

The event of huge language fashions (LLMs) has been outlined by the pursuit of uncooked scale. Whereas rising parameter counts into the trillions initially drove efficiency positive aspects, it additionally launched important infrastructure overhead and diminishing marginal utility. The discharge of the Qwen 3.5 Medium Mannequin Collection indicators a shift in Alibaba’s Qwen method, prioritizing architectural effectivity and high-quality information over conventional scaling.
The sequence encompasses a lineup together with Qwen3.5-Flash, Qwen3.5-35B-A3B, Qwen3.5-122B-A10B, and Qwen3.5-27B. These fashions show that strategic architectural selections and Reinforcement Studying (RL) can obtain frontier-level intelligence with considerably decrease compute necessities.
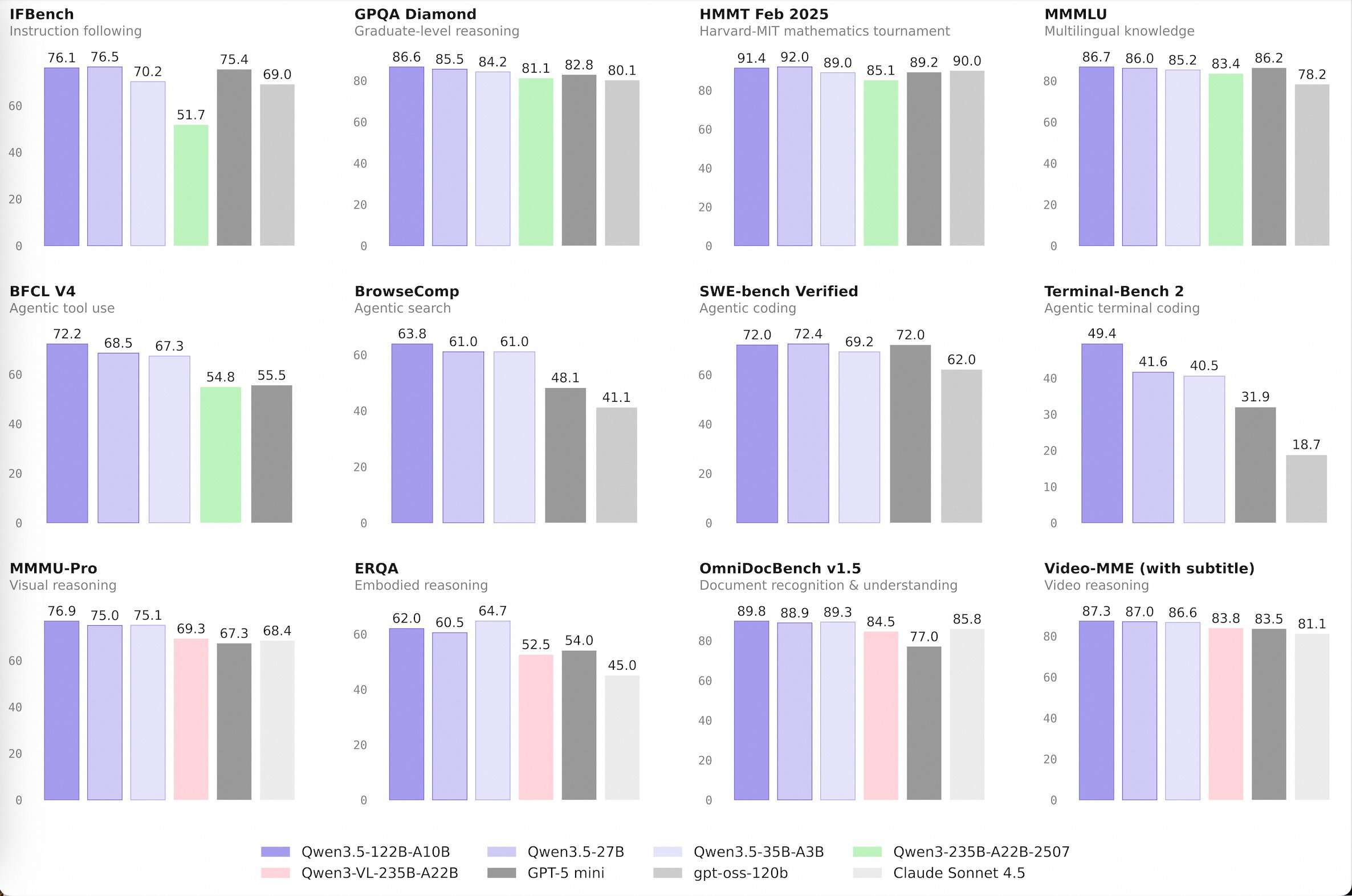
The Effectivity Breakthrough: 35B Surpasses 235B
Essentially the most notable technical milestone is the efficiency of Qwen3.5-35B-A3B, which now outperforms the older Qwen3-235B-A22B-2507 and the vision-capable Qwen3-VL-235B-A22B.
The ‘A3B’ suffix is the important thing metric. This means the Lively Parameters in a Combination-of-Consultants (MoE) structure. Though the mannequin has 35 billion whole parameters, it solely prompts 3 billion throughout any single inference go. The truth that a mannequin with 3B energetic parameters can outperform a predecessor with 22B energetic parameters highlights a significant leap in reasoning density.
This effectivity is pushed by a hybrid structure that integrates Gated Delta Networks (linear consideration) with customary Gated Consideration blocks. This design permits high-throughput decoding and a decreased reminiscence footprint, making high-performance AI extra accessible on customary {hardware}.
Qwen3.5-Flash: Optimized for Manufacturing
Qwen3.5-Flash serves because the hosted manufacturing model of the 35B-A3B mannequin. It’s particularly developed for software program devs who require low-latency efficiency in agentic workflows.
- 1M Context Size: By offering a 1-million-token context window by default, Flash reduces the necessity for advanced RAG (Retrieval-Augmented Era) pipelines when dealing with giant doc units or codebases.
- Official Constructed-in Instruments: The mannequin options native assist for device use and performance calling, permitting it to interface instantly with APIs and databases with excessive precision.
Excessive-Reasoning Agentic Eventualities
The Qwen3.5-122B-A10B and Qwen3.5-27B fashions are designed for ‘agentic’ duties—situations the place a mannequin should plan, cause, and execute multi-step workflows. These fashions slim the hole between open-weight alternate options and proprietary frontier fashions.
Alibaba Qwen workforce utilized a four-stage post-training pipeline for these fashions, involving lengthy chain-of-thought (CoT) chilly begins and reasoning-based RL. This enables the 122B-A10B mannequin, using solely 10 billion energetic parameters, to keep up logical consistency over long-horizon duties, rivaling the efficiency of a lot bigger dense fashions.
Key Takeaways
- Architectural Effectivity (MoE): The Qwen3.5-35B-A3B mannequin, with solely 3 billion energetic parameters (A3B), outperforms the earlier era’s 235B mannequin. This demonstrates that Combination-of-Consultants (MoE) structure, when mixed with superior information high quality and Reinforcement Studying (RL), can ship ‘frontier-level’ intelligence at a fraction of the compute price.
- Manufacturing-Prepared Efficiency (Flash): Qwen3.5-Flash is the hosted manufacturing model aligned with the 35B mannequin. It’s particularly optimized for high-throughput, low-latency functions, making it the ‘workhorse’ for builders transferring from prototype to enterprise-scale deployment.
- Huge Context Window: The sequence encompasses a 1M context size by default. This permits long-context duties like full-repository code evaluation or large doc retrieval with out the necessity for advanced RAG (Retrieval-Augmented Era) ‘chunking’ methods, considerably simplifying the developer workflow.
- Native Instrument Use & Agentic Capabilities: Not like fashions that require in depth immediate engineering for exterior interactions, Qwen 3.5 contains official built-in instruments. This native assist for perform calling and API interplay makes it extremely efficient for ‘agentic’ situations the place the mannequin should plan and execute multi-step workflows.
- The ‘Medium’ Candy Spot: By specializing in fashions starting from 27B to 122B (A10B energetic), Alibaba is focusing on the business’s ‘Goldilocks’ zone. These fashions are sufficiently small to run on personal or localized cloud infrastructure whereas sustaining the advanced reasoning and logical consistency usually reserved for large, closed-source proprietary fashions.
Take a look at the Mannequin Weights and Flash API. Additionally, be happy to comply with us on Twitter and don’t overlook to affix our 120k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as effectively.


