

For the previous couple of years, the AI world has adopted a easy rule: in order for you a Massive Language Mannequin (LLM) to resolve a tougher downside, make its Chain-of-Thought (CoT) longer. However new analysis from the College of Virginia and Google proves that ‘considering lengthy’ will not be the identical as ‘considering arduous’.
The analysis group reveals that merely including extra tokens to a response can truly make an AI much less correct. As an alternative of counting phrases, the Google researchers introduce a brand new measurement: the Deep-Pondering Ratio (DTR).
The Failure of ‘Token Maxing‘
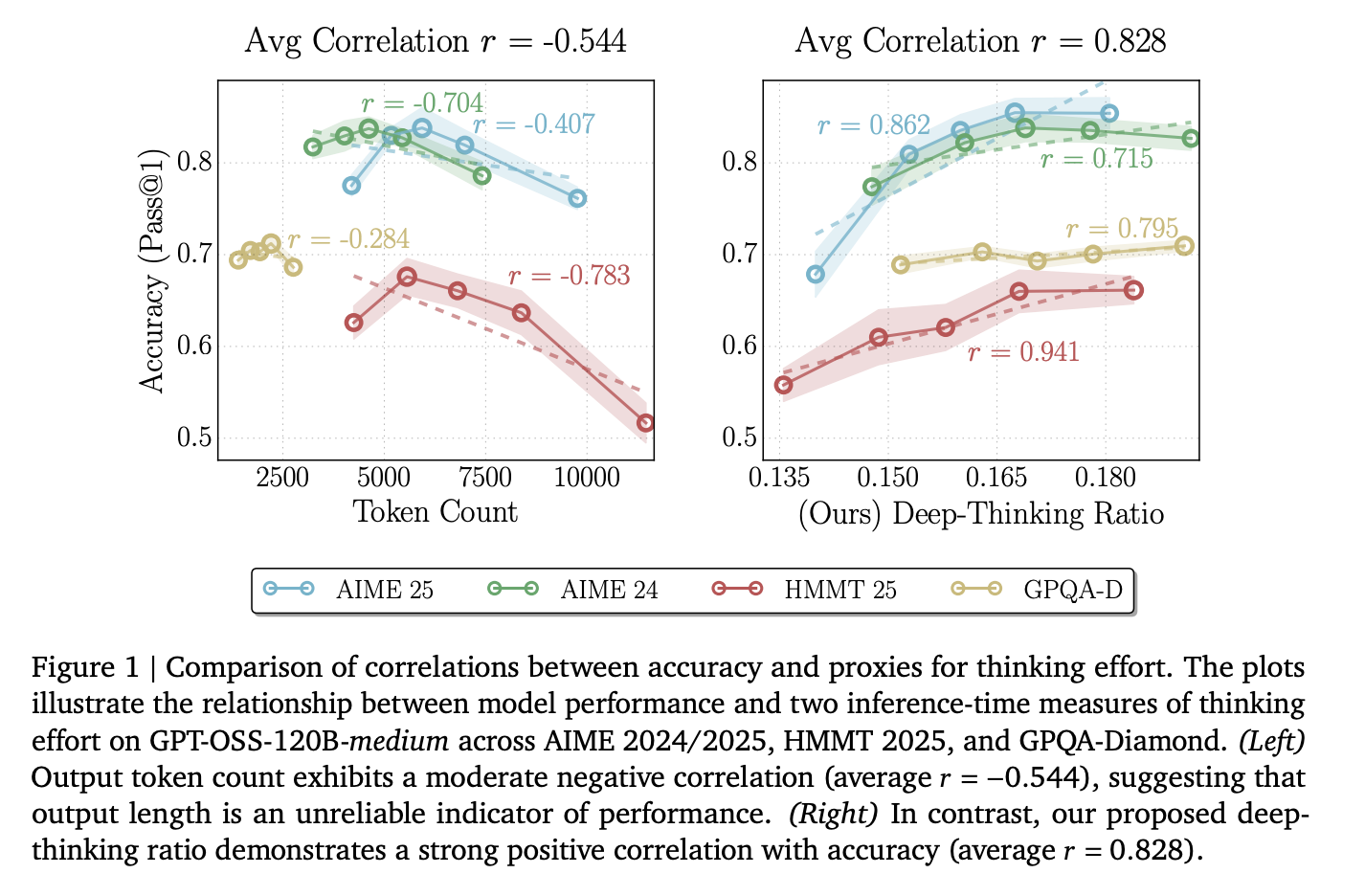
Engineers typically use token depend as a proxy for the hassle an AI places right into a job. Nevertheless, the researchers discovered that uncooked token depend has a mean correlation of r= -0.59 with accuracy.
This unfavorable quantity signifies that because the mannequin generates extra textual content, it’s extra prone to be fallacious. This occurs due to ‘overthinking,’ the place the mannequin will get caught in loops, repeats redundant steps, or amplifies its personal errors. Counting on size alone wastes costly compute on uninformative tokens.
What are Deep-Pondering Tokens?
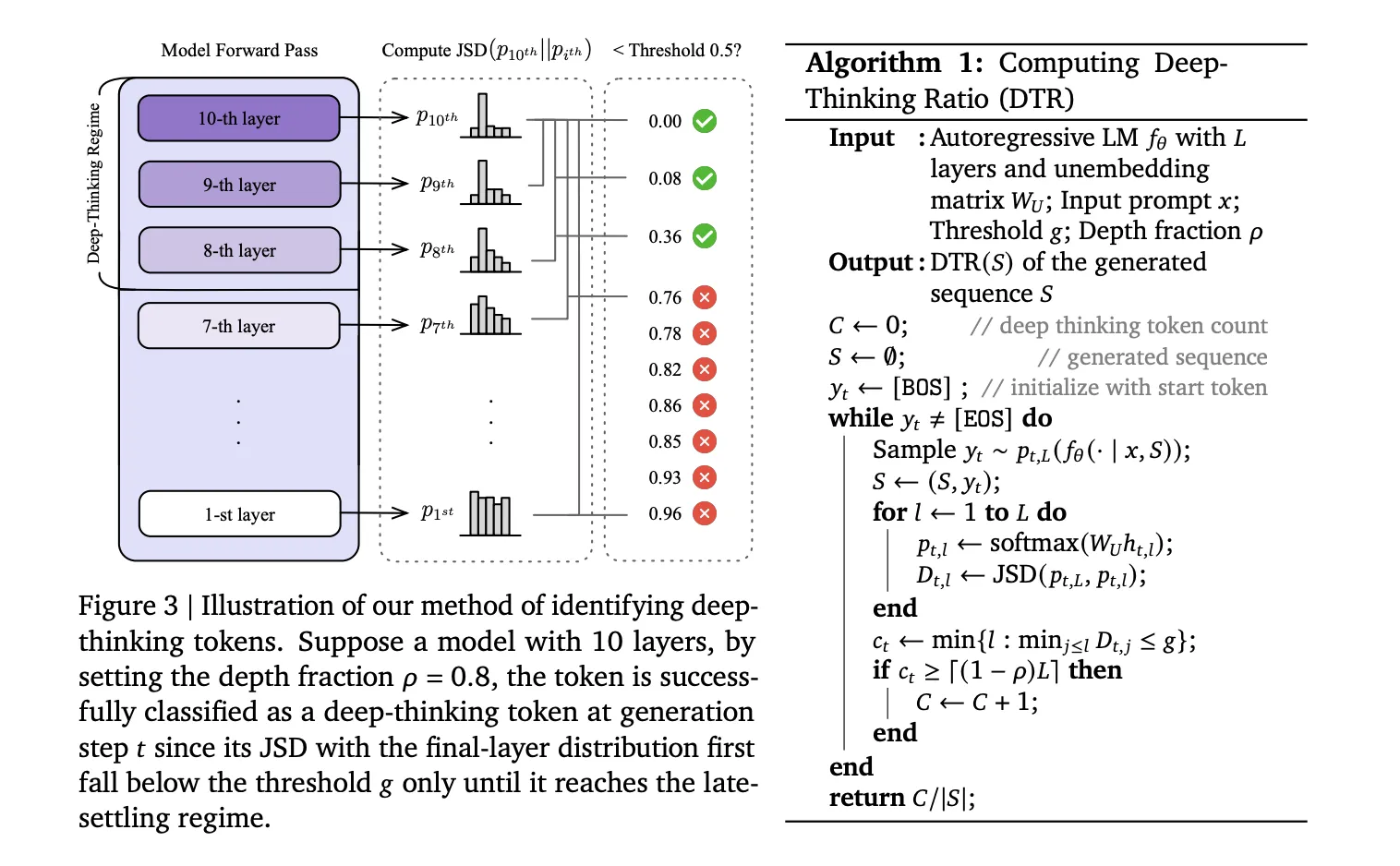
The analysis group argued that actual ‘considering’ occurs contained in the layers of the mannequin, not simply within the closing output. When a mannequin predicts a token, it processes knowledge by a collection of transformer layers (L).
- Shallow Tokens: For simple phrases, the mannequin’s prediction stabilizes early. The ‘guess’ doesn’t change a lot from layer 5 to layer 36.
- Deep-Pondering Tokens: For tough logic or math symbols, the prediction shifts considerably within the deeper layers.
The way to Measure Depth
To determine these tokens, the analysis group makes use of a way to peek on the mannequin’s inner ‘drafts’ at each layer. They challenge the intermediate hidden states (htl) into the vocabulary area utilizing the mannequin’s unembedding matrix (WU). This produces a likelihood distribution (pt,l) for each layer.
They then calculate the Jensen-Shannon Divergence (JSD) between the intermediate layer distribution and the ultimate layer distribution (pt,L):
Dt,l := JSD(pt,L || pt,l)
A token is a deep-thinking token if its prediction solely settles within the ‘late regime’—outlined by a depth fraction (⍴). Of their exams, they set ⍴= 0.85, which means the token solely stabilized within the closing 15% of the layers.
The Deep-Pondering Ratio (DTR) is the proportion of those ‘arduous’ tokens in a full sequence. Throughout fashions like DeepSeek-R1-70B, Qwen3-30B-Pondering, and GPT-OSS-120B, DTR confirmed a powerful common optimistic correlation of r = 0.683 with accuracy.
Suppose@n: Higher Accuracy at 50% the Price
The analysis group used this modern method to create Suppose@n, a brand new approach to scale AI efficiency throughout inference.
Most devs use Self-Consistency (Cons@n), the place they pattern 48 completely different solutions and use majority voting to select the perfect one. That is very costly as a result of you must generate each single token for each reply.
Suppose@n modifications the sport by utilizing ‘early halting’:
- The mannequin begins producing a number of candidate solutions.
- After simply 50 prefix tokens, the system calculates the DTR for every candidate.
- It instantly stops producing the ‘unpromising’ candidates with low DTR.
- It solely finishes the candidates with excessive deep-thinking scores.
The Outcomes on AIME 2025
| Technique | Accuracy | Avg. Price (okay tokens) |
| Cons@n (Majority Vote) | 92.7% | 307.6 |
| Suppose@n (DTR-based Choice) | 94.7% | 155.4 |
On the AIME 25 math benchmark, Suppose@n achieved greater accuracy than normal voting whereas decreasing the inference price by 49%.
Key Takeaways
- Token depend is a poor predictor of accuracy: Uncooked output size has a mean unfavorable correlation (r = -0.59) with efficiency, which means longer reasoning traces typically sign ‘overthinking’ reasonably than greater high quality.
- Deep-thinking tokens outline true effort: In contrast to easy tokens that stabilize in early layers, deep-thinking tokens are these whose inner predictions endure important revision in deeper mannequin layers earlier than converging.
- The Deep-Pondering Ratio (DTR) is a superior metric: DTR measures the proportion of deep-thinking tokens in a sequence and reveals a strong optimistic correlation with accuracy (common r = 0.683), persistently outperforming length-based or confidence-based baselines.
- Suppose@n permits environment friendly test-time scaling: By prioritizing and ending solely the samples with excessive deep-thinking ratios, the Suppose@n technique matches or exceeds the efficiency of normal majority voting (Cons@n).
- Huge price discount through early halting: As a result of DTR might be estimated from a brief prefix of simply 50 tokens, unpromising generations might be rejected early, decreasing whole inference prices by roughly 50%.
Take a look at the Paper. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you may be a part of us on telegram as properly.


