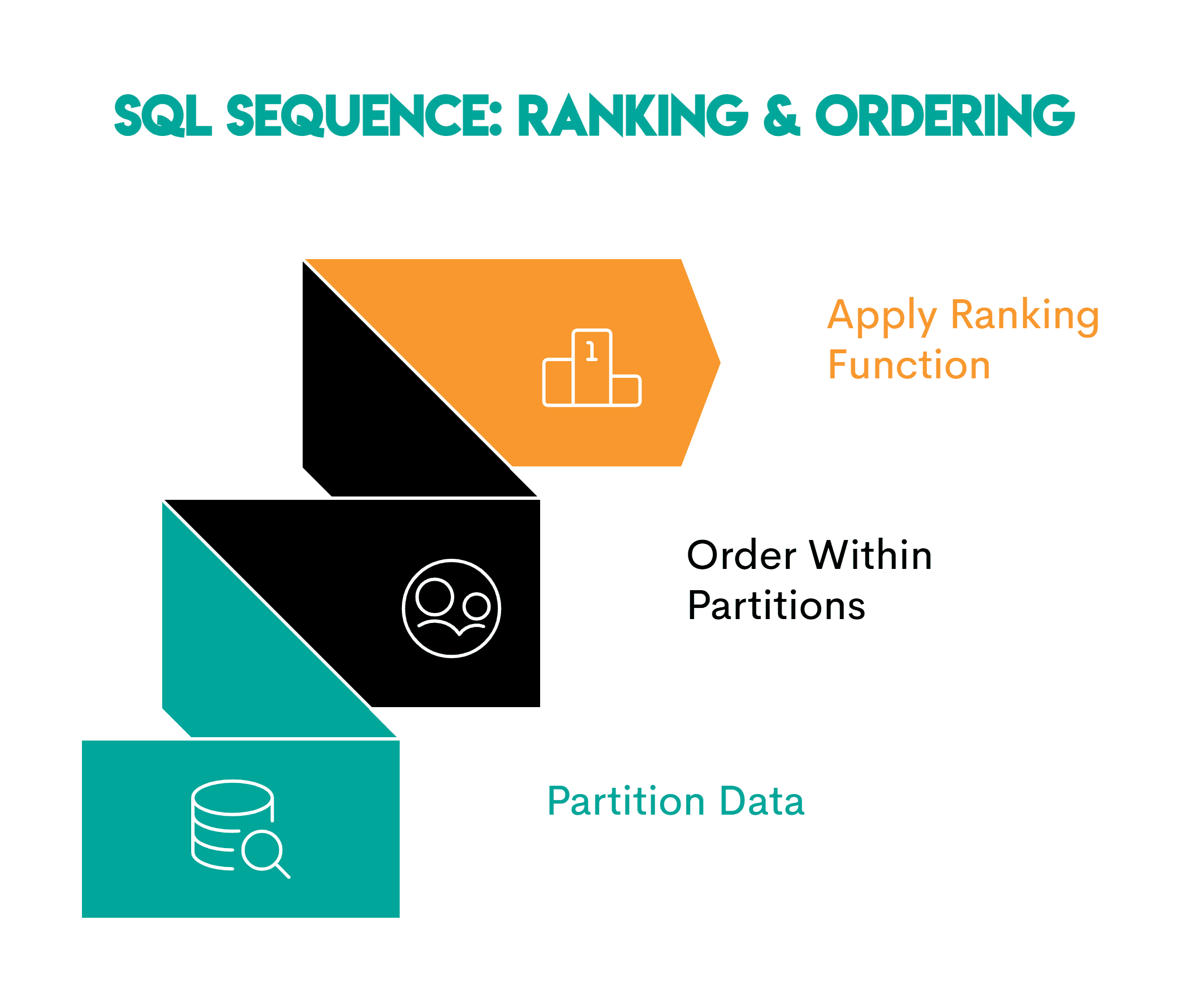
- Partition the info: Outline the logical group you’re analyzing (
PARTITION BY channel_id) - Order inside every partition: Specify the rating or time sequence (
ORDER BY likes DESC) - Apply the rating window perform —
RANK(),DENSE_RANK()orROW_NUMBER() OVER()relying on the duty
// Enterprise Makes use of
This sample is used to determine high performers, for instance:
- Gross sales: High gross sales representatives per area
- Training: Rating college students by check scores inside every class
- Logistics: Rating supply drivers by accomplished deliveries inside every area
# 3. Aggregation + Grouping: The Roll-Up Sample
Query: Similar-Day Orders from Walmart
Job: Discover customers who began a session and positioned an order on the identical day. Calculate the full variety of orders positioned on that day and the full order worth for that day.
Resolution:
SELECT s.user_id,
s.session_date,
COUNT(o.order_id) AS total_orders,
SUM(o.order_value) AS total_order_value
FROM
(SELECT DISTINCT user_id,
session_date
FROM periods) s
JOIN order_summary o ON s.user_id = o.user_id
AND s.session_date = o.order_date
GROUP BY s.user_id, s.session_date;
Output:
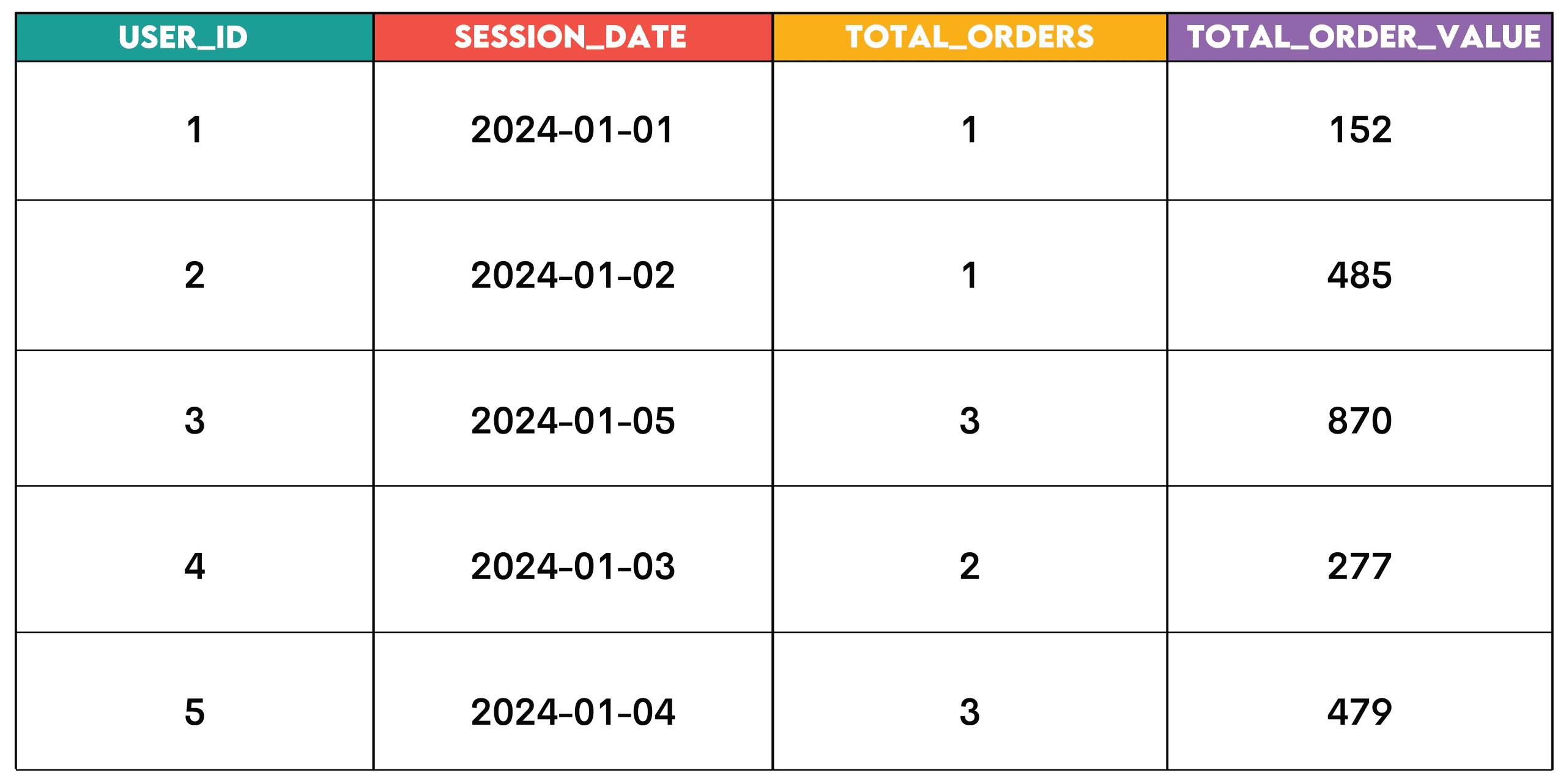
Sample: This sample is for summarizing information, e.g. throughout customers, dates, merchandise, or different analytical dimensions.
Right here’s the sequence.

- Establish the grouping dimension: The column you wish to group by (
user_idandsession_date) - Group the info: Use
GROUP BYon the chosen dimension(s) to group the info - Mixture the metrics: Summarize the values for every group utilizing the mixture features
- Filter aggregated outcomes (non-obligatory): Use
HAVINGto maintain solely sure teams relying on the mixture worth
// Enterprise Makes use of
- E-commerce: Orders and income per buyer per day
- SaaS: Logins per consumer per week
- Finance: Transactions per account per quarter
# 4. Pivoting: Turning Rows Into Columns
Query: Highest Fee from the Metropolis of San Francisco
Job: Create a pivot desk that exhibits the best fee for every worker in every year, ordered by worker title in ascending order. The desk ought to present years 2011, 2012, 2013, and 2014.
Resolution:
SELECT employeename,
MAX(pay_2011) AS pay_2011,
MAX(pay_2012) AS pay_2012,
MAX(pay_2013) AS pay_2013,
MAX(pay_2014) AS pay_2014
FROM
(SELECT employeename,
CASE
WHEN yr = 2011
THEN totalpay
ELSE 0
END AS pay_2011,
CASE
WHEN yr = 2012
THEN totalpay
ELSE 0
END AS pay_2012,
CASE
WHEN yr = 2013
THEN totalpay
ELSE 0
END AS pay_2013,
CASE
WHEN yr = 2014
THEN totalpay
ELSE 0
END AS pay_2014
FROM sf_public_salaries) pmt
GROUP BY employeename
ORDER BY employeename;
Output:
![]()
Sample: Pivoting turns row values into columns. That is helpful when evaluating metrics throughout years, classes, or segments.
Right here’s the sequence.
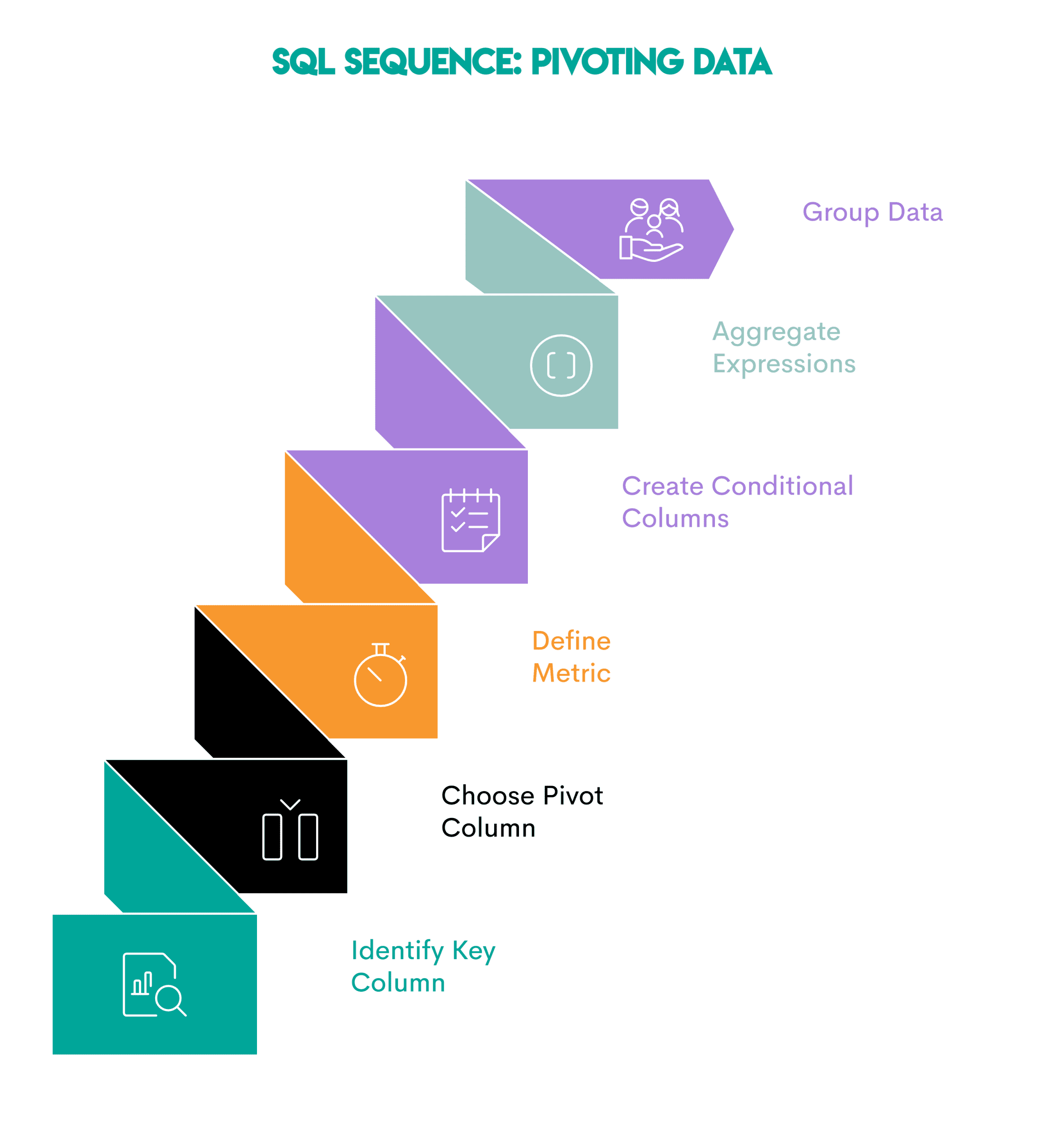
- Establish the important thing column: The column you wish to present as rows (
employeename) - Select the pivot column: The sector whose distinctive values will change into new columns (
yr) - Outline the metric: Decide the metric you wish to calculate and combination (
totalpay) - Create conditional columns: Use
CASE WHEN(orPIVOT, the place supported) to assign values to every column primarily based on the pivot column - Mixture conditional expressions within the outer question: Mixture every pivot column
- Group the info: Use
GROUP BYon the important thing column to group the output
// Enterprise Makes use of
- Finance: Evaluating income per quarter side-by-side
- HR: Evaluating salaries throughout years
- Retail: Evaluating month-to-month gross sales totals
# 5. Cumulative Metrics: Development, Retention, and Progress
Query: Income Over Time from Amazon
Job: Calculate the 3-month rolling common of complete income from purchases. The returns — represented by detrimental buy values — shouldn’t be included within the calculation.
The output ought to present year-month (YYYY-MM) and the rolling common, sorted from the earliest to the newest month.
Resolution:
SELECT t.month,
AVG(t.monthly_revenue) OVER (ORDER BY t.month ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS avg_revenue
FROM
(SELECT to_char(created_at::date, 'YYYY-MM') AS month,
SUM(purchase_amt) AS monthly_revenue
FROM amazon_purchases
WHERE purchase_amt > 0
GROUP BY to_char(created_at::date, 'YYYY-MM')
ORDER BY to_char(created_at::date, 'YYYY-MM')
) t
ORDER BY t.month ASC;
Output:
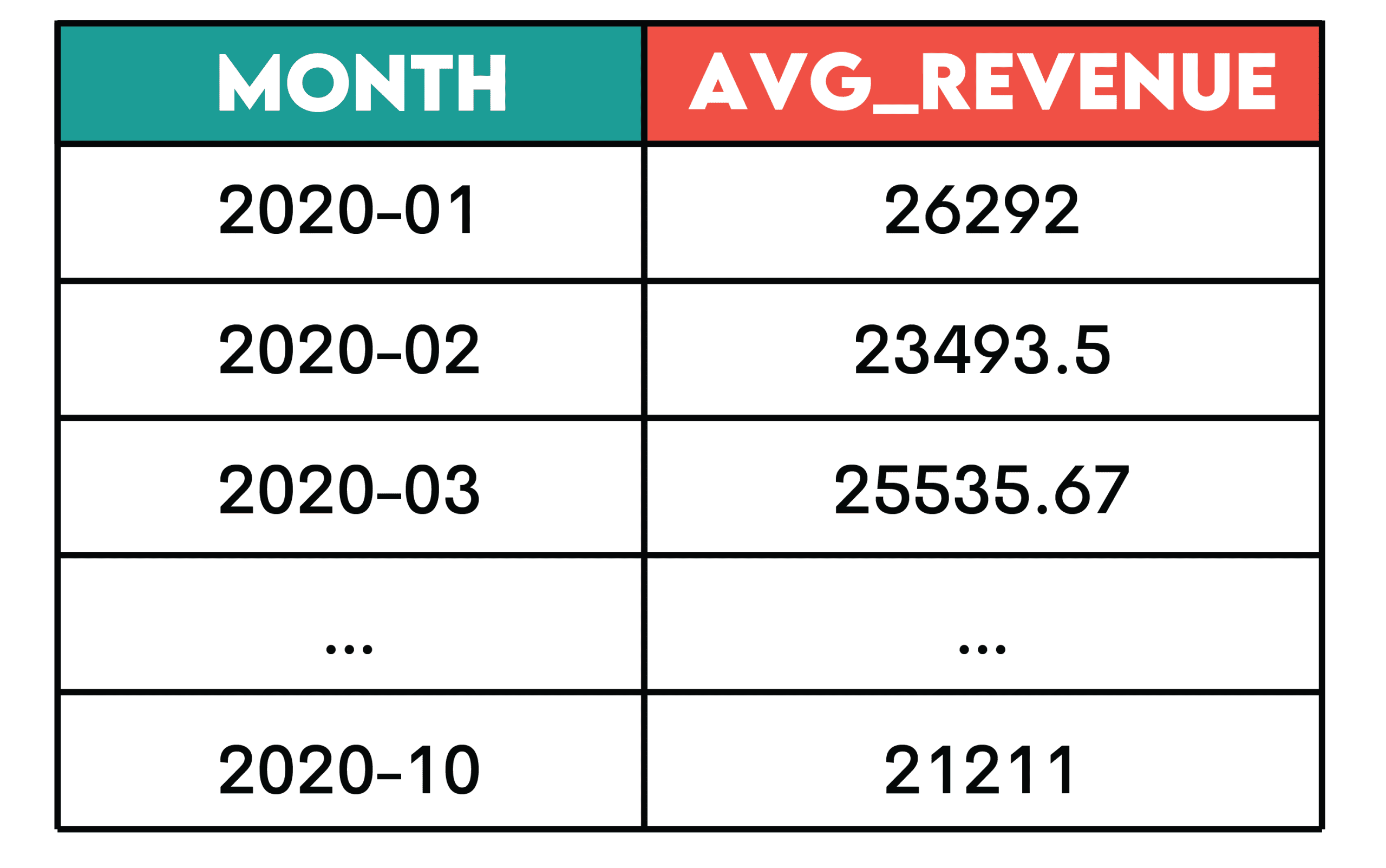
Sample: Cumulative metrics (e.g. working complete, transferring common, or working depend) are used to grasp tendencies fairly than exhibiting particular person time durations individually.
Right here’s the sequence.

- Pre-aggregation (non-obligatory) by time-period: Summarize the analytical information into totals per the required time interval (proven within the subquery)
- Apply the mixture perform: Use an combination perform on the column you wish to combination in the principle question
- Flip the mixture perform right into a window perform: Use the
OVER()clause - Order the time durations: Kind the info inside a partition chronologically so the cumulative calculation is utilized appropriately (
ORDER BY t.month) - Outline the window body: Outline the variety of earlier or following durations to incorporate within the cumulative calculation (
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
// Enterprise Makes use of
- E-commerce: Operating complete income
- SaaS: Cumulative energetic customers
- Product analytics: Cohort retention curves
- Finance: Trailing averages
- Operations: Rolling complete of help tickets
# 6. Funnel Evaluation: Monitoring Sequential Conduct
Query: Penetration Evaluation by Spotify
Job: We’ll should revise the necessities. The brand new job is to measure how customers progress via engagement levels on Spotify. Listed here are the levels of engagement:
- Energetic — Consumer had a minimum of one session
- Engaged — Consumer had 5+ periods
- Energy Consumer — Consumer had 5+ periods and a minimum of 10 listening hours prior to now 30 days
For every nation, calculate what number of customers attain every stage and the general conversion charge from first exercise to energy consumer standing.
Resolution:
WITH base AS (
SELECT nation,
user_id,
periods,
listening_hours,
last_active_date
FROM penetration_analysis
),
stage_1 AS (
SELECT DISTINCT user_id, nation
FROM base
WHERE periods > 0
),
stage_2 AS (
SELECT DISTINCT user_id, nation
FROM base
WHERE periods >= 5
),
stage_3 AS (
SELECT DISTINCT user_id, nation
FROM base
WHERE periods >= 5 AND listening_hours >= 10
)
SELECT nation,
COUNT(DISTINCT s1.user_id) AS users_started,
COUNT(DISTINCT s2.user_id) AS engaged_5_sessions,
COUNT(DISTINCT s3.user_id) AS power_users,
ROUND(100.0 * COUNT(DISTINCT s3.user_id) / NULLIF(COUNT(DISTINCT s1.user_id), 0), 2
) AS conversion_rate
FROM stage_1 s1
LEFT JOIN stage_2 s2 USING (user_id, nation)
LEFT JOIN stage_3 s3 USING (user_id, nation)
GROUP BY nation;
Output:
![]()
Sample: Funnel evaluation exhibits how customers transfer via a collection of ordered levels. As a result of the evaluation is dependent upon finishing the one earlier than it, it focuses on conversion and drop-off.
Right here’s the sequence.
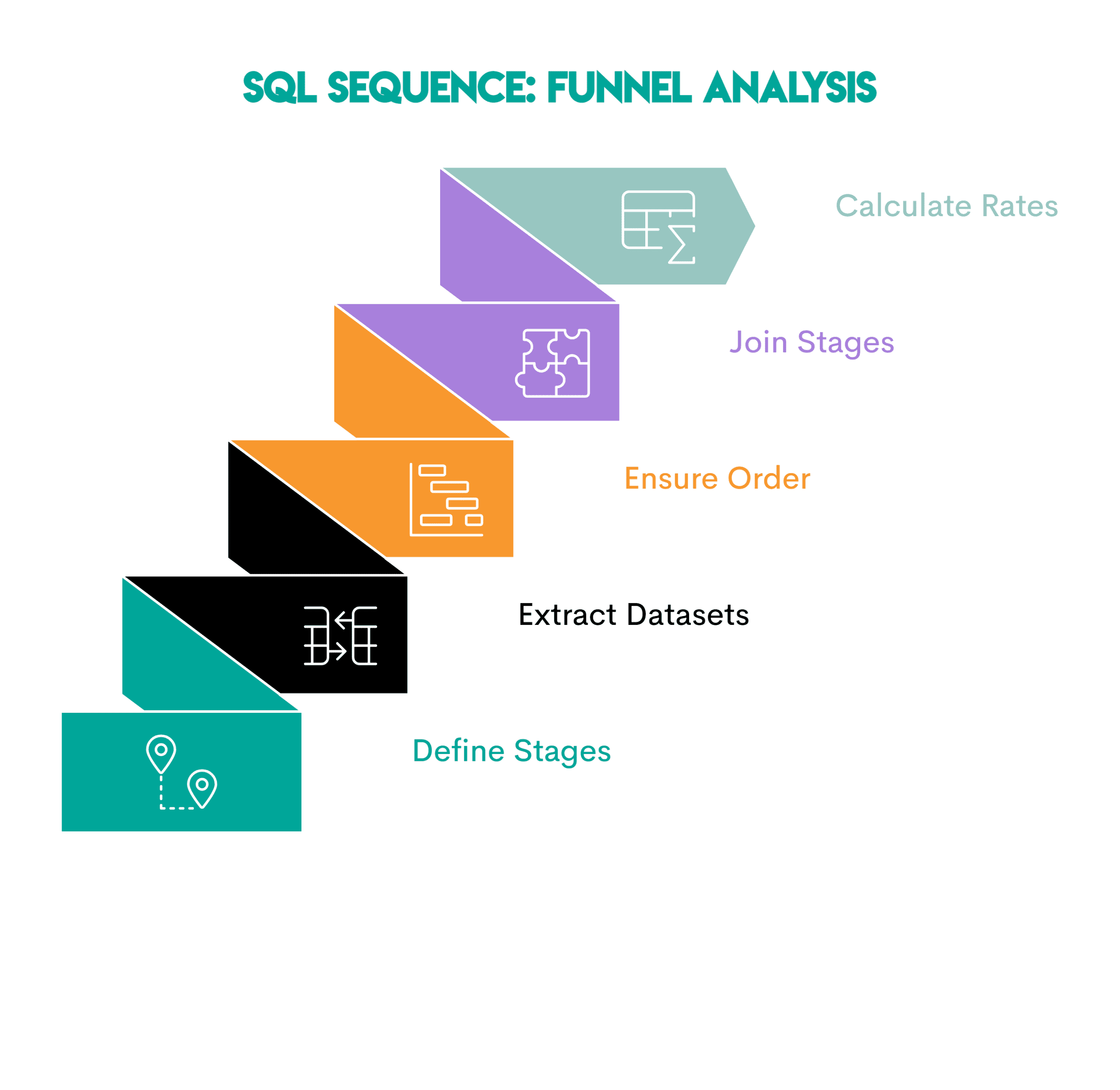
- Outline the levels: Establish every step a consumer should full
- Extract one dataset per stage: Write a typical desk expression (CTE) or subquery for every stage, containing solely the customers who qualify
- Guarantee stage order: If wanted, filter by timestamps or sequence guidelines in order that later levels happen after earlier ones
- Be part of the levels: Be part of the stage datasets utilizing
LEFT JOINto see what number of customers attain every step - Depend the customers and calculate conversion charges: Examine the variety of customers in every stage
// Enterprise Makes use of
- E-commerce: Go to -> Add to Cart -> Buy
- SaaS: Signup -> Activate -> Retain
- Streaming: Pay attention As soon as -> Have interaction Recurrently -> Turn out to be Energy Consumer
# 7. Time-Based mostly Comparability: Interval-over-Interval Metrics
Query: Day by day Violation Counts from the Metropolis of San Francisco
Job: Decide the change within the variety of every day violations by calculating the distinction between the variety of present and former violations by inspection date.
Present the inspection date and the change within the variety of every day violations, ordered from the earliest to the newest inspection.
Resolution:
SELECT inspection_date::DATE,
COUNT(violation_id) - LAG(COUNT(violation_id)) OVER(ORDER BY inspection_date::DATE) AS diff
FROM sf_restaurant_health_violations
GROUP BY 1
ORDER BY 1;
Output:
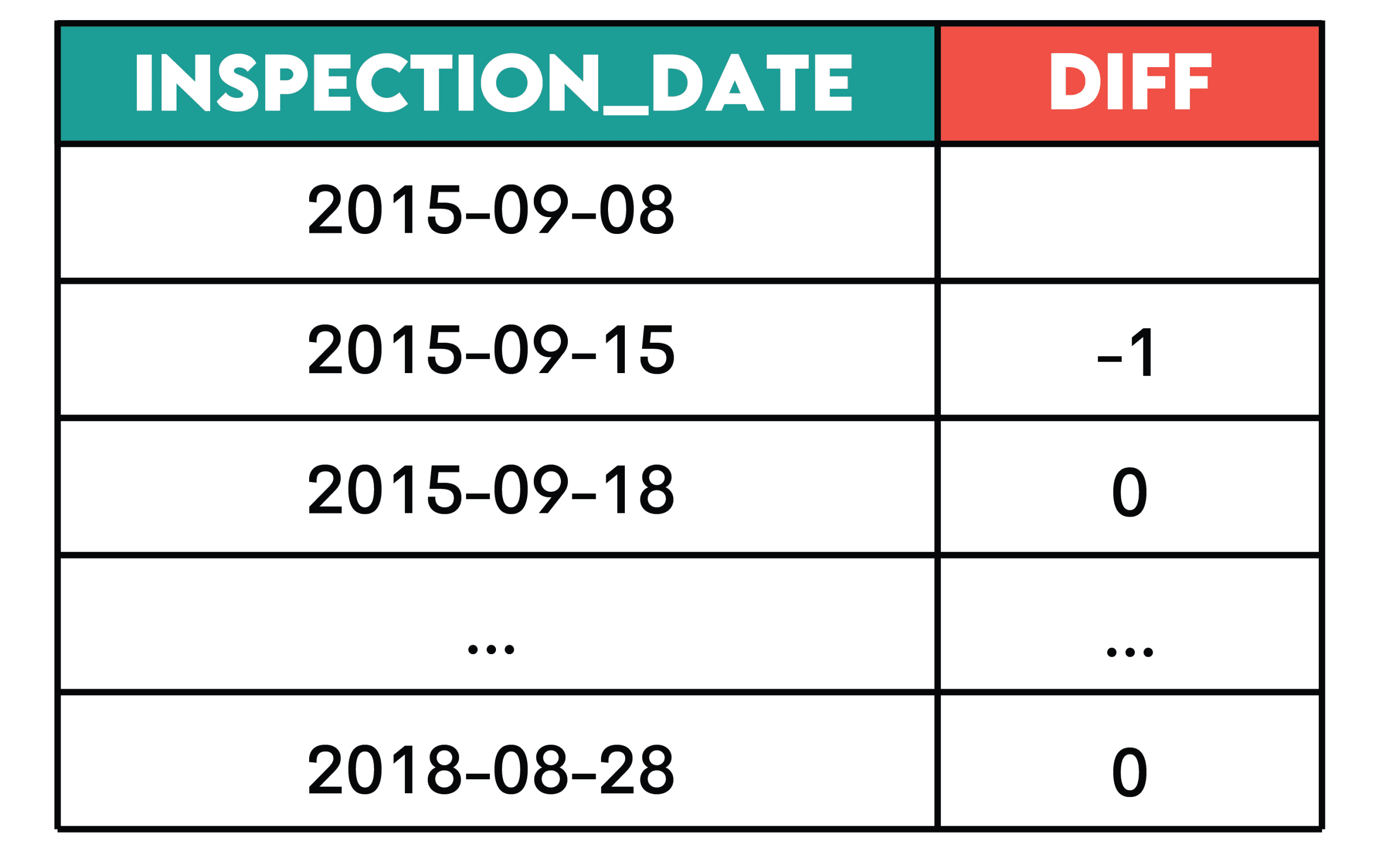
Sample: This sample is beneficial while you wish to see how a metric adjustments over time.
Right here’s the sequence.
- Mixture information: Summarize the occasions into time durations (every day/weekly/month-to-month totals)
- Apply a window perform: Use
LAG()orLEAD()to entry the values from the earlier or the next interval - Order the time durations: Use the
ORDER BYclause inOVER()to kind the info chronologically so comparisons are appropriate - Calculate the distinction: Subtract the prior worth from the present worth to get the distinction
// Enterprise Makes use of
- Product: Day-to-day adjustments in energetic customers
- Operations: Day by day adjustments in help quantity
- Finance: Month-over-month income deltas
# Wrapping Up
Internalize these seven patterns and watch the info evaluation issues dissolve earlier than your eyes. I’m certain they are going to be useful in lots of enterprise conditions and job interviews.
Nate Rosidi is an information scientist and in product technique. He is additionally an adjunct professor instructing analytics, and is the founding father of StrataScratch, a platform serving to information scientists put together for his or her interviews with actual interview questions from high firms. Nate writes on the newest tendencies within the profession market, offers interview recommendation, shares information science tasks, and covers every little thing SQL.

