

Qwen3-Max-Pondering is Alibaba’s new flagship reasoning mannequin. It doesn’t solely scale parameters, it additionally modifications how inference is completed, with specific management over considering depth and in-built instruments for search, reminiscence, and code execution.
Mannequin scale, information, and deployment
Qwen3-Max-Pondering is a trillion-parameter MoE flagship LLM pretrained on 36T tokens and constructed on the Qwen3 household as the highest tier reasoning mannequin. The mannequin targets lengthy horizon reasoning and code, not solely informal chat. It runs with a context window of 260k tokens, which helps repository scale code, lengthy technical reviews, and multi doc evaluation inside a single immediate.
Qwen3-Max-Pondering is a closed mannequin served by way of Qwen-Chat and Alibaba Cloud Mannequin Studio with an OpenAI appropriate HTTP API. The identical endpoint could be referred to as in a Claude model device schema, so current Anthropic or Claude Code flows can swap in Qwen3-Max-Pondering with minimal modifications. There aren’t any public weights, so utilization is API based mostly, which matches its positionin
Sensible Take a look at Time Scaling and expertise cumulative reasoning
Most massive language fashions enhance reasoning by easy take a look at time scaling, for instance better of N sampling with a number of parallel chains of thought. That method will increase high quality however price grows virtually linearly with the variety of samples. Qwen3-Max-Pondering introduces an expertise cumulative, multi spherical take a look at time scaling technique.
As a substitute of solely sampling extra in parallel, the mannequin iterates inside a single dialog, reusing intermediate reasoning traces as structured expertise. After every spherical, it extracts helpful partial conclusions, then focuses subsequent computation on unresolved components of the query. This course of is managed by an specific considering finances that builders can regulate through API parameters comparable to enable_thinking and extra configuration fields.
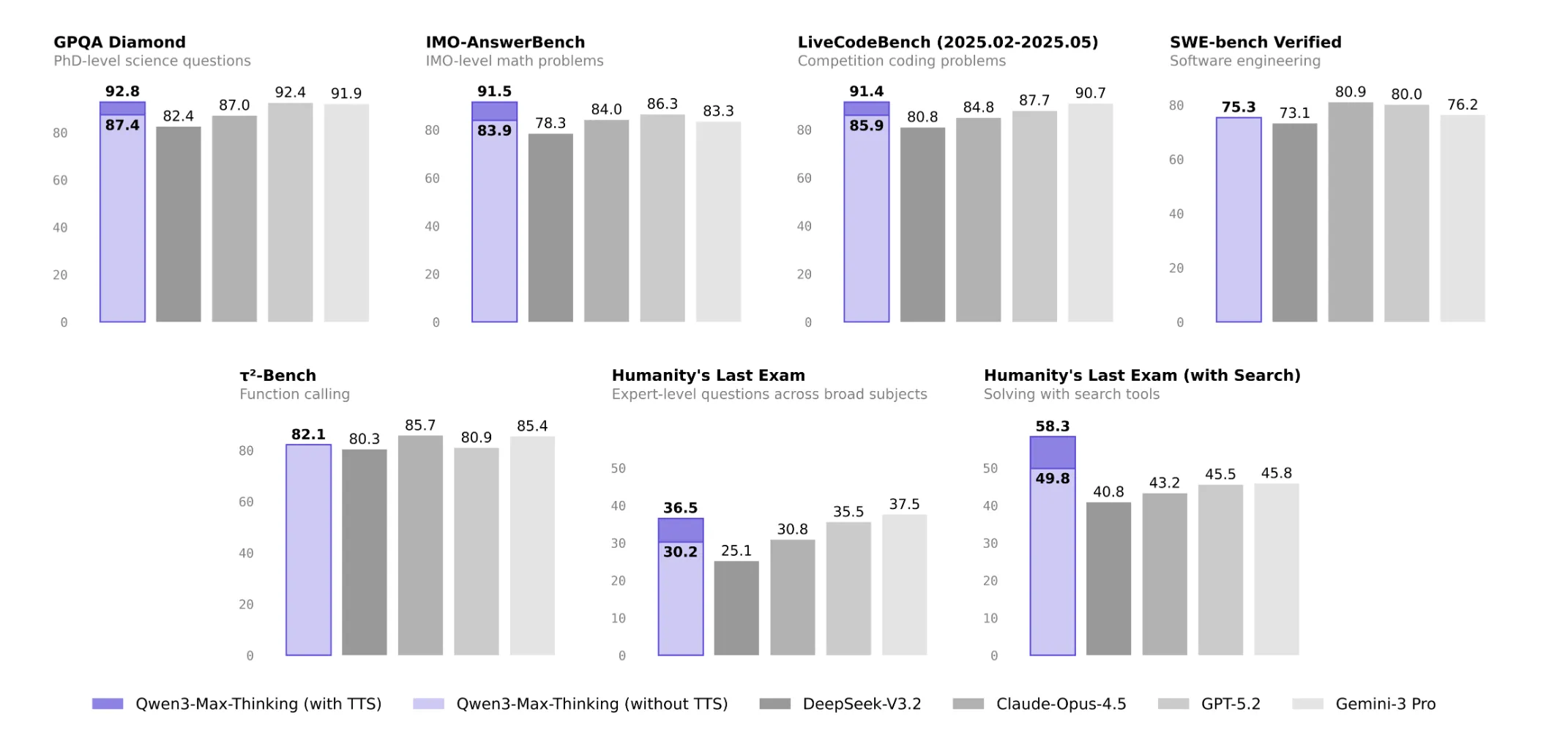
The reported impact is that accuracy rises with no proportional enhance in token rely. For instance, Qwen’s personal ablations present GPQA Diamond rising from round 90 stage accuracy to about 92.8, and LiveCodeBench v6 rising from about 88.0 to 91.4 beneath the expertise cumulative technique at comparable token budgets. That is vital as a result of it means greater reasoning high quality could be pushed by extra environment friendly scheduling of compute, not solely by extra samples.
Native agent stack with Adaptive Software Use
Qwen3-Max-Pondering integrates three instruments as top quality capabilities: Search, Reminiscence, and a Code Interpreter. Search connects to internet retrieval so the mannequin can fetch contemporary pages, extract content material, and floor its solutions. Reminiscence shops consumer or session particular state, which helps personalised reasoning over longer workflows. The Code Interpreter executes Python, which permits numeric verification, information transforms, and program synthesis with runtime checks.
The mannequin makes use of Adaptive Software Use to determine when to invoke these instruments throughout a dialog. Software calls are interleaved with inner considering segments, relatively than being orchestrated by an exterior agent. This design reduces the necessity for separate routers or planners and tends to cut back hallucinations, as a result of the mannequin can explicitly fetch lacking data or confirm calculations as an alternative of guessing.
Software means can also be benchmarked. On Tau² Bench, which measures operate calling and power orchestration, Qwen3-Max-Pondering reviews a rating of 82.1, comparable with different frontier fashions on this class.
Benchmark profile throughout data, reasoning, and search
On 19 public benchmarks, Qwen3-Max-Pondering is positioned at or close to the identical stage as GPT 5.2 Pondering, Claude Opus 4.5, and Gemini 3 Professional. For data duties, reported scores embody 85.7 on MMLU-Professional, 92.8 on MMLU-Redux, and 93.7 on C-Eval, the place Qwen leads the group on Chinese language language analysis.
For onerous reasoning, it information 87.4 on GPQA, 98.0 on HMMT Feb 25, 94.7 on HMMT Nov 25, and 83.9 on IMOAnswerBench, which places it within the prime tier of present math and science fashions. On coding and software program engineering it reaches 85.9 on LiveCodeBench v6 and 75.3 on SWE Verified.
Within the base HLE configuration Qwen3-Max-Pondering scores 30.2, beneath Gemini 3 Professional at 37.5 and GPT 5.2 Pondering at 35.5. In a device enabled HLE setup, the official comparability desk that features internet search integration reveals Qwen3-Max-Pondering at 49.8, forward of GPT 5.2 Pondering at 45.5 and Gemini 3 Professional at 45.8. With its most aggressive expertise cumulative take a look at time scaling configuration on HLE with instruments, Qwen3-Max-Pondering reaches 58.3 whereas GPT 5.2 Pondering stays at 45.5, though that greater quantity is for a heavier inference mode than the usual comparability desk.
Key Takeaways
- Qwen3-Max-Pondering is a closed, API solely flagship reasoning mannequin from Alibaba, constructed on a greater than 1 trillion parameter spine skilled on about 36 trillion tokens with a 262144 token context window.
- The mannequin introduces expertise cumulative take a look at time scaling, the place it reuses intermediate reasoning throughout a number of rounds, enhancing benchmarks comparable to GPQA Diamond and LiveCodeBench v6 at comparable token budgets.
- Qwen3-Max-Pondering integrates Search, Reminiscence, and a Code Interpreter as native instruments and makes use of Adaptive Software Use so the mannequin itself decides when to browse, recall state, or execute Python throughout a dialog.
- On public benchmarks it reviews aggressive scores with GPT 5.2 Pondering, Claude Opus 4.5, and Gemini 3 Professional, together with robust outcomes on MMLU Professional, GPQA, HMMT, IMOAnswerBench, LiveCodeBench v6, SWE Bench Verified, and Tau² Bench..
Take a look at the API and Technical particulars. Additionally, be at liberty to observe us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you possibly can be part of us on telegram as nicely.

Michal Sutter is a knowledge science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and information engineering, Michal excels at reworking advanced datasets into actionable insights.

