

NVIDIA researchers launched ProRL AGENT, a scalable infrastructure designed for reinforcement studying (RL) coaching of multi-turn LLM brokers. By adopting a ‘Rollout-as-a-Service’ philosophy, the system decouples agentic rollout orchestration from the coaching loop. This architectural shift addresses the inherent useful resource conflicts between I/O-intensive setting interactions and GPU-intensive coverage updates that presently bottleneck agent improvement.
The Core Downside: Tight Coupling
Multi-turn agent duties contain interacting with exterior environments, resembling code repositories or working methods, by way of iterative instrument use. Many current frameworks—together with SkyRL, VeRL-Device, Agent Lightning, rLLM, and GEM—embed rollout management straight inside the coaching course of.
This tight coupling results in two major limitations:
- Conflicting System Necessities: Rollouts are I/O-bound, requiring sandbox creation, long-lived instrument classes, and asynchronous coordination. Coaching is GPU-intensive, centered on ahead/backward passes and gradient synchronization. Operating each in a single course of causes interference and reduces {hardware} effectivity.
- Upkeep Obstacles: Embedding rollout logic within the coach makes it troublesome emigrate to totally different coaching backends or assist new runtime environments with out re-implementing the execution pipeline.
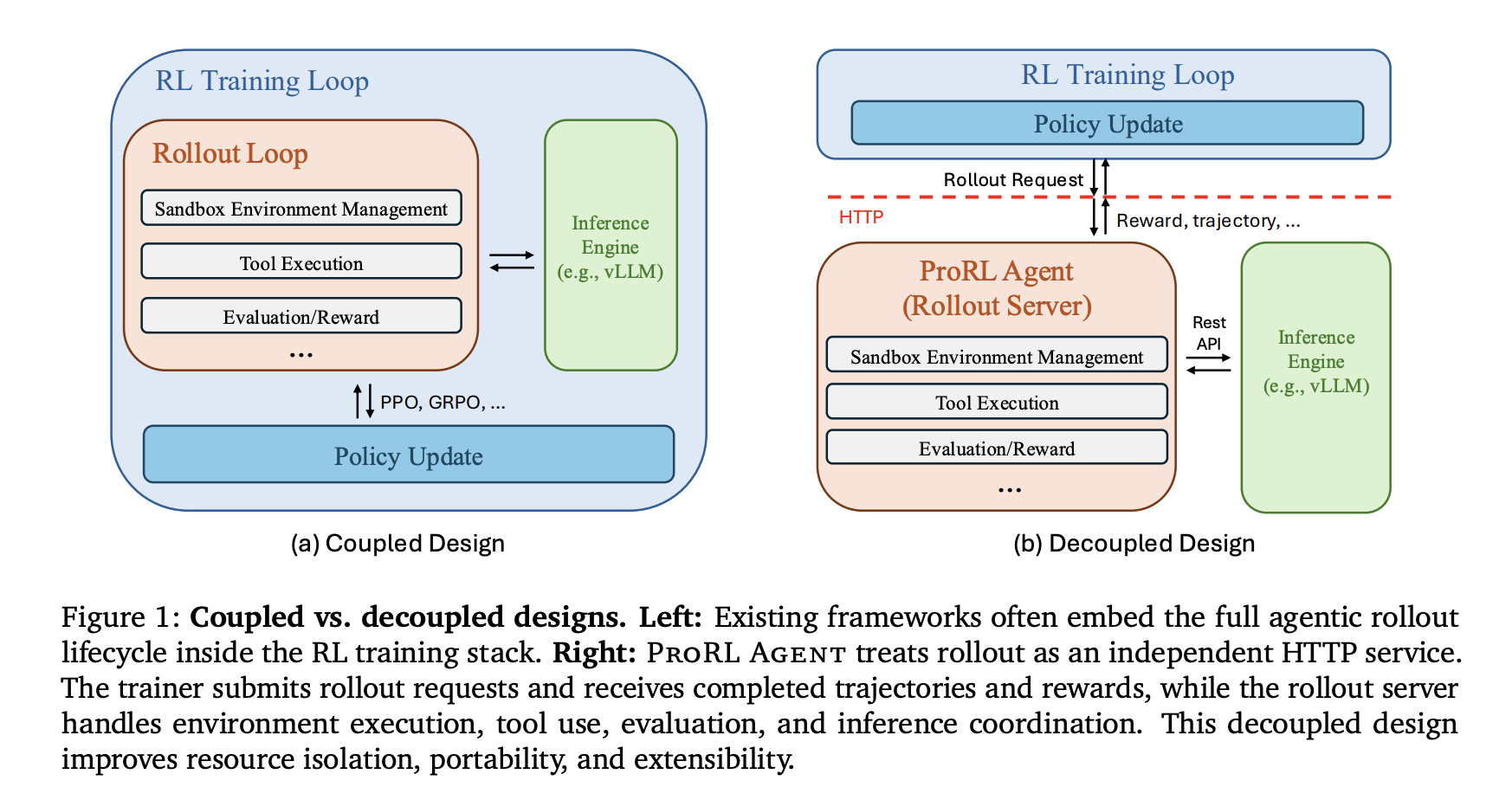
System Design: Rollout-as-a-Service
ProRL AGENT operates as a standalone HTTP service that manages the total rollout lifecycle. The RL coach interacts with the server solely by way of an API, remaining agnostic to the underlying rollout infrastructure.
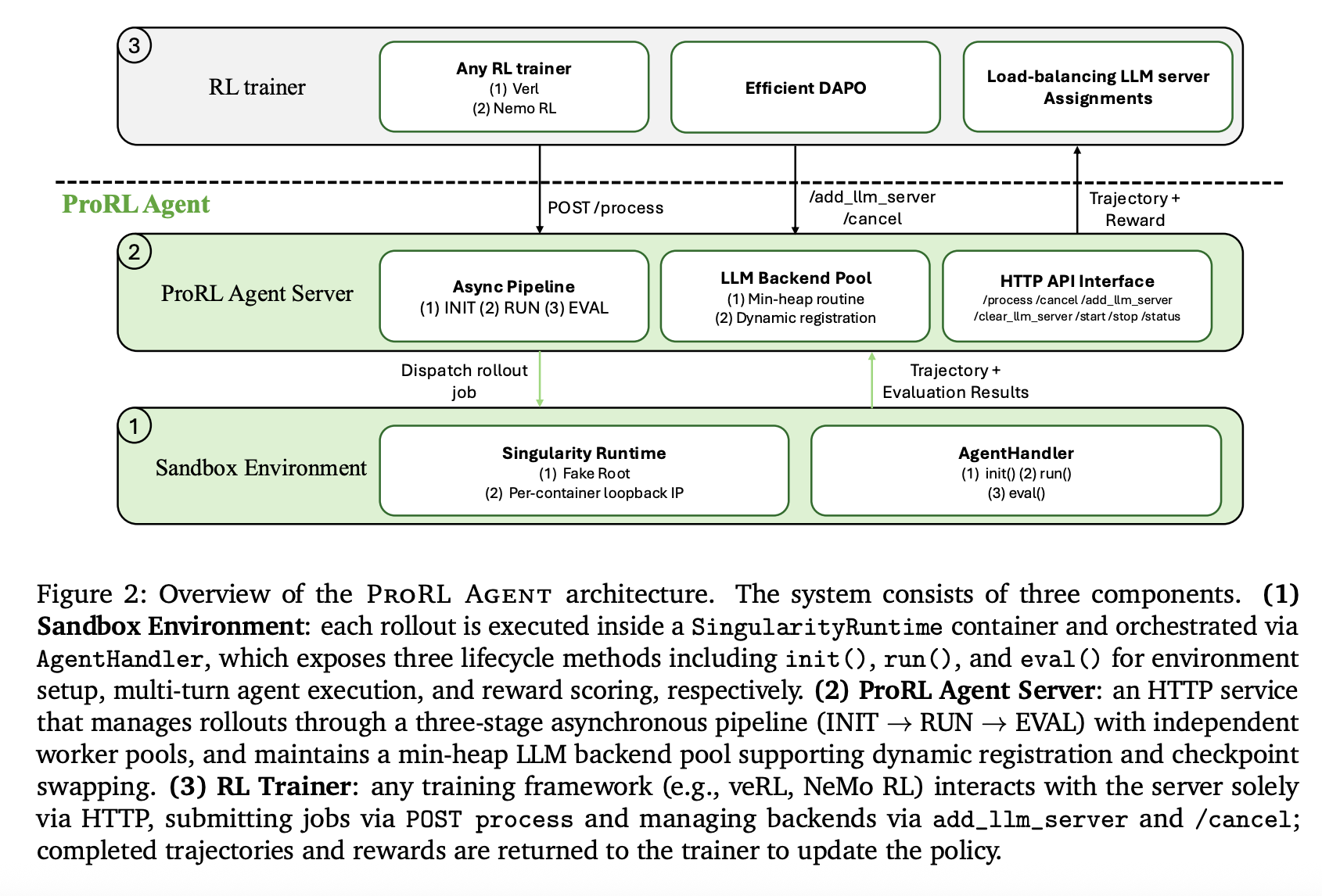
Three-Stage Asynchronous Pipeline
To maximise throughput, the server orchestrates rollouts by way of an asynchronous three-stage ‘meeting line’:
- INIT: Initialization staff spin up sandbox containers and configure instruments.
- RUN: Rollout staff drive the multi-turn agent loop and gather trajectories.
- EVAL: Analysis staff rating outcomes towards floor reality to provide reward indicators.
By assigning every stage to an impartial employee pool, ProRL AGENT permits phases to overlap throughout totally different jobs, stopping sluggish evaluations (resembling full check suite executions) from stalling the rollout course of.
HPC-Appropriate Sandboxing and Optimized Instruments
ProRL AGENT makes use of Singularity for its sandbox infrastructure. Not like Docker-based platforms, Singularity permits rootless execution, which is required for deployment on shared HPC clusters managed by Slurm.
The system consists of a number of optimizations to scale back instrument execution latency, which regularly dominates whole rollout time:
- Environment friendly Bash: Replaces tmux-based terminal multiplexing with a ptyprocess-based direct pseudo-terminal, decreasing shell command latency from 0.78s to 0.42s.
- Direct IPython API: Connects to persistent kernels by way of an in-process API as a substitute of community gateways, eradicating networking overhead.
- Unix Area Sockets (UDS): Replaces TCP loopback for communication between the agent and the execution server contained in the container to shave off further latency.
Superior Options for Scalable RL
The infrastructure introduces mechanisms to enhance coaching stability and {hardware} utilization:
Load Balancing and Prefix Cache Reuse
The server manages a pool of LLM inference backends (e.g., vLLM) utilizing a min-heap keyed by task counts. When a activity is assigned, all subsequent calls inside that activity are routed to the identical backend. This technique maximizes prefix cache reuse, decreasing inference time throughout a number of agent turns.
Token-in/Token-out Communication
To get rid of re-tokenization drift—the place the token sequence generated throughout rollout differs from what’s used throughout coaching—ProRL AGENT makes use of token IDs because the canonical illustration all through your complete course of. Log-probabilities and IDs are propagated unchanged from the inference backend to the coach.
Optimized DAPO Implementation
The system helps Dynamic Sampling Coverage Optimization (DAPO), which filters out ‘non-informative’ prompts that yield uniform rewards. ProRL AGENT makes use of an asynchronous replenishment mechanism to take care of most throughput, terminating redundant energetic jobs early as soon as the goal variety of informative prompts is reached.
Experimental Outcomes on SWE-Bench Verified
The system was validated utilizing Qwen3 fashions throughout a number of scales. ProRL AGENT constantly improved efficiency in comparison with reproduced baselines.
| Mannequin Scale | Reproduced Baseline | ProRL Agent (RL) |
| Qwen3-4B | 14.8 | 21.2 |
| Qwen3-8B | 9.6 | 18.0 |
| Qwen3-14B | 15.4 (reproduced baseline) | 23.6 |
Notice: The reported prior consequence for SkyRL-Agent-14B-v0 was 21.6.
Along with software program engineering, the system demonstrated generality in STEM, Math, and Code domains, exhibiting regular reward progress throughout RL coaching. Scalability checks confirmed that rollout throughput will increase near-linearly as compute nodes are added.
Key Takeaways
- Architectural Decoupling: ProRL Agent treats the total agentic rollout lifecycle—together with setting initialization, instrument execution, and reward scoring—as an impartial HTTP service, separating I/O-intensive duties from GPU-intensive coverage coaching.
- Vital Efficiency Positive aspects: This infrastructure enabled the Qwen3-8B mannequin to almost double its efficiency on the SWE-Bench Verified benchmark (from 9.6% to 18.0%), whereas the Qwen3-14B mannequin improved from 15.4% to 23.6%.
- System Latency Reductions: Focused optimizations, resembling changing tmux with ptyprocess for shell execution, decreased motion latency from 0.78s to 0.42s, contributing to near-linear throughput scaling throughout compute nodes.
- Elimination of Tokenization Drift: The framework makes use of a token-in/token-out communication pipeline, guaranteeing that the precise token IDs generated throughout rollout are handed to the coach with out the chance of lossy re-tokenization.
- HPC-Native Deployment: Through the use of Singularity as a substitute of Docker, ProRL Agent helps rootless execution and native Slurm integration, permitting large-scale agent coaching on shared high-performance computing clusters.
Try the Paper and Repo. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 120k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you may be part of us on telegram as effectively.

