

Writing quick GPU code is likely one of the most grueling specializations in machine studying engineering. Researchers from RightNow AI wish to automate it fully.
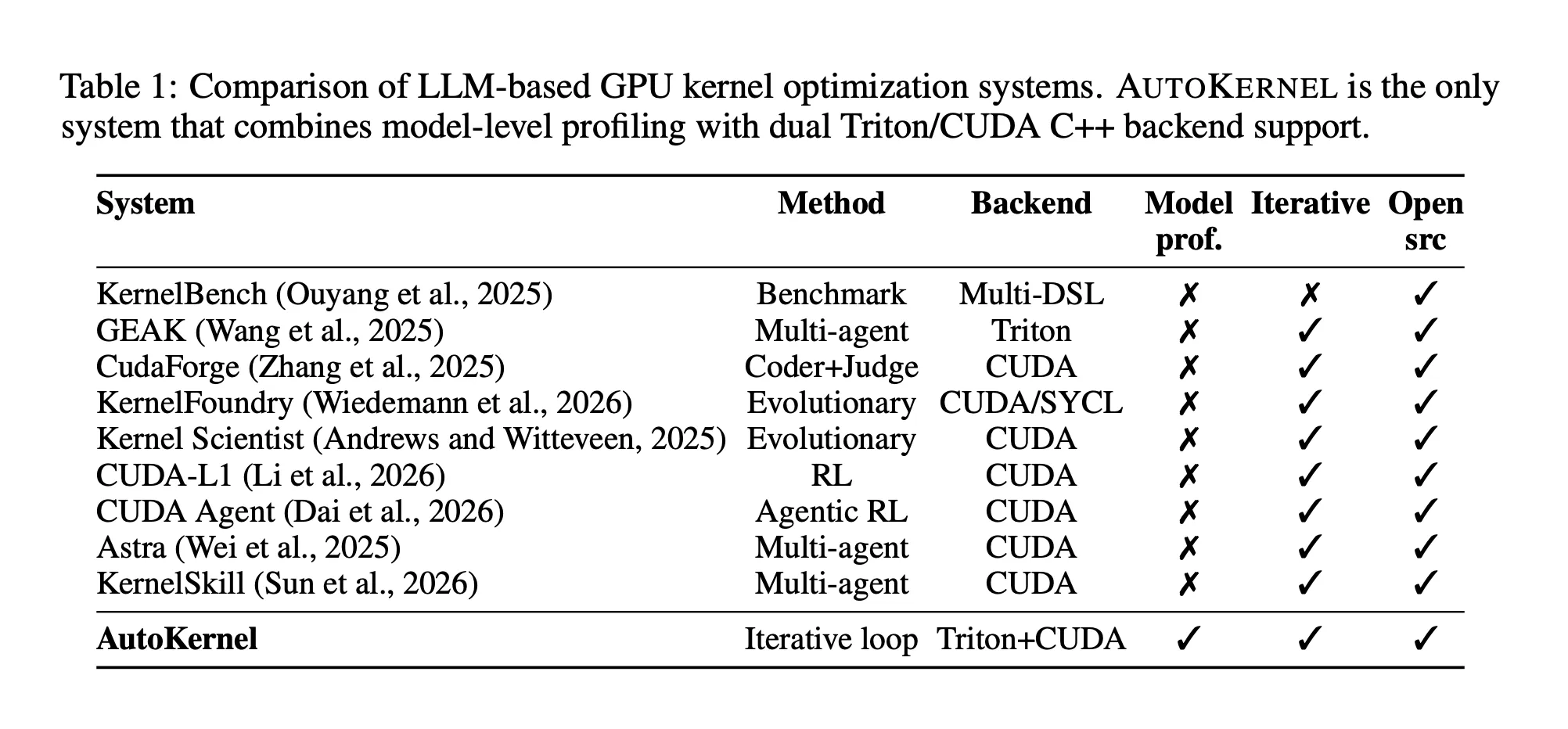
The RightNow AI analysis group has launched AutoKernel, an open-source framework that applies an autonomous LLM agent loop to GPU kernel optimization for arbitrary PyTorch fashions. The method is easy: give it any mannequin earlier than you go to mattress, and get up to sooner Triton kernels — no GPU experience required.

Why GPU Kernels Are So Onerous to Optimize
A GPU kernel is a operate that runs in parallel throughout 1000’s of GPU cores. While you run a transformer mannequin like LLaMA or GPT-2, the majority of compute time is spent inside kernels for operations like matrix multiplication (matmul), softmax, layer normalization, and a spotlight. These kernels reside in libraries like cuBLAS and cuDNN, or get generated routinely by PyTorch’s compilation pipeline.
The issue is that squeezing most efficiency out of those kernels requires reasoning concurrently about arithmetic depth, reminiscence coalescing, register stress, tile sizes, warp-level synchronization, and tensor core instruction choice — a mixture of abilities that takes years to develop. A single high-performance matmul kernel might contain 200+ strains of CUDA or Triton code with dozens of interdependent parameters. This experience is scarce, and the handbook tuning course of scales poorly as mannequin architectures evolve.
The benchmark suite KernelBench, which evaluates frontier LLMs on 250 GPU kernel issues, discovered that even the perfect fashions matched PyTorch baseline efficiency in fewer than 20% of circumstances utilizing one-shot era. AutoKernel was constructed immediately in response to that hole.
The Loop: Edit, Benchmark, Preserve or Revert
AutoKernel’s core perception is that an professional kernel engineer’s workflow is itself a easy loop: write a candidate, benchmark it, maintain enhancements, discard regressions, repeat. The framework mechanizes this loop. An LLM agent modifies a single file — kernel.py — a set benchmark harness verifies correctness and measures throughput, and the consequence determines whether or not the change persists. Crucially, each experiment maps to a git commit. Stored experiments advance the department; reverted experiments are erased cleanly with git reset. All the historical past is browsable with normal git instruments, and experiment outcomes are logged to a plain tab-separated outcomes.tsv file — dependency-free, human-readable, and trivially parseable by the agent.
Every iteration takes roughly 90 seconds — 30 seconds for correctness checking, 30 seconds for efficiency benchmarking through Triton’s do_bench, and 30 seconds for agent reasoning and code modification. At roughly 40 experiments per hour, an in a single day 10-hour run yields 300 to 400 experiments throughout a number of kernels.
This design attracts immediately from Andrej Karpathy’s autoresearch challenge, which demonstrated that an AI agent working a maintain/revert loop on LLM coaching code may uncover 20 optimizations throughout 700 experiments in two days on a single GPU. AutoKernel transplants this loop to kernel code, with a unique search area and a correctness-gated benchmark because the analysis operate as a substitute of validation loss.
The agent reads a 909-line instruction doc known as program.md, which encodes professional information right into a six-tier optimization playbook. The tiers progress from block dimension tuning (sweeping tile dimensions by powers of two, adjusting num_warps and num_stages) by reminiscence entry patterns (coalesced hundreds, software program prefetching, L2 swizzling), compute optimizations (TF32 accumulation, epilogue fusion), superior strategies (split-Okay, persistent kernels, Triton autotune, warp specialization), architecture-specific methods (TMA on Hopper, cp.async on Ampere, adjusted sizes for L4/RTX), and at last kernel-specific algorithms like on-line softmax for consideration and Welford’s algorithm for normalization. The instruction doc is deliberately complete so the agent can run 10+ hours with out getting caught.
Profiling First, Optimizing The place It Issues
Not like prior work that treats kernel issues in isolation, AutoKernel begins from an entire PyTorch mannequin. It makes use of torch.profiler with form recording to seize per-kernel GPU time, then ranks optimization targets utilizing Amdahl’s regulation — the mathematical precept that the general speedup you’ll be able to obtain is bounded by how a lot of the entire runtime that part represents. A 1.5× speedup on a kernel consuming 60% of complete runtime yields a 1.25× end-to-end achieve. The identical speedup on a kernel consuming 5% of runtime yields only one.03×.
The profiler detects GPU {hardware} from a database of recognized specs protecting each NVIDIA (H100, A100, L40S, L4, A10, RTX 4090/4080/3090/3080) and AMD (MI300X, MI325X, MI350X, MI355X) accelerators. For unknown GPUs, it estimates peak FP16 throughput from SM rely, clock fee, and compute functionality — making the system usable throughout a wider vary of {hardware} than simply the newest NVIDIA choices.
The orchestrator (orchestrate.py) transitions from one kernel to the subsequent when any of 4 situations are met: 5 consecutive reverts, 90% of GPU peak utilization reached, a two-hour elapsed time funds, or a 2× speedup already achieved on that kernel. This prevents the agent from spending extreme time on kernels with diminishing returns whereas higher-impact targets wait.
5-Stage Correctness Harness
Efficiency with out correctness is ineffective, and AutoKernel is especially thorough on this entrance. Each candidate kernel passes by 5 validation levels earlier than any speedup is recorded. Stage 1 runs a smoke check on a small enter to catch compilation errors and form mismatches in underneath a second. Stage 2 sweeps throughout 8 to 10 enter configurations and three information sorts — FP16, BF16, and FP32 — to catch size-dependent bugs like boundary dealing with and tile the rest logic. Stage 3 checks numerical stability underneath adversarial inputs: for softmax, rows of huge an identical values; for matmul, excessive dynamic vary; for normalization, near-zero variance. Stage 4 verifies determinism by working the identical enter 3 times and requiring bitwise an identical outputs, which catches race situations in parallel reductions and non-deterministic atomics. Stage 5 checks non-power-of-two dimensions like 1023, 4097, and 1537 to reveal masking bugs and tile the rest errors.
Tolerances are dtype-specific: FP16 makes use of atol = 10⁻², BF16 makes use of 2 × 10⁻², and FP32 makes use of 10⁻⁴. Within the paper’s full analysis throughout 34 configurations on an NVIDIA H100, all 34 handed correctness with zero failures throughout keen, compiled, and customized kernel outputs.
Twin Backend: Triton and CUDA C++
AutoKernel helps each Triton and CUDA C++ backends inside the similar framework. Triton is a Python-like domain-specific language that compiles JIT in 1 to five seconds, making it perfect for speedy iteration — the agent can modify block sizes, warp counts, pipeline levels, accumulator precision, and loop construction. Triton routinely reaches 80 to 95% of cuBLAS throughput for matmul. CUDA C++ is included for circumstances requiring direct entry to warp-level primitives, WMMA tensor core directions (utilizing 16×16×16 fragments), vectorized hundreds through float4 and half2, bank-conflict-free shared reminiscence layouts, and double buffering. Each backends expose the identical kernel_fn() interface, so the benchmark infrastructure runs identically no matter backend.
The system covers 9 kernel sorts spanning the dominant operations in fashionable transformer architectures: matmul, flash_attention, fused_mlp, softmax, layernorm, rmsnorm, cross_entropy, rotary_embedding, and scale back. Every has a PyTorch reference implementation in reference.py serving because the correctness oracle, and the benchmark computes throughput in TFLOPS or GB/s alongside roofline utilization in opposition to detected GPU peak.
Benchmark Outcomes on H100
Measured on an NVIDIA H100 80GB HBM3 GPU (132 SMs, compute functionality 9.0, CUDA 12.8) in opposition to PyTorch keen and torch.compile with max-autotune, the outcomes for memory-bound kernels are vital. RMSNorm achieves 5.29× over keen and a pair of.83× over torch.compile on the largest examined dimension, reaching 2,788 GB/s — 83% of H100’s 3,352 GB/s peak bandwidth. Softmax reaches 2,800 GB/s with a 2.82× speedup over keen and three.44× over torch.compile. Cross-entropy achieves 2.21× over keen and a pair of.94× over torch.compile, reaching 2,070 GB/s. The positive factors on these kernels come from fusing multi-operation ATen decompositions into single-pass Triton kernels that reduce HBM (Excessive Bandwidth Reminiscence) visitors.
AutoKernel outperforms torch.compile on 12 of the 16 consultant configurations benchmarked within the paper, regardless of torch.compile with max-autotune working its personal Triton autotuning. TorchInductor’s generic fusion and autotuning doesn’t all the time discover the specialised tiling and discount methods that kernel-specific implementations exploit.
Matmul is notably more durable — PyTorch’s cuBLAS backend is extensively tuned per GPU structure. The Triton starter reaches 278 TFLOPS, effectively under cuBLAS. Nonetheless, on the 2048³ dimension, AutoKernel beats torch.compile by 1.55×, demonstrating that TorchInductor’s matmul autotuning shouldn’t be all the time optimum both. Closing the cuBLAS hole stays the first goal for continued agent iteration.
In group deployment, an AutoKernel-optimized kernel took first place on the vectorsum_v2 B200 leaderboard with a latency of 44.086µs, outperforming the second-place entry at 44.249µs and third place at 46.553µs. A group person additionally reported {that a} single AutoKernel immediate — requiring roughly three minutes of agent interplay — produced a Triton FP4 matrix multiplication kernel that outperforms CUTLASS by 1.63× to 2.15× throughout a number of shapes on H100. CUTLASS represents hand-optimized C++ template code particularly designed for NVIDIA tensor cores, making this consequence notably notable.
Key Takeaways
- AutoKernel turns weeks of professional GPU tuning into an in a single day autonomous course of. By mechanizing the write-benchmark-keep/revert loop that professional kernel engineers already comply with, the system runs 300 to 400 experiments per in a single day session on a single GPU with none human intervention.
- Correctness is non-negotiable earlier than any speedup is recorded. Each candidate kernel should go a five-stage harness protecting smoke checks, form sweeps throughout 10+ configurations, numerical stability underneath adversarial inputs, determinism verification, and non-power-of-two edge circumstances — eliminating the danger of the agent “optimizing” its solution to incorrect outputs.
- Reminiscence-bound kernels see the largest positive factors over each PyTorch keen and torch.compile. On an NVIDIA H100, AutoKernel’s Triton kernels obtain 5.29× over keen on RMSNorm, 2.82× on softmax, and a pair of.21× on cross-entropy — with the positive factors coming from fusing multi-operation ATen decompositions into single-pass kernels that reduce HBM visitors.
- Amdahl’s regulation drives the place the agent spends its time. Relatively than optimizing kernels in isolation, AutoKernel profiles your complete PyTorch mannequin and allocates effort proportionally to every kernel’s share of complete GPU runtime — making certain that enhancements compound on the mannequin stage, not simply the kernel stage.
Take a look at the Paper and Repo. Additionally, be at liberty to comply with us on Twitter and don’t neglect to affix our 120k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be part of us on telegram as effectively.
Must accomplice with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and so on.? Join with us

