

Picture by Creator
As a knowledge skilled, you’re in all probability accustomed to the price of poor information high quality. For all information initiatives—large or small—it’s best to carry out important information high quality checks.
There are devoted libraries and frameworks for information high quality evaluation. However in case you are a newbie, you’ll be able to run easy but vital information high quality checks with pandas. And this tutorial will train you ways.
We’ll use the California Housing Dataset from scikit-learn for this tutorial.
We’ll use the California housing dataset from Scikit-learn’s datasets module. The information set accommodates over 20,000 information of eight numeric options and a goal median home worth.
Let’s learn the dataset right into a pandas dataframe df:
from sklearn.datasets import fetch_california_housing
import pandas as pd
# Fetch the California housing dataset
information = fetch_california_housing()
# Convert the dataset to a Pandas DataFrame
df = pd.DataFrame(information.information, columns=information.feature_names)
# Add goal column
df['MedHouseVal'] = information.goal
For an in depth description of the dataset, run information.DESCR as proven:
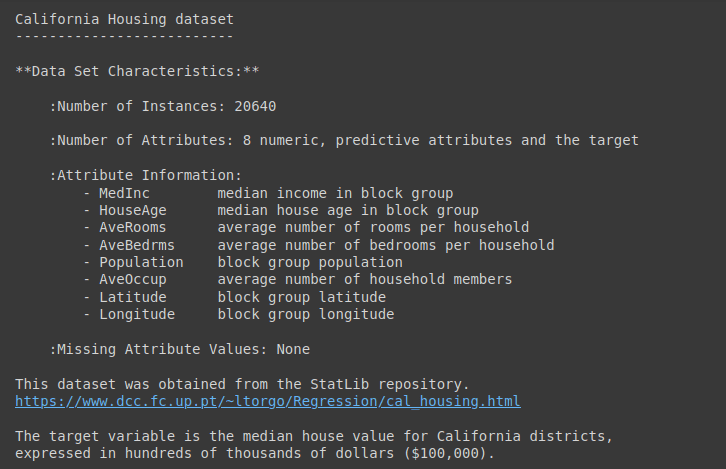
Output of information.DESCR
Let’s get some fundamental data on the dataset:
Right here’s the output:
Output >>>
RangeIndex: 20640 entries, 0 to 20639
Knowledge columns (complete 9 columns):
# Column Non-Null Rely Dtype
--- ------ -------------- -----
0 MedInc 20640 non-null float64
1 HouseAge 20640 non-null float64
2 AveRooms 20640 non-null float64
3 AveBedrms 20640 non-null float64
4 Inhabitants 20640 non-null float64
5 AveOccup 20640 non-null float64
6 Latitude 20640 non-null float64
7 Longitude 20640 non-null float64
8 MedHouseVal 20640 non-null float64
dtypes: float64(9)
reminiscence utilization: 1.4 MB
As a result of we have now numeric options, allow us to additionally get the abstract begins utilizing the describe() technique:
Output of df.describe()
Actual-world datasets usually have lacking values. To investigate the info and construct fashions, it’s worthwhile to deal with these lacking values.
To make sure information high quality, it’s best to examine if the fraction of lacking values is inside a particular tolerance restrict. You’ll be able to then impute the lacking values utilizing appropriate imputation methods.
Step one, subsequently, is to examine for lacking values throughout all options within the dataset.
This code checks for lacking values in every column of the dataframe df:
# Test for lacking values within the DataFrame
missing_values = df.isnull().sum()
print("Lacking Values:")
print(missing_values)
The result’s a pandas sequence that exhibits the rely of lacking values for every column:
Output >>>
Lacking Values:
MedInc 0
HouseAge 0
AveRooms 0
AveBedrms 0
Inhabitants 0
AveOccup 0
Latitude 0
Longitude 0
MedHouseVal 0
dtype: int64
As seen, there aren’t any lacking values on this dataset.
Duplicate information within the dataset can skew evaluation. So it’s best to examine for and drop the duplicate information as wanted.
Right here’s the code to establish and return duplicate rows in df. If there are any duplicate rows, they are going to be included within the end result:
# Test for duplicate rows within the DataFrame
duplicate_rows = df[df.duplicated()]
print("Duplicate Rows:")
print(duplicate_rows)
The result’s an empty dataframe. Which means there aren’t any duplicate information within the dataset:
Output >>>
Duplicate Rows:
Empty DataFrame
Columns: [MedInc, HouseAge, AveRooms, AveBedrms, Population, AveOccup, Latitude, Longitude, MedHouseVal]
Index: []
When analyzing a dataset, you’ll usually have to remodel or scale a number of options. To keep away from surprising errors when performing such operations, it is very important examine if the columns are all the anticipated information sort.
This code checks the info varieties of every column within the dataframe df:
# Test information varieties of every column within the DataFrame
data_types = df.dtypes
print("Knowledge Sorts:")
print(data_types)
Right here, all numeric options are of float information sort as anticipated:
Output >>>
Knowledge Sorts:
MedInc float64
HouseAge float64
AveRooms float64
AveBedrms float64
Inhabitants float64
AveOccup float64
Latitude float64
Longitude float64
MedHouseVal float64
dtype: object
Outliers are information factors which might be considerably completely different from different factors within the dataset. If you happen to bear in mind, we ran the describe() technique on the dataframe.
Based mostly on the quartile values and the utmost worth, you would’ve recognized {that a} subset of options include outliers. Particularly, these options:
- MedInc
- AveRooms
- AveBedrms
- Inhabitants
One strategy to dealing with outliers is to make use of the interquartile vary, the distinction between the seventy fifth and twenty fifth quartiles. If Q1 is the twenty fifth quartile and Q3 is the seventy fifth quartile, then the interquartile vary is given by: Q3 – Q1.
We then use the quartiles and the IQR to outline the interval [Q1 - 1.5 * IQR, Q3 + 1.5 * IQR]. And all factors exterior this vary are outliers.
columns_to_check = ['MedInc', 'AveRooms', 'AveBedrms', 'Population']
# Operate to search out information with outliers
def find_outliers_pandas(information, column):
Q1 = information[column].quantile(0.25)
Q3 = information[column].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = information[(data[column] < lower_bound) | (information[column] > upper_bound)]
return outliers
# Discover information with outliers for every specified column
outliers_dict = {}
for column in columns_to-check:
outliers_dict[column] = find_outliers_pandas(df, column)
# Print the information with outliers for every column
for column, outliers in outliers_dict.gadgets():
print(f"Outliers in '{column}':")
print(outliers)
print("n")
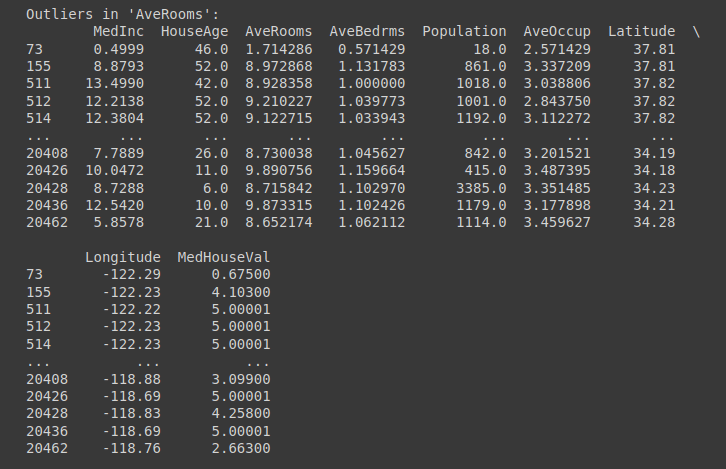
Outliers in ‘AveRooms’ Column | Truncated Output for Outliers Test
An vital examine for numeric options is to validate the vary. This ensures that every one observations of a characteristic tackle values in an anticipated vary.
This code validates that the ‘MedInc’ worth falls inside an anticipated vary and identifies information factors that don’t meet this standards:
# Test numerical worth vary for the 'MedInc' column
valid_range = (0, 16)
value_range_check = df[~df['MedInc'].between(*valid_range)]
print("Worth Vary Test (MedInc):")
print(value_range_check)
You’ll be able to strive for different numeric options of your selection. However we see that every one values within the ‘MedInc’ column lie within the anticipated vary:
Output >>>
Worth Vary Test (MedInc):
Empty DataFrame
Columns: [MedInc, HouseAge, AveRooms, AveBedrms, Population, AveOccup, Latitude, Longitude, MedHouseVal]
Index: []
Most information units include associated options. So it is vital to incorporate checks primarily based on logically related relationships between columns (or options).
Whereas options—individually—might tackle values within the anticipated vary, the connection between them could also be inconsistent.
Right here is an instance for our dataset. In a legitimate file, the ‘AveRooms’ ought to sometimes be higher than or equal to the ‘AveBedRms’.
# AveRooms shouldn't be smaller than AveBedrooms
invalid_data = df[df['AveRooms'] < df['AveBedrms']]
print("Invalid Information (AveRooms < AveBedrms):")
print(invalid_data)
Within the California housing dataset we’re working with, we see that there aren’t any such invalid information:
Output >>>
Invalid Information (AveRooms < AveBedrms):
Empty DataFrame
Columns: [MedInc, HouseAge, AveRooms, AveBedrms, Population, AveOccup, Latitude, Longitude, MedHouseVal]
Index: []
Inconsistent information entry is a standard information high quality situation in most datasets. Examples embody:
- Inconsistent formatting in datetime columns
- Inconsistent logging of categorical variable values
- Recording of studying in numerous models
In our dataset, we’ve verified the info varieties of columns and have recognized outliers. However you may also run checks for inconsistent information entry.
Let’s whip up a easy instance to examine if all of the date entries have a constant formatting.
Right here we use common expressions along with pandas apply() perform to examine if all date entries are within the YYYY-MM-DD format:
import pandas as pd
import re
information = {'Date': ['2023-10-29', '2023-11-15', '23-10-2023', '2023/10/29', '2023-10-30']}
df = pd.DataFrame(information)
# Outline the anticipated date format
date_format_pattern = r'^d{4}-d{2}-d{2}$' # YYYY-MM-DD format
# Operate to examine if a date worth matches the anticipated format
def check_date_format(date_str, date_format_pattern):
return re.match(date_format_pattern, date_str) isn't None
# Apply the format examine to the 'Date' column
date_format_check = df['Date'].apply(lambda x: check_date_format(x, date_format_pattern))
# Determine and retrieve entries that don't observe the anticipated format
non_adherent_dates = df[~date_format_check]
if not non_adherent_dates.empty:
print("Entries that don't observe the anticipated format:")
print(non_adherent_dates)
else:
print("All dates are within the anticipated format.")
This returns the entries that don’t observe the anticipated format:
Output >>>
Entries that don't observe the anticipated format:
Date
2 23-10-2023
3 2023/10/29
On this tutorial, we went over widespread information high quality checks with pandas.
When you find yourself engaged on smaller information evaluation initiatives, these information high quality checks with pandas are start line. Relying on the issue and the dataset, you’ll be able to embody further checks.
If you happen to’re desirous about studying information evaluation, take a look at the information 7 Steps to Mastering Knowledge Wrangling with Pandas and Python.
Bala Priya C is a developer and technical author from India. She likes working on the intersection of math, programming, information science, and content material creation. Her areas of curiosity and experience embody DevOps, information science, and pure language processing. She enjoys studying, writing, coding, and low! Presently, she’s engaged on studying and sharing her data with the developer neighborhood by authoring tutorials, how-to guides, opinion items, and extra.

