

Picture by Editor
30 years of KDnuggets and 30 years of information science. Roughly 30 years of my skilled life. One of many privileges that comes with working in the identical area for a very long time – aka expertise – is the prospect to jot down about its evolution, as a direct eye witness.
I began working originally of the 90s on what was then known as Synthetic Intelligence, referring to a brand new paradigm that was self-learning, mimicking organizations of nervous cells, and that didn’t require any statistical speculation to be verified: sure, neural networks! An environment friendly utilization of the Again-Propagation algorithm had been printed only a few years earlier [1], fixing the issue of coaching hidden layers in multilayer neural networks, enabling armies of enthusiastic college students to deal with new options to quite a few previous use instances. Nothing might have stopped us … simply the machine energy.
Coaching a multilayer neural community requires fairly some computational energy, particularly if the variety of community parameters is excessive and the dataset is massive. Computational energy, that the machines on the time didn’t have. Theoretical frameworks have been developed, like Again-Propagation Via Time (BPTT) in 1988 [2] for time collection or Lengthy Quick Time period Recollections (LSTM) [3] in 1997 for selective reminiscence studying. Nonetheless, computational energy remained a difficulty and neural networks have been parked by most information analytics practitioners, ready for higher occasions.
Within the meantime, leaner and sometimes equally performing algorithms appeared. Determination bushes within the type of C4.5 [4] turned in style in 1993, regardless that within the CART [5] kind had already been round since 1984. Determination bushes have been lighter to coach, extra intuitive to grasp, and sometimes carried out effectively sufficient on the datasets of the time. Quickly, we additionally realized to mix many resolution bushes collectively as a forest [6], within the random forest algorithm, or as a cascade [7] [8], within the gradient boosted bushes algorithm. Although these fashions are fairly massive, that’s with a lot of parameters to coach, they have been nonetheless manageable in an affordable time. Particularly the gradient boosted bushes, with its cascade of bushes skilled in sequence, diluted the required computational energy over time, making it a really inexpensive and really profitable algorithm for information science.
Until the tip of the 90s, all datasets have been basic datasets of affordable dimension: buyer information, affected person information, transactions, chemistry information, and so forth. Mainly, basic enterprise operations information. With the growth of social media, ecommerce, and streaming platforms, information began to develop at a a lot quicker tempo, posing fully new challenges. Initially, the problem of storage and quick entry for such massive quantities of structured and unstructured information. Secondly, the necessity for quicker algorithms for his or her evaluation. Massive information platforms took care of storage and quick entry. Conventional relational databases internet hosting structured information left house to new information lakes internet hosting all types of information. As well as, the growth of ecommerce companies propelled the recognition of advice engines. Both used for market basket evaluation or for video streaming suggestions, two of such algorithms turned generally used: the apriori algorithm [9] and the collaborative filtering algorithm [10].
Within the meantime, efficiency of pc {hardware} improved reaching unimaginable pace and … we’re again to the neural networks. GPUs began getting used as accelerators for the execution of particular operations in neural community coaching, permitting for an increasing number of advanced neural algorithms and neural architectures to be created, skilled, and deployed. This second youth of neural networks took on the identify of deep studying [11] [12]. The time period Synthetic Intelligence (AI) began resurfacing.
A aspect department of deep studying, generative AI [13], centered on producing new information: numbers, texts, photographs, and even music. Fashions and datasets stored rising in dimension and complexity to realize the technology of extra sensible photographs, texts, and human-machine interactions.
New fashions and new information have been rapidly substituted by new fashions and new information in a steady cycle. It turned an increasing number of an engineering downside somewhat than a knowledge science downside. Not too long ago, resulting from an admirable effort in information and machine studying engineering, computerized frameworks have been developed for steady information assortment, mannequin coaching, testing, human within the loop actions, and eventually deployment of very massive machine studying fashions. All this engineering infrastructure is on the foundation of the present Giant Language Fashions (LLMs), skilled to offer solutions to a wide range of issues whereas simulating a human to human interplay.
Greater than across the algorithms, the most important change in information science within the final years, for my part, has taken place within the underlying infrastructure: from frequent information acquisition to steady clean retraining and redeployment of fashions. That’s, there was a shift in information science from a analysis self-discipline into an engineering effort.
The life cycle of a machine studying mannequin has modified from a single cycle of pure creation, coaching, testing, and deployment, like CRISP-DM [14] and different comparable paradigms, to a double cycle masking creation on one aspect and productionisation – deployment, validation, consumption, and upkeep – on the opposite aspect [15].
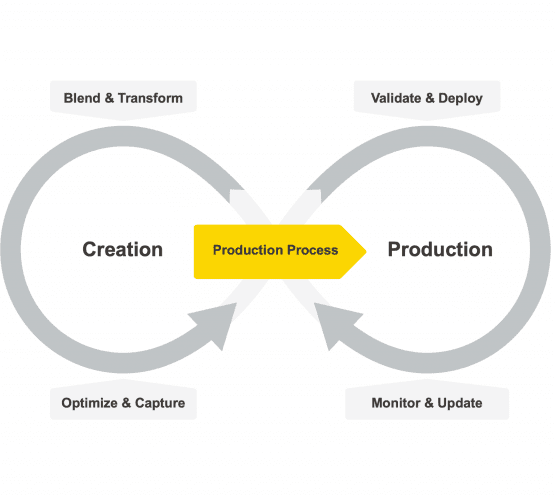
Fig. 1 The life cycle of a machine studying mannequin
Consequently, information science instruments needed to adapt. They needed to begin supporting not solely the creation section but additionally the productionization section of a machine studying mannequin. There needed to be two merchandise or two separate components throughout the identical product: one to help the consumer within the creation and coaching of a knowledge science mannequin and one to permit for a clean and error-free productionisation of the ultimate end result. Whereas the creation half remains to be an train of the mind, the productionisation half is a structured repetitive activity.
Clearly for the creation section, information scientists want a platform with intensive protection of machine studying algorithms, from the fundamental ones to essentially the most superior and complex ones. You by no means know which algorithm you will have to resolve which downside. After all, essentially the most highly effective fashions have a better probability of success, that comes on the value of a better danger of overfitting and slower execution. Information scientists ultimately are like artisans who want a field full of various instruments for the various challenges of their work.
Low code based mostly platforms have additionally gained recognition, since low code allows programmers and even non-programmers to create and rapidly replace all types of information science purposes.
As an train of the mind, the creation of machine studying fashions ought to be accessible to everyone. Because of this, although not strictly obligatory, an open supply platform for information science could be fascinating. Open-source permits free entry to information operations and machine studying algorithms to all aspiring information scientists and on the identical time permits the group to analyze and contribute to the supply code.
On the opposite aspect of the cycle, productionization requires a platform that gives a dependable IT framework for deployment, execution, and monitoring of the ready-to-go information science software.
Summarizing 30 years of information science evolution in lower than 2000 phrases is after all unattainable. As well as, I quoted the most well-liked publications on the time, regardless that they may not have been absolutely the first ones on the subject. I apologize already for the various algorithms that performed an necessary position on this course of and that I didn’t point out right here. However, I hope that this quick abstract offers you a deeper understanding of the place and why we are actually within the house of information science 30 years later!
[1] Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. (1986). “Studying representations by back-propagating errors”. Nature, 323, p. 533-536.
[2] Werbos, P.J. (1988). “Generalization of backpropagation with software to a recurrent gasoline market mannequin”. Neural Networks. 1 (4): 339–356. doi:10.1016/0893-6080(88)90007
[3] Hochreiter, S.; Schmidhuber, J. (1997). “Lengthy Quick-Time period Reminiscence”. Neural Computation. 9 (8): 1735–1780.
[4] Quinlan, J. R. (1993). “C4.5: Applications for Machine Studying” Morgan Kaufmann Publishers.
[5] Breiman, L. ; Friedman, J.; Stone, C.J.; Olshen, R.A. (1984) “Classification and Regression Timber”, Routledge. https://doi.org/10.1201/9781315139470
[6] Ho, T.Okay. (1995). Random Determination Forests. Proceedings of the third Worldwide Convention on Doc Evaluation and Recognition, Montreal, QC, 14–16 August 1995. pp. 278–282
[7] Friedman, J. H. (1999). “Grasping Perform Approximation: A Gradient Boosting Machine, Reitz Lecture
[8] Mason, L.; Baxter, J.; Bartlett, P. L.; Frean, Marcus (1999). “Boosting Algorithms as Gradient Descent”. In S.A. Solla and T.Okay. Leen and Okay. Müller (ed.). Advances in Neural Data Processing Methods 12. MIT Press. pp. 512–518
[9] Agrawal, R.; Srikant, R (1994) Quick algorithms for mining affiliation guidelines. Proceedings of the twentieth Worldwide Convention on Very Giant Information Bases, VLDB, pages 487-499, Santiago, Chile, September 1994.
[10] Breese, J.S.; Heckerman, D,; Kadie C. (1998) “Empirical Evaluation of Predictive Algorithms for Collaborative Filtering”, Proceedings of the Fourteenth Convention on Uncertainty in Synthetic Intelligence (UAI1998)
[11] Ciresan, D.; Meier, U.; Schmidhuber, J. (2012). “Multi-column deep neural networks for picture classification”. 2012 IEEE Convention on Laptop Imaginative and prescient and Sample Recognition. pp. 3642–3649. arXiv:1202.2745. doi:10.1109/cvpr.2012.6248110. ISBN 978-1-4673-1228-8. S2CID 2161592.
[12] Krizhevsky, A.; Sutskever, I.; Hinton, G. (2012). “ImageNet Classification with Deep Convolutional Neural Networks”. NIPS 2012: Neural Data Processing Methods, Lake Tahoe, Nevada.
[13] Hinton, G.E.; Osindero, S.; Teh, Y.W. (2006) ”A Quick Studying Algorithm for Deep Perception Nets”. Neural Comput 2006; 18 (7): 1527–1554. doi: https://doi.org/10.1162/neco.2006.18.7.1527
[14] Wirth, R.; Jochen, H.. (2000) “CRISP-DM: In the direction of a Commonplace Course of Mannequin for Information Mining.” Proceedings of the 4th worldwide convention on the sensible purposes of data discovery and information mining (4), pp. 29–39.
[15] Berthold, R.M. (2021) “The way to transfer information science into manufacturing”, KNIME Weblog
Rosaria Silipo just isn’t solely an skilled in information mining, machine studying, reporting, and information warehousing, she has grow to be a acknowledged skilled on the KNIME information mining engine, about which she has printed three books: KNIME Newbie’s Luck, The KNIME Cookbook, and The KNIME Booklet for SAS Customers. Beforehand Rosaria labored as a contract information analyst for a lot of corporations all through Europe. She has additionally led the SAS improvement group at Viseca (Zürich), applied the speech-to-text and text-to-speech interfaces in C# at Spoken Translation (Berkeley, California), and developed quite a few speech recognition engines in numerous languages at Nuance Communications (Menlo Park, California). Rosaria gained her doctorate in biomedical engineering in 1996 from the College of Florence, Italy.

