

Coaching AI brokers that may really use a pc — opening apps, clicking buttons, looking the net, writing code — is among the hardest infrastructure issues in fashionable AI. It’s not an information downside. It’s not a mannequin downside. It’s a plumbing downside.
You might want to spin up tons of, doubtlessly hundreds, of full working system environments with precise graphical consumer interfaces. Each must run actual software program. Each must deal with unpredictable crashes. And also you want all of them to run concurrently at a price that doesn’t bankrupt a college analysis lab.
That’s the issue ‘OSGym‘, a brand new analysis from a staff of researchers at MIT, UIUC, CMU, USC, UVA, and UC Berkeley, is designed to resolve.
What’s a Pc Use Agent?
Earlier than unpacking the infrastructure, it helps to know what a pc use agent really is. Not like a chatbot that responds to textual content prompts, a pc use agent observes a screenshot of a desktop, decides what to do — click on a button, sort textual content, open a file — and executes that motion by means of keyboard and mouse inputs. Consider it as an AI that may function any software program the way in which a human would.
Fashions like Anthropic’s Claude Pc Use and OpenAI’s Operator are early business examples. Analysis fashions like UI-TARS, Agent-S2, and CogAgent are pushing the boundaries additional. However coaching any of those methods requires large quantities of interplay knowledge generated inside actual OS environments — and that’s the place issues get costly and complex quick.
The Core Drawback: OS Sandboxes at Scale
A coding setting or an online browser sandbox is comparatively light-weight to run. A full OS sandbox with a GUI will not be. Every digital machine wants its personal bootable disk (round 24 GB), its personal CPU and RAM allocation, and its personal show stack. Multiply that by tons of or hundreds of parallel situations and you’ve got a useful resource consumption downside that typical tutorial compute budgets merely can not take in.
On high of useful resource prices, there’s the reliability downside. Software program crashes. Browser classes outing. Functions freeze. In case your coaching pipeline doesn’t deal with these failures gracefully, one dangerous VM can stall a complete coaching batch.
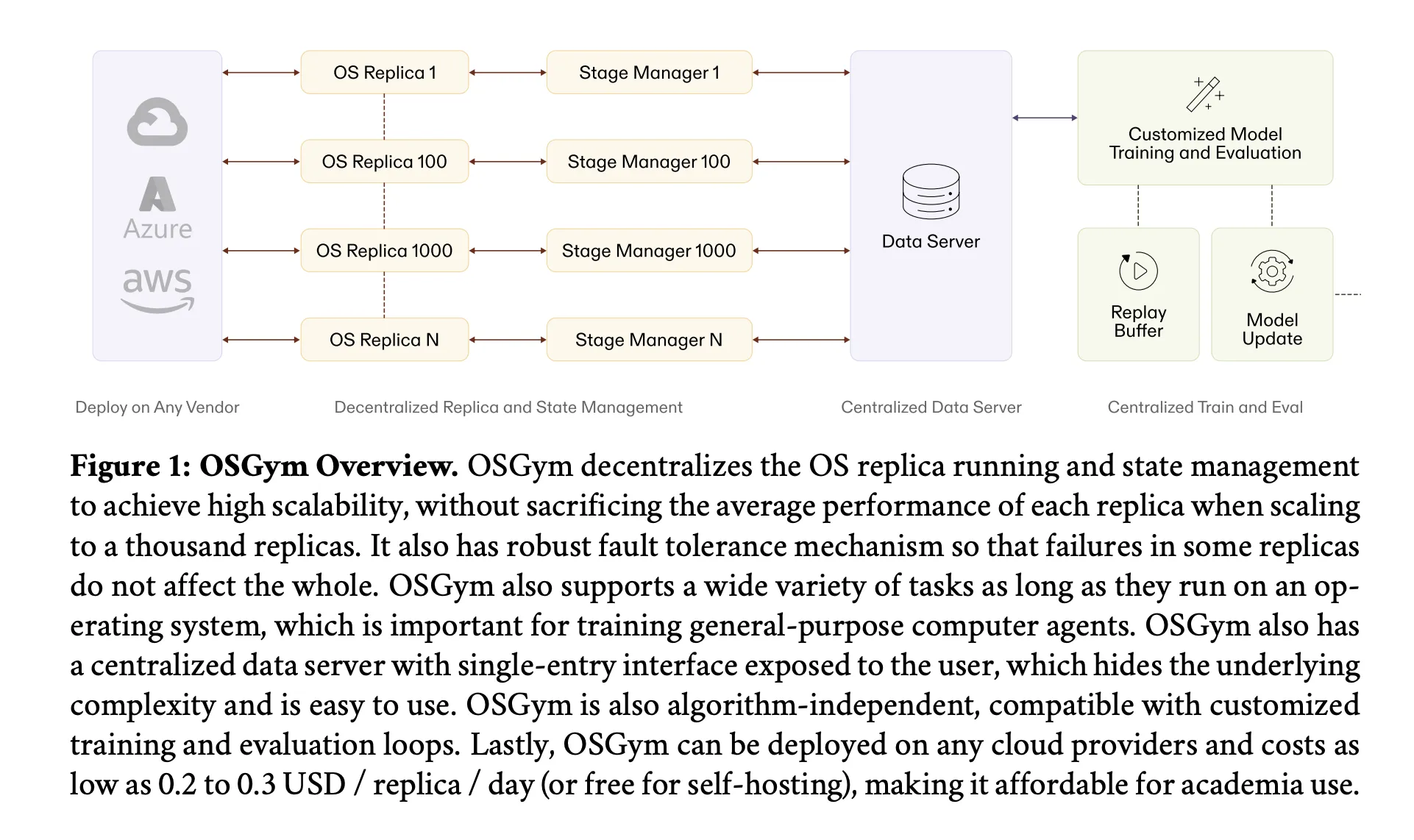
OSGym tackles each issues with 4 distinct architectural optimizations.
Decentralized OS State Administration
The primary design selection issues how the system manages the state of every OS reproduction — monitoring whether or not it’s wholesome, what activity it’s operating, and the best way to get better it if one thing goes unsuitable.
A naive method makes use of a single centralized supervisor for all replicas. This can be a traditional single level of failure: as reproduction rely grows into the hundreds, the central supervisor turns into overwhelmed, latency will increase, and one crash can halt the entire system. OSGym as a substitute offers each OS reproduction its personal devoted state supervisor. Every state supervisor exposes public strategies modeled after the OpenAI Gymnasium API — reset, step, and shutdown — however handles its personal well being monitoring and crash restoration internally. A failure in a single reproduction can not propagate to another.
{Hardware}-Conscious OS Reproduction Orchestration
Right here’s a non-obvious perception this analysis surfaces: while you run many OS replicas on a single server, the bottleneck depends upon what number of replicas you pack per machine. For a small variety of replicas per server (low Okay), the system is CPU-bounded — most replicas are combating over processor time. However as you pack extra replicas per server (massive Okay), the bottleneck shifts to RAM — and RAM is dramatically cheaper than CPU.
A 32 GB DDR4 RAM module sometimes prices 10–20% of what a 16-core CPU prices. OSGym runs replicas as Docker containers (utilizing Docker pictures from OSWorld as a basis) somewhat than full Digital Machines to cut back per-replica overhead. By selecting servers with greater RAM capability and operating extra replicas per machine, the each day price drops from round $300 for 128 replicas at Okay=1, to roughly $30 at Okay=64 — roughly $0.234 per reproduction per day, a quantity that matches comfortably inside many tutorial grant budgets.
KVM Virtualization with Copy-on-Write Disk Administration
The disk provisioning downside is solved with a filesystem approach known as reflink copy-on-write (CoW). Usually, spinning up 128 VM situations would imply duplicating a 24 GB base picture 128 occasions — over 3 TB of storage and 30 seconds of provisioning time per VM.
OSGym as a substitute makes use of cp --reflink=at all times on XFS-formatted NVMe drives. Every per-VM disk picture shares bodily disk blocks with the bottom picture and solely allocates new blocks when the VM really writes to them. The outcome: 128 VMs eat 366 GB of bodily disk as a substitute of three.1 TB — an 88% discount — and disk provisioning time drops from 30 seconds to 0.8 seconds per VM, a 37× speedup. Every VM nonetheless sees its full 24 GB logical disk with near-native CPU efficiency.
Sturdy Container Pool with Multi-Layer Fault Restoration
OSGym maintains a pre-warmed runner pool — by default, 128 runners per executor node — initialized earlier than coaching begins. Moderately than creating and destroying VMs on demand, runners are recycled between duties. Earlier than every VM creation, OSGym reads /proc/meminfo and /proc/loadavg to confirm the host can safely accommodate one other occasion, blocking creation if accessible reminiscence falls beneath 10% or below 8 GB absolute. Every container is memory-limited to six GB to forestall over-provisioning below burst situations.
The system additionally tunes Linux kernel parameters that might in any other case trigger silent failures at excessive concurrency — for instance, fs.aio-max-nr is raised from 65,536 to 1,048,576, and fs.inotify.max_user_instances from 128 to eight,192. Fault restoration operates at two ranges: on the step stage, every motion will get as much as 10 retries by default; on the activity stage, if a runner fails completely, the duty is mechanically reassigned to a recent runner.
Unified Activity Move and Centralized Knowledge Server
Two design parts which can be notably necessary for devs integrating OSGym: each activity follows a four-phase unified execution movement — Configure, Reset, Function, Consider — no matter which software program or area is concerned. This standardization makes it simple so as to add new activity sorts with out altering the encircling infrastructure.
Above the reproduction layer, a centralized knowledge server Python class exposes a single-entry batched interface (__next__ and async_step) that hides all of the complexity of state supervisor communication and queuing. The batched step methodology is asynchronous, which means the coaching loop is rarely blocked whereas ready for OS replicas to finish their actions.
What the Numbers Look Like in Apply
Utilizing 1,024 parallel OS replicas, the system collected trajectories throughout ten activity classes — together with LibreOffice Author, Calc, and Impress, Chrome, ThunderBird, VLC, VS Code, GIMP, OS system configuration, and multi-app workflows — at roughly 1,420 trajectories per minute, versus 115,654 seconds with out parallelization. Your complete dataset price $43 in cloud compute.
The analysis staff then used that knowledge to fine-tune Qwen2.5-VL 32B by way of supervised fine-tuning, adopted by reinforcement studying utilizing a PPO-based semi-online asynchronous pipeline (200 steps, batch measurement 64, studying charge 1e-6). The ensuing mannequin achieved a 56.3% success charge on the OSWorld-Verified benchmark — aggressive with present strategies for a 32B parameter base mannequin with no task-specific tuning.
Key Takeaways
- Coaching laptop use brokers is an infrastructure downside first: Full OS sandboxes with GUIs are far heavier than coding or browser environments — every VM wants ~24 GB of disk, devoted CPU and RAM, and a show stack. With out cautious optimization, scaling to tons of of replicas is solely unaffordable for many tutorial labs.
- RAM is a wiser scaling lever than CPU: OSGym’s hardware-aware orchestration reveals that packing extra replicas per server shifts the bottleneck from CPU to RAM — and RAM is 5–10× cheaper. This single perception cuts per-replica price from ~$2.10/day to as little as $0.23/day.
- Copy-on-write disk administration eliminates the storage wall. Through the use of XFS reflink CoW (
cp --reflink=at all times), OSGym reduces bodily disk consumption by 88% and accelerates VM disk provisioning by 37× — turning a 3.1 TB, 30-second-per-VM downside right into a 366 GB, 0.8-second one. - Decentralized state administration is the important thing to robustness at scale. Giving every OS reproduction its personal devoted state supervisor means failures keep remoted. Even ranging from a completely crashed state, OSGym self-recovers all replicas inside a brief window — crucial for uninterrupted long-running coaching jobs.
- Educational-scale laptop use agent analysis is now financially viable. With 1,024 replicas producing 1,420 trajectories per minute and a full dataset costing simply $43 in cloud compute, OSGym brings the infrastructure price of coaching general-purpose laptop brokers inside attain of college analysis budgets.
Try the Paper right here. Additionally, be at liberty to comply with us on Twitter and don’t neglect to affix our 120k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you may be part of us on telegram as properly.
Must associate with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and many others.? Join with us

