

Meta Superintelligence Labs not too long ago made a major transfer by unveiling ‘Muse Spark’ — the primary mannequin within the Muse household. Muse Spark is a natively multimodal reasoning mannequin with assist for tool-use, visible chain of thought, and multi-agent orchestration.
What ‘Natively Multimodal’ Truly Means
When Meta describes Muse Spark as ‘natively multimodal,’ it means the mannequin was skilled from the bottom as much as course of and purpose throughout textual content and visible inputs concurrently — not a imaginative and prescient module bolted onto a language mannequin after the actual fact. Muse Spark is constructed from the bottom as much as combine visible info throughout domains and instruments, attaining robust efficiency on visible STEM questions, entity recognition, and localization.
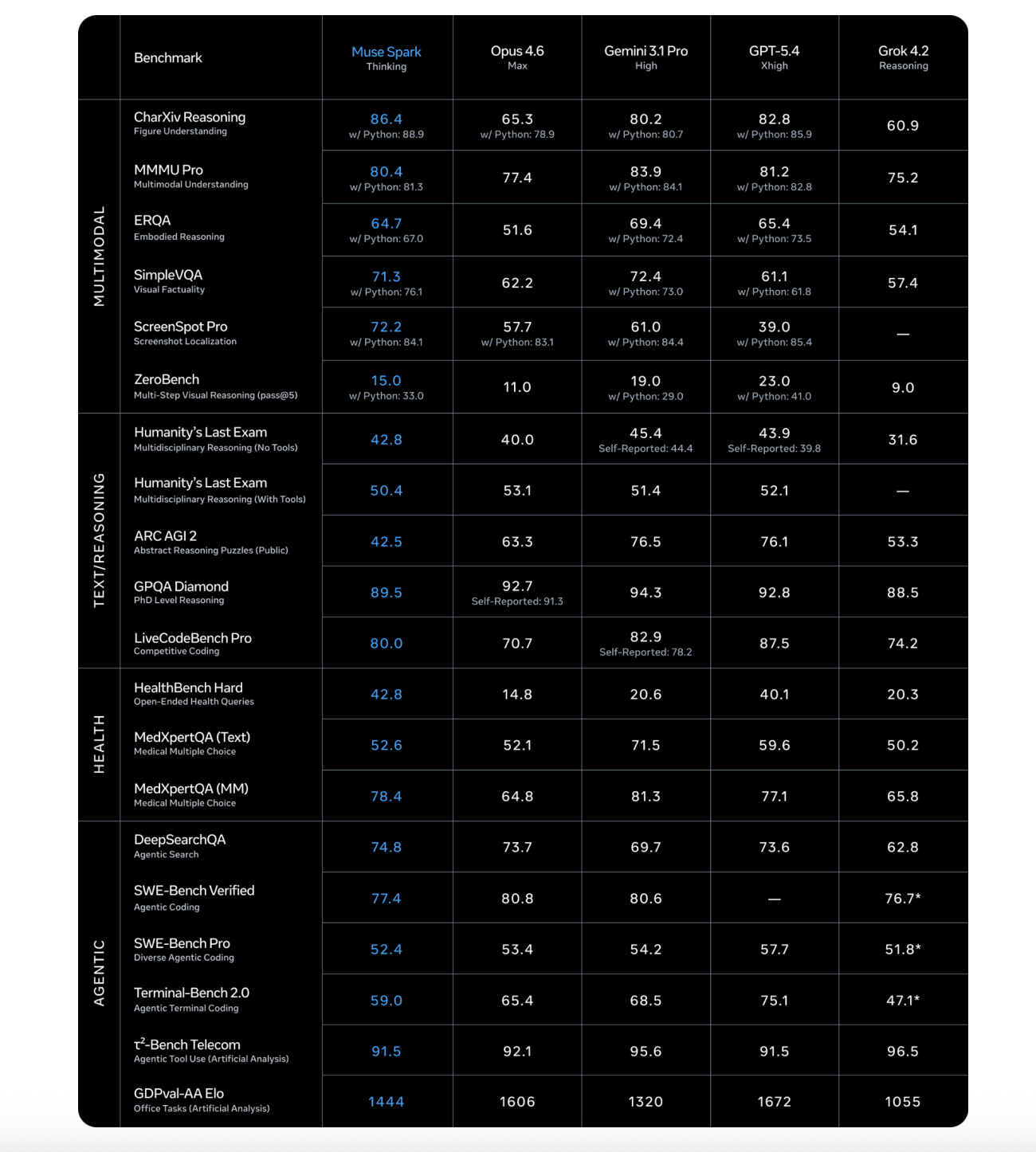
This architectural selection has actual penalties on duties that mix language and imaginative and prescient. On the ScreenSpot Professional benchmark — which assessments screenshot localization, requiring the mannequin to establish particular UI components in pictures — Muse Spark scores 72.2 (84.1 with Python instruments), in comparison with Claude Opus 4.6 Max’s 57.7 (83.1 with Python) and GPT-5.4 Xhigh’s 39.0 (85.4 with Python).
Three Scaling Axes: Pretraining, RL, and Check-Time Reasoning
Essentially the most technically attention-grabbing a part of the Muse Spark announcement is Meta’s specific framing round three scaling axes — the levers they’re pulling to enhance mannequin functionality in a predictable and measurable method. To assist additional scaling throughout all three, Meta is making strategic investments throughout all the stack — from analysis and mannequin coaching to infrastructure, together with the Hyperion knowledge heart.
Pretraining is the place the mannequin learns its core world data, reasoning, and coding talents. During the last 9 months, Meta rebuilt its pretraining stack with enhancements to mannequin structure, optimization, and knowledge curation. The payoff is substantial effectivity positive factors: Meta can attain the identical capabilities with over an order of magnitude much less compute than its earlier mannequin, Llama 4 Maverick. For devs, ‘an order of magnitude’ means roughly 10x extra compute-efficient — a significant enchancment that makes bigger future fashions extra financially and virtually viable.
Reinforcement Studying (RL) is the second axis. After pretraining, RL is utilized to amplify capabilities by coaching the mannequin on outcome-based suggestions quite than simply token prediction. Consider it this manner: pretraining teaches the mannequin info and patterns; RL teaches it to truly get solutions proper. Though large-scale RL is notoriously vulnerable to instability, Meta’s new stack delivers easy, predictable positive factors. The analysis staff experiences log-linear development in move@1 and move@16 on coaching knowledge, meaning the mannequin improves constantly as RL compute scales. move@1 means the mannequin will get the reply proper on its first attempt; move@16 means a minimum of one success throughout 16 makes an attempt — a measure of reasoning range.
Check-Time Reasoning is the third axis. This refers back to the compute the mannequin makes use of at inference time — the interval when it’s truly producing a solution for a consumer. Muse Spark is skilled to ‘suppose’ earlier than it responds, a course of Meta’s analysis staff calls test-time reasoning. To ship probably the most intelligence per token, RL coaching maximizes correctness topic to a penalty on considering time. This produces a phenomenon the analysis staff calls thought compression: after an preliminary interval the place the mannequin improves by considering longer, the size penalty causes thought compression — Muse Spark compresses its reasoning to resolve issues utilizing considerably fewer tokens. After compressing, the mannequin then extends its options once more to attain stronger efficiency.
Considering Mode: Multi-Agent Orchestration at Inference
Maybe probably the most architecturally attention-grabbing characteristic is Considering mode. The analysis staff describes it as a novel multi-round test-time scaling scaffold protecting answer era, iterative self-refinement, and aggregation. In plain phrases: as an alternative of 1 mannequin producing one reply, a number of brokers run in parallel, every producing options which are then refined and aggregated right into a ultimate output.
Whereas commonplace test-time scaling has a single agent suppose for longer, scaling Muse Spark with multi-agent considering allows superior efficiency with comparable latency. It is a key engineering trade-off: latency scales with the depth of a single chain of thought, however parallel brokers can add functionality with out proportionally including wait time.
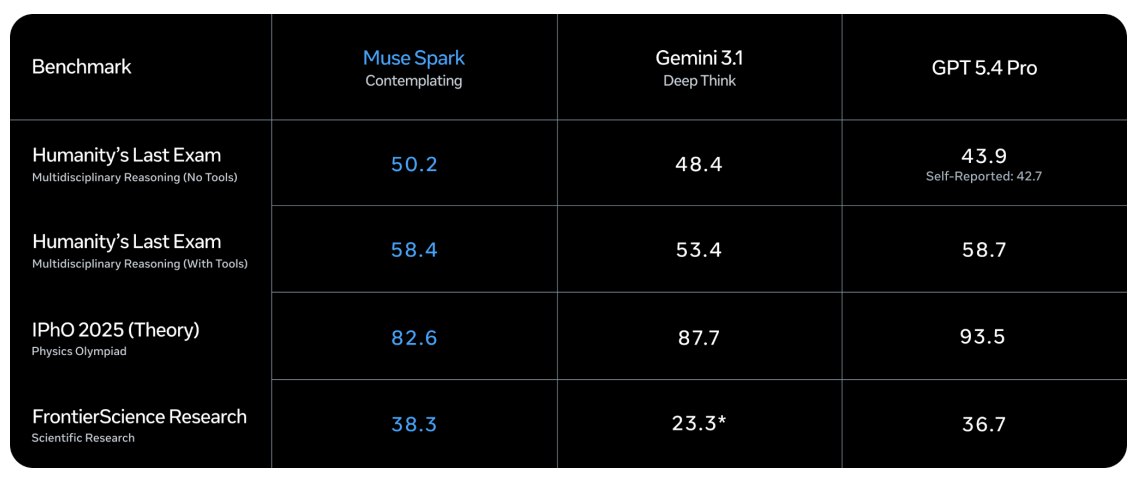
In Considering mode, Muse Spark scores 58.4 on Humanity’s Final Examination With Instruments — a benchmark designed to check expert-level multidisciplinary data — in comparison with Gemini 3.1 Deep Suppose’s 53.4 and GPT-5.4 Professional’s 58.7. On FrontierScience Analysis, Muse Spark Considering reaches 38.3, forward of GPT-5.4 Professional’s 36.7 and Gemini 3.1 Deep Suppose’s 23.3.
The place Muse Spark Leads — and The place It Trails
On well being benchmarks, Muse Spark posts its most decisive outcomes. On HealthBench Laborious — a subset of 1,000 open-ended well being queries — Muse Spark scores 42.8, in comparison with Claude Opus 4.6 Max’s 14.8, Gemini 3.1 Professional Excessive’s 20.6, and GPT-5.4 Xhigh’s 40.1. This isn’t simply luck: to enhance Muse Spark’s well being reasoning capabilities, Meta’s analysis staff collaborated with over 1,000 physicians to curate coaching knowledge that permits extra factual and complete responses.
On coding benchmarks, the image is extra aggressive. On SWE-Bench Verified, the place fashions should resolve actual GitHub points utilizing a bash device and file operation device in a single-attempt setup averaged over 15 makes an attempt per drawback, Muse Spark scores 77.4 — behind Claude Opus 4.6 Max at 80.8 and Gemini 3.1 Professional Excessive at 80.6. On GPQA Diamond, a PhD-level reasoning benchmark averaged over 4 runs to scale back variance, Muse Spark scores 89.5, behind Claude Opus 4.6 Max’s 92.7 and Gemini 3.1 Professional Excessive’s 94.3.
The sharpest hole seems on ARC AGI 2, the summary reasoning puzzles benchmark run on a public set of 120 prompts reported at move@2. Muse Spark scores 42.5 — meaningfully behind Gemini 3.1 Professional Excessive at 76.5 and GPT-5.4 Xhigh at 76.1. That is the clearest present weak spot in Muse Spark’s profile.
Key Takeaways
- Meta’s recent begin, not an iteration: Muse Spark is the primary mannequin from the newly fashioned Meta Superintelligence Labs — constructed on a totally rebuilt pretraining stack that’s over 10x extra compute-efficient than Llama 4 Maverick, signaling a deliberate ground-up reset of Meta’s AI technique.
- Well being is the headline benchmark win: Muse Spark’s most decisive benefit over opponents is in well being reasoning — scoring 42.8 on HealthBench Laborious versus Claude Opus 4.6 Max’s 14.8 and Gemini 3.1 Professional Excessive’s 20.6, backed by coaching knowledge curated with over 1,000 physicians.
- Considering mode trades parallel compute for decrease latency: As a substitute of constructing a single mannequin suppose longer — which will increase response time — Muse Spark’s Considering mode runs a number of brokers in parallel that refine and mixture solutions, attaining aggressive efficiency on arduous reasoning duties with out proportionally larger latency.
- Summary reasoning is the clearest weak spot. On ARC AGI 2, Muse Spark scores 42.5 in opposition to Gemini 3.1 Professional Excessive’s 76.5 and GPT-5.4 Xhigh’s 76.1 — the most important efficiency hole in all the benchmark desk.
Try the Technical particulars and Paper. Additionally, be happy to observe us on Twitter and don’t neglect to hitch our 120k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be a part of us on telegram as nicely.
Must associate with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and many others.? Join with us

