

Picture based mostly on Synthetic Evaluation
# Introduction
We regularly discuss small AI fashions. However what about tiny fashions that may really run on a Raspberry Pi with restricted CPU energy and little or no RAM?
Due to trendy architectures and aggressive quantization, fashions round 1 to 2 billion parameters can now run on extraordinarily small units. When quantized, these fashions can run nearly wherever, even in your good fridge. All you want is llama.cpp, a quantized mannequin from the Hugging Face Hub, and a easy command to get began.
What makes these tiny fashions thrilling is that they don’t seem to be weak or outdated. Lots of them outperform a lot older massive fashions in real-world textual content era. Some additionally help device calling, imaginative and prescient understanding, and structured outputs. These aren’t small and dumb fashions. They’re small, quick, and surprisingly clever, able to working on units that match within the palm of your hand.
On this article, we are going to discover 7 tiny AI fashions that run properly on a Raspberry Pi and different low-power machines utilizing llama.cpp. If you wish to experiment with native AI with out GPUs, cloud prices, or heavy infrastructure, this checklist is a good place to begin.
# 1. Qwen3 4B 2507
Qwen3-4B-Instruct-2507 is a compact but extremely succesful non-thinking language mannequin that delivers a serious leap in efficiency for its measurement. With simply 4 billion parameters, it exhibits sturdy good points throughout instruction following, logical reasoning, arithmetic, science, coding, and power utilization, whereas additionally increasing long-tail data protection throughout many languages.

The mannequin demonstrates notably improved alignment with person preferences in subjective and open-ended duties, leading to clearer, extra useful, and higher-quality textual content era. Its help for a powerful 256K native context size permits it to deal with extraordinarily lengthy paperwork and conversations effectively, making it a sensible selection for real-world functions that demand each depth and pace with out the overhead of bigger fashions.
# 2. Qwen3 VL 4B
Qwen3‑VL‑4B‑Instruct is probably the most superior imaginative and prescient‑language mannequin within the Qwen household to this point, packing state‑of‑the‑artwork multimodal intelligence right into a extremely environment friendly 4B‑parameter type issue. It delivers superior textual content understanding and era, mixed with deeper visible notion, reasoning, and spatial consciousness, enabling sturdy efficiency throughout pictures, video, and lengthy paperwork.
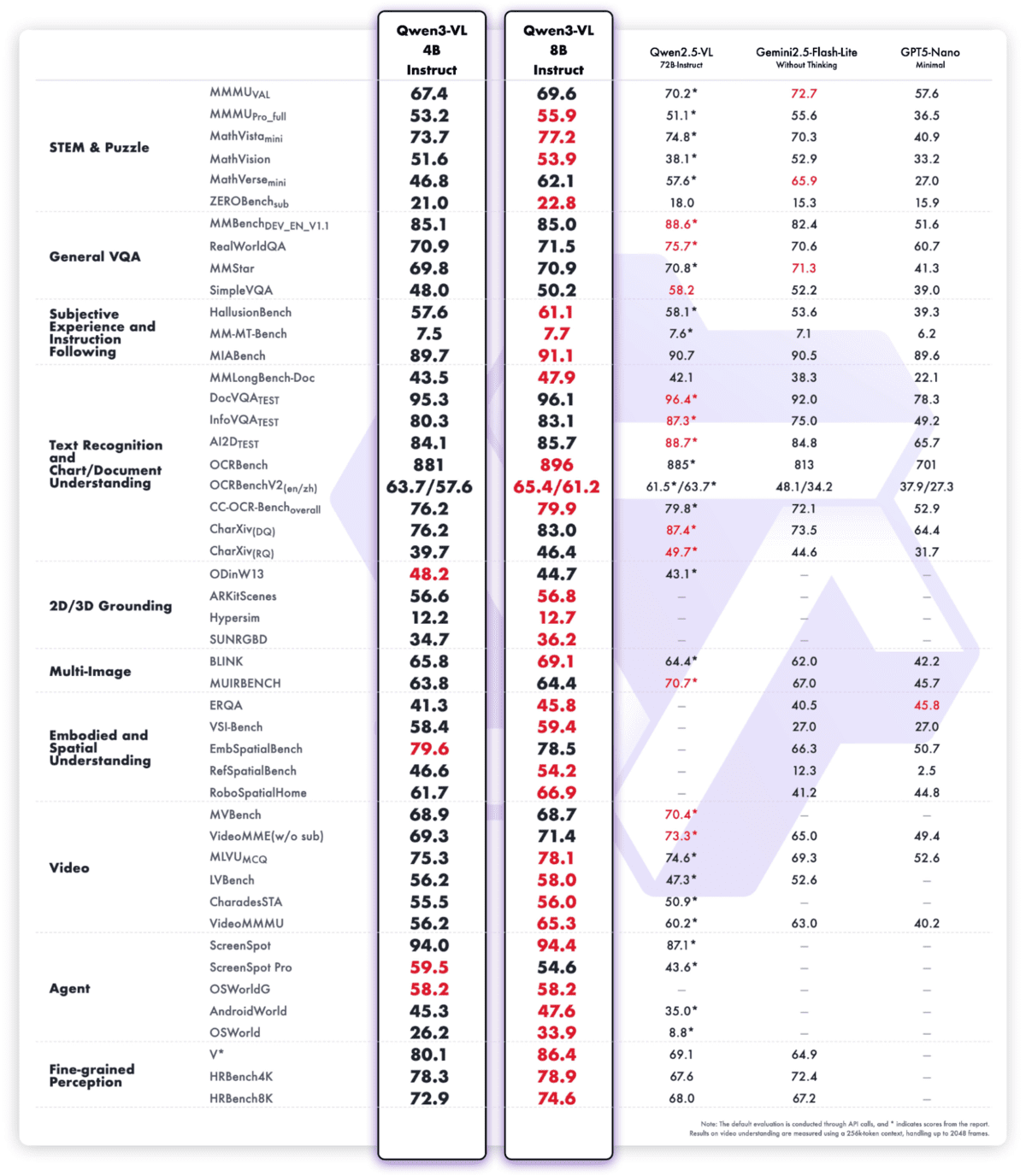
The mannequin helps native 256K context (expandable to 1M), permitting it to course of whole books or hours‑lengthy movies with correct recall and positive‑grained temporal indexing. Architectural upgrades resembling Interleaved‑MRoPE, DeepStack visible fusion, and exact textual content–timestamp alignment considerably enhance lengthy‑horizon video reasoning, positive‑element recognition, and picture–textual content grounding
Past notion, Qwen3‑VL‑4B‑Instruct capabilities as a visible agent, able to working PC and cell GUIs, invoking instruments, producing visible code (HTML/CSS/JS, Draw.io), and dealing with advanced multimodal workflows with reasoning grounded in each textual content and imaginative and prescient.
# 3. Exaone 4.0 1.2B
EXAONE 4.0 1.2B is a compact, on‑system–pleasant language mannequin designed to convey agentic AI and hybrid reasoning into extraordinarily useful resource‑environment friendly deployments. It integrates each non‑reasoning mode for quick, sensible responses and an non-obligatory reasoning mode for advanced drawback fixing, permitting builders to commerce off pace and depth dynamically inside a single mannequin.
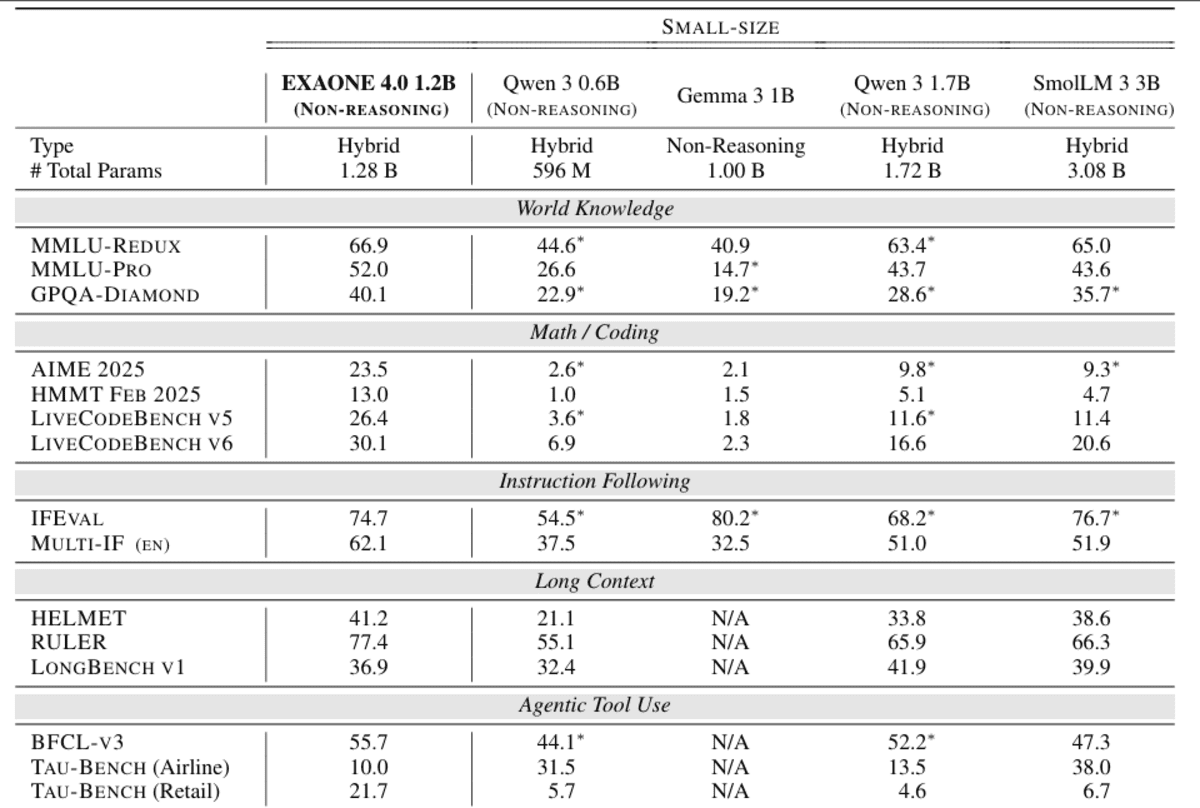
Regardless of its small measurement, the 1.2B variant helps agentic device use, enabling operate calling and autonomous job execution, and affords multilingual capabilities in English, Korean, and Spanish, extending its usefulness past monolingual edge functions.
Architecturally, it inherits EXAONE 4.0’s advances resembling hybrid consideration and improved normalization schemes, whereas supporting a 64K token context size, making it unusually sturdy for lengthy‑context understanding at this scale
Optimized for effectivity, it’s explicitly positioned for on‑system and low‑value inference eventualities, the place reminiscence footprint and latency matter as a lot as mannequin high quality.
# 4. Ministral 3B
Ministral-3-3B-Instruct-2512 is the smallest member of the Ministral 3 household and a extremely environment friendly tiny multimodal language mannequin objective‑constructed for edge and low‑useful resource deployment. It’s an FP8 instruct‑positive‑tuned mannequin, optimized particularly for chat and instruction‑following workloads, whereas sustaining sturdy adherence to system prompts and structured outputs
Architecturally, it combines a 3.4B‑parameter language mannequin with a 0.4B imaginative and prescient encoder, enabling native picture understanding alongside textual content reasoning.

Regardless of its compact measurement, the mannequin helps a big 256K context window, strong multilingual protection throughout dozens of languages, and native agentic capabilities resembling operate calling and JSON output, making it properly fitted to actual‑time, embedded, and distributed AI techniques.
Designed to suit inside 8GB of VRAM in FP8 (and even much less when quantized), Ministral 3 3B Instruct delivers sturdy efficiency per watt and per greenback for manufacturing use circumstances that demand effectivity with out sacrificing functionality
# 5. Jamba Reasoning 3B
Jamba-Reasoning-3B is a compact but exceptionally succesful 3‑billion‑parameter reasoning mannequin designed to ship sturdy intelligence, lengthy‑context processing, and excessive effectivity in a small footprint.
Its defining innovation is a hybrid Transformer–Mamba structure, the place a small variety of consideration layers seize advanced dependencies whereas nearly all of layers use Mamba state‑house fashions for extremely environment friendly sequence processing.

This design dramatically reduces reminiscence overhead and improves throughput, enabling the mannequin to run easily on laptops, GPUs, and even cell‑class units with out sacrificing high quality.
Regardless of its measurement, Jamba Reasoning 3B helps 256K token contexts, scaling to very lengthy paperwork with out counting on large consideration caches, which makes lengthy‑context inference sensible and price‑efficient
On intelligence benchmarks, it outperforms comparable small fashions resembling Gemma 3 4B and Llama 3.2 3B on a mixed rating spanning a number of evaluations, demonstrating unusually sturdy reasoning skill for its class.
# 6. Granite 4.0 Micro
Granite-4.0-micro is a 3B‑parameter lengthy‑context instruct mannequin developed by IBM’s Granite group and designed particularly for enterprise‑grade assistants and agentic workflows.
Tremendous‑tuned from Granite‑4.0‑Micro‑Base utilizing a mix of permissively licensed open datasets and excessive‑high quality artificial knowledge, it emphasizes dependable instruction following, skilled tone, and secure responses, bolstered by a default system immediate added in its October 2025 replace.
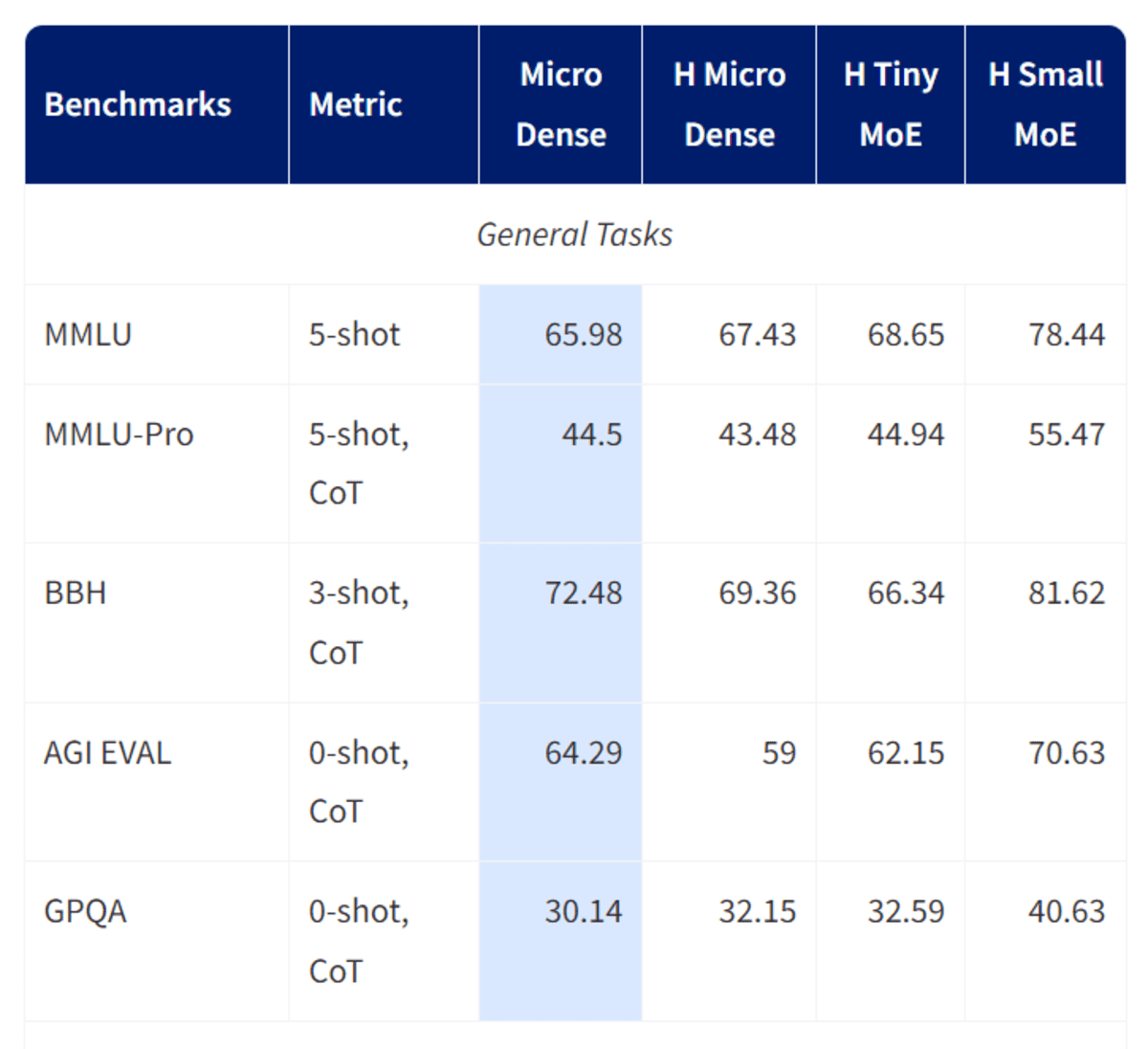
The mannequin helps a really massive 128K context window, sturdy device‑calling and performance‑execution capabilities, and broad multilingual help spanning main European, Center Jap, and East Asian languages.
Constructed on a dense decoder‑solely transformer structure with trendy parts resembling GQA, RoPE, SwiGLU MLPs, and RMSNorm, Granite‑4.0‑Micro balances robustness and effectivity, making it properly suited as a basis mannequin for enterprise functions, RAG pipelines, coding duties, and LLM brokers that should combine cleanly with exterior techniques beneath an Apache 2.0 open‑supply license.
# 7. Phi-4 Mini
Phi-4-mini-instruct is a light-weight, open 3.8B‑parameter language mannequin from Microsoft designed to ship sturdy reasoning and instruction‑following efficiency beneath tight reminiscence and compute constraints.
Constructed on a dense decoder‑solely Transformer structure, it’s skilled totally on excessive‑high quality artificial “textbook‑like” knowledge and punctiliously filtered public sources, with a deliberate emphasis on reasoning‑dense content material over uncooked factual memorization.
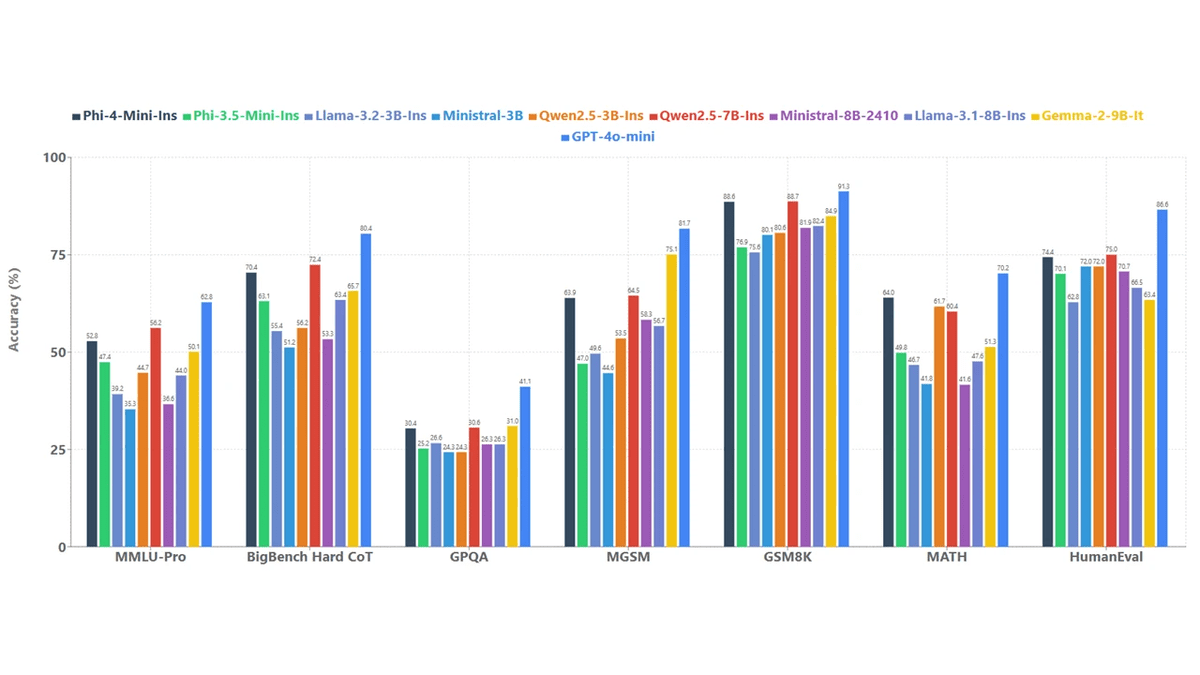
The mannequin helps a 128K token context window, enabling lengthy‑doc understanding and prolonged conversations unusual at this scale.
Publish‑coaching combines supervised positive‑tuning and direct desire optimization, leading to exact instruction adherence, strong security conduct, and efficient operate calling.
With a big 200K‑token vocabulary and broad multilingual protection, Phi‑4‑mini‑instruct is positioned as a sensible constructing block for analysis and manufacturing techniques that should stability latency, value, and reasoning high quality, significantly in reminiscence‑ or compute‑constrained environments.
# Last Ideas
Tiny fashions have reached a degree the place measurement is now not a limitation to functionality. The Qwen 3 sequence stands out on this checklist, delivering efficiency that rivals a lot bigger language fashions and even challenges some proprietary techniques. In case you are constructing functions for a Raspberry Pi or different low-power units, Qwen 3 is a superb place to begin and properly price integrating into your setup.
Past Qwen, the EXAONE 4.0 1.2B fashions are significantly sturdy at reasoning and non-trivial drawback fixing, whereas remaining considerably smaller than most options. The Ministral 3B additionally deserves consideration as the newest launch in its sequence, providing an up to date data cutoff and strong general-purpose efficiency.
General, many of those fashions are spectacular, but when your priorities are pace, accuracy, and power calling, the Qwen 3 LLM and VLM variants are laborious to beat. They clearly present how far tiny, on-device AI has come and why native inference on small {hardware} is now not a compromise.
Abid Ali Awan (@1abidaliawan) is an authorized knowledge scientist skilled who loves constructing machine studying fashions. Presently, he’s specializing in content material creation and writing technical blogs on machine studying and knowledge science applied sciences. Abid holds a Grasp’s diploma in expertise administration and a bachelor’s diploma in telecommunication engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college students fighting psychological sickness.

